
ViT 개요
의의
- ViT는 Transformer 인코더를 크게 변경하지 않고 이미지 처리에 적용
- 기존: Attention 기법을 사용할 때 CNN과 함께 사용하거나, CNN 구조를 유지하면서 CNN 특정 구성 요소 대체에 사용
- Attention만을 사용한 모델도 있었지만 CNN 기반 모델의 성능을 넘기지 못함 - ViT에서는 Transformer만으로 CNN 기반 모델의 성능을 뛰어넘음


장단점
장점
- 확장성이 좋다.
- Tansformer 구조를 거의 그대로 사용하기 때문
- 기존 Attention 기반 모델은 이론적으로 뛰어나지만, 특성화된 Attention 패턴으로 다른 네트워크에 확장하기 어려웠음 - Large Scale 학습에 우수하다.
- Transformer의 장점을 그대로 흡수 - 전이학습 시에 CNN보다 학습에 적은 연산 리소스를 활용한다.
단점
- Inductive Bias가 부족하다.
- 때문에 학습 시 CNN보다 많은 양의 데이터를 필요로 한다.
Inductive Bias 비교
Inductive Bias
- 모델이 처음 보는 입력에 대한 출력을 예측하기 위해 사용하는 '가정'
CNN의 Inductive Bias
- 다음의 2가지 가정을 통해 CNN이 단순한 MLP보다 좋은 성능을 낸다.
- Translation Equivariance
- Locality
CNN의 가정 1: Translation Equivariance
- 사물의 위치가 바뀌어도 동일 사물로 인식
- CNN에서는 입력값의 위치가 변하면 출력값의 위치도 같이 변하면서 값을 유지한다.
- CNN vs. MLP
- CNN : Translation Equivariance 가정으로 단순 MLP보다 좋은 성능을 가진다.
- MLP : 완전히 같은 값을 가지는 패치의 위치가 조금 달라지더라도 Flatten한 벡터값이 달라지게 됨. Fully Connected 연산 시 weight가 모두 달라지므로 결과값이 달라진다.


CNN의 가정 2: Locality
- 근접 픽셀끼리 종속성
(= 한 픽셀이 주변 픽셀에 대해 높은 종속성을 가진다.) - Convolution 연산을 할 때, 전체 이미지에서 Convolution 필터가 일부분만 보게 된다.
특정 영역만 보고 Convolution 필터가 특징을 추출할 수 있다. - ex) '코'라는 특징은 파란 테두리 내부의 픽셀과 관계가 있다.

Transformer 모델은 Inductive Bias가 없다.
- Attention 구조만 사용한다.
- CNN과 같이 Local Receptive Field(지역 수용 영역)를 보지 않음 - 지역적 패턴을 익히기 위해 CNN 보다 많은 데이터를 필요로 한다.
- 불충분한 데이터양으로 학습하면 일반화 성능이 떨어짐
ex) ImageNet 데이터셋(중간 사이즈 데이터셋)을 학습에 사용할 경우, 유사한 크기의 ResNet(CNN 모델)보다 성능 낮아짐 - Large Scale 데이터셋을 이용하면 CNN보다 좋은 성능을 낸다.
- Large Scale 데이터셋에서 학습하고, 전이학습(Transfer Learning)하면 효과적
- 논문에서 Large Scale 데이터셋 ImageNet 21K, JFT-300M으로 사전 학습 & CIFAR-10으로 Transfoer Learning 했을 때 높은 정확도
ViT 구조
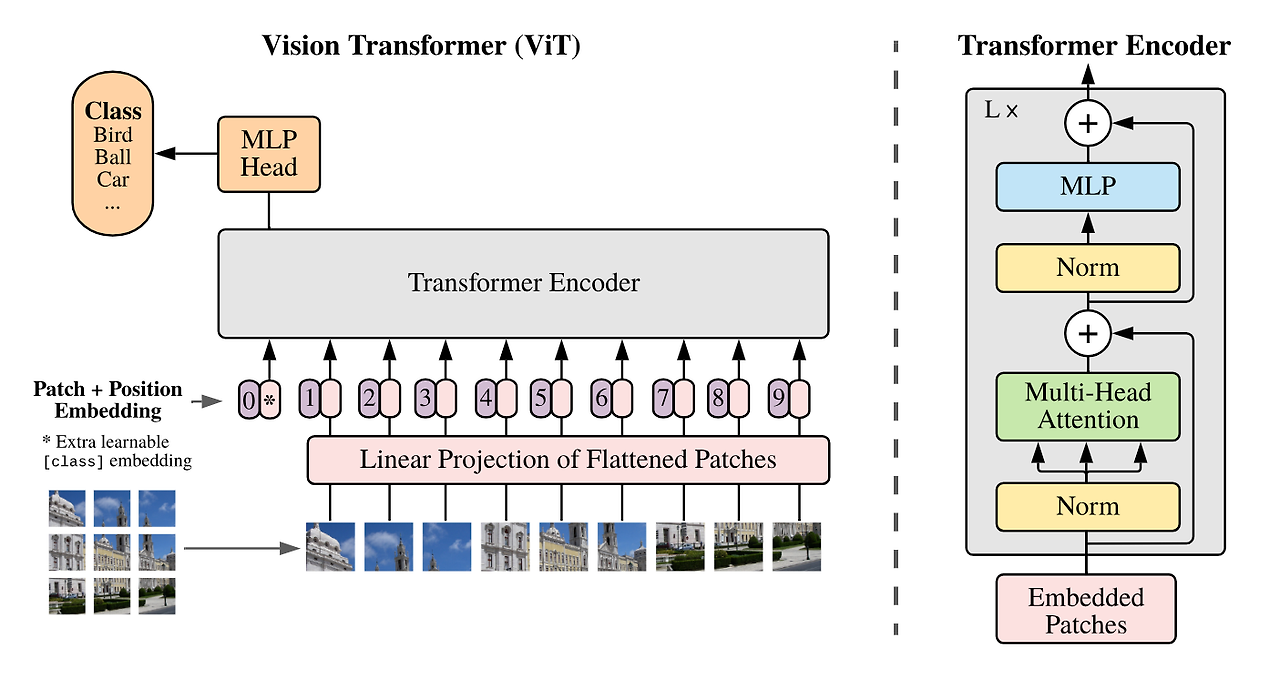
ㄴ[입력부]
Linear Projection of Flattened Patches
특징
- Transformer 구조에 맞는 입력값을 넣어야 함
- Transformer Encoder를 가져와 ViT에 사용했기 때문 - Transformer와 동일하게 시퀀스 데이터에 ① Embedding, ② Positional Encoding 추가
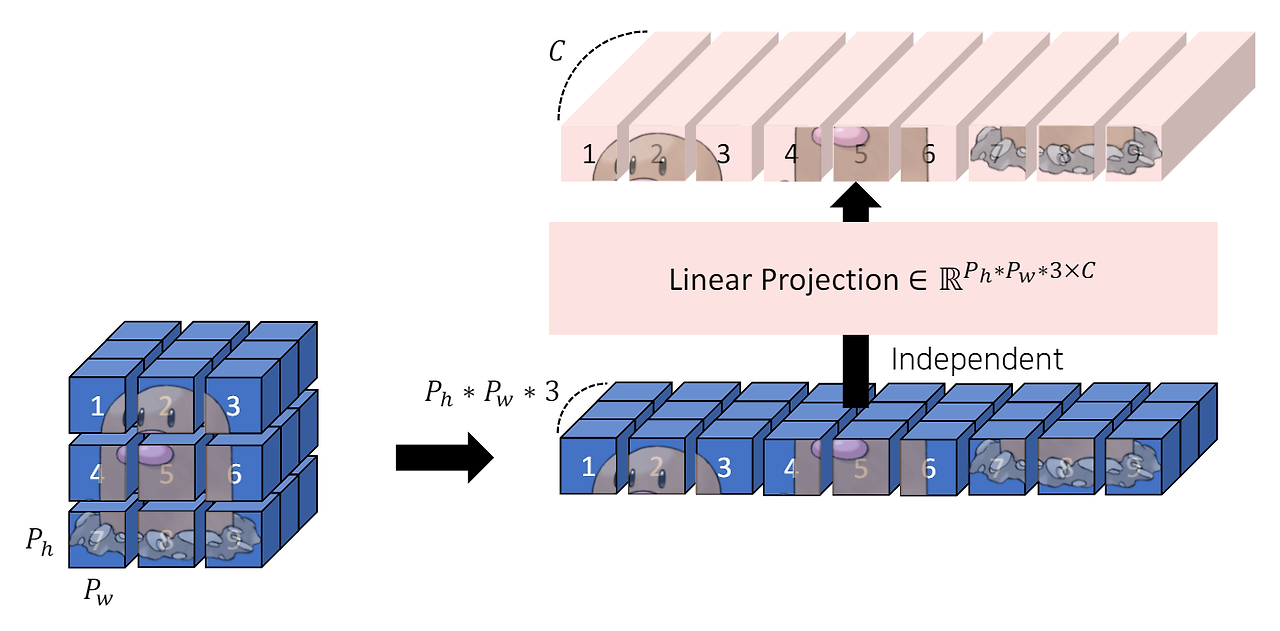
1. 이미지를 패치 단위로 쪼개고 각 패치를 왼쪽 상단에서 오른쪽 하단의 순서로 나열하여 시퀀스 데이터 형태로 만든다.
- 입력 이미지 : (C, H, W) 크기
↓ - 패치 단위로 쪼갬 : (C, P, P) 크기
2. 각 패치는 Flatten하여 벡터로 변환해준다.
- Flatten한 벡터 : C*P*P 크기
- 이 N개의 벡터를 합쳐 xp라고 함 : (N, C*P*P)
ex) 입력 : (3, 256, 256) 크기의 이미지
- P(patch의 크기) = 16 → 각 패치의 크기 (3, 16, 16) & 패치의 개수 (16 x 16)
- 이 패치 flatten : = 768
→ 768 크기의 벡터를 16 X 16개 가지게 됨 - 이 값을 시퀀스 데이터로 나타내면 (256, 768)의 형태로 표현
3. 각 벡터에 Linear 연산을 거쳐서 임베딩한다.
- 임베딩하기 위해 임베딩 행렬 E와 연산 : (C*P*P, D) 크기 * D : Embedding Demension
- xp와 E를 행렬곱 : (N, C*P*P) * (C*P*P, D) = (N, D)의 크기
- 배치 사이즈도 고려 : (B, N, D)

4. 임베딩 결과에 클래스를 예측하는 [CLS] 토큰을 1개 추가한다.
- 토큰이 1개 추가 : (B, N+1, D) 크기
5. [CLS] 토큰이 추가된 값에 동일한 크기의 위치 임베딩을 더해주면 ViT의 입력값이 준비된다.
- 이미지에서도 각 패치의 위치가 중요하므로 위치 임베딩을 적용해야 함
ㄴ[Transformer Encoder]
특징
- Encoder 연산을 L번 반복하기 위해 입력과 출력의 크기를 같게 유지한다.
- ViT와 Transformer의 Encoder는 형태가 조금 다르지만 전반적인 맥락은 동일하다.
- 기존 : Transformer Encoder에서는 Multi-Head Attention 먼저 진행 후, LayerNorm 진행
- ViT : 순서가 바뀌어 있음 - z0을 입력하여 L번 Encoder 연산 후에 zL이 최종적으로 출력된다.
Layer Normalization
특징
- ViT는 Layer Normalization을 수행한다.
= 각 feature에 대해 정규화를 수행한다.
= D차원 방향에 대해 정규화를 수행한다. - NLP Transformer의 Normalization을 그대로 따왔기에, 샘플 단위 Normalization을 적용한 것으로 보인다.
계산 수식


- 위 식에서 r, B는 학습 가능한 파라미터
- 분모에서 +E 부분은 분산이 0에 가까워졌을 경우를 대비한 부분
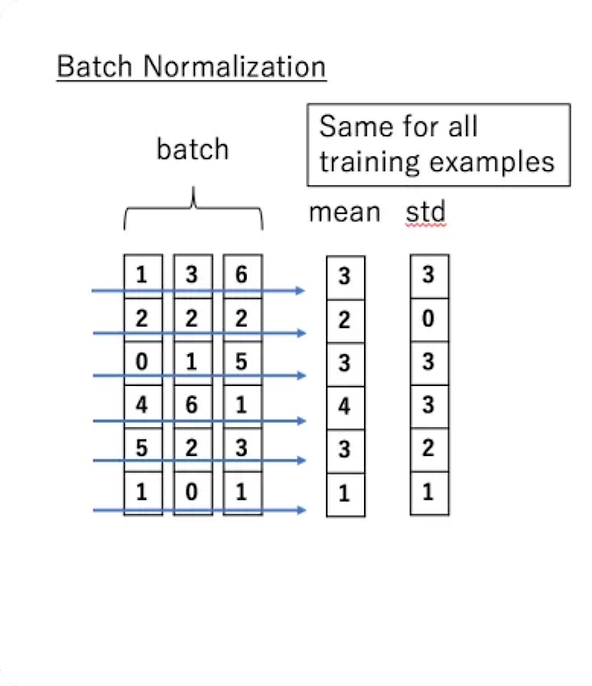
Layer Normalization vs. Batch Normalization
- Layer Normalization
- batch 내부 데이터 크기에 상관없이 '샘플 데이터 단위'로 평균(mean), 분산(std)을 계산하여 Normalization - Batch Normalization
- mini-batch 내부 특징값의 평균(mean), 분산(std) 값으로 Normalization


Multihead self-attention
(복습) Self-attention '요약'

입력 행렬 z에 각 가중치 행렬을 곱한다.
- Q, K, V를 한번에 연산하기 위해 마지막 행의 형태를 사용하기도 한다.
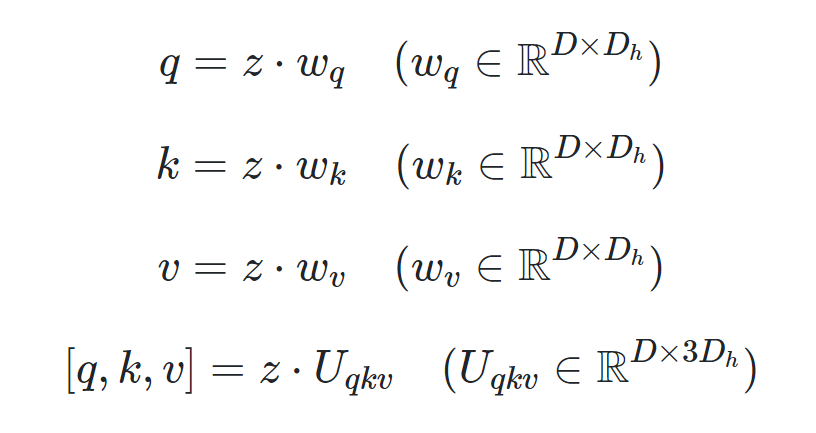
각 head의 수만큼 Self-attention을 수행한다.
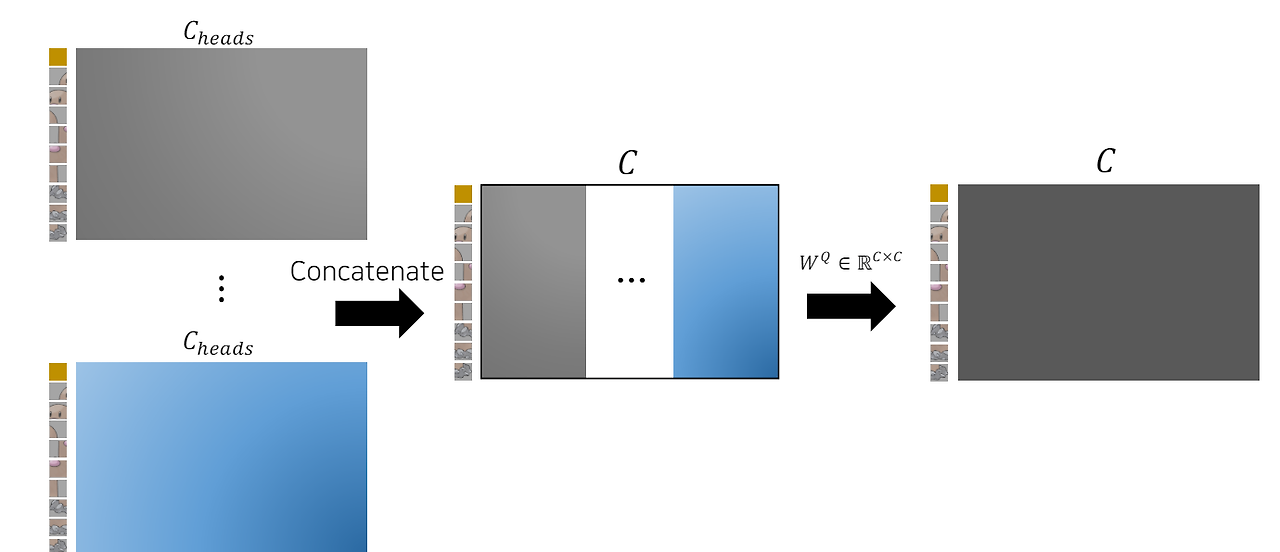
- 각 head에 대해 Q, K 행렬 내적, K벡터 차원의 제곱근으로 나눔, Softmax 함수로 정규화, 어텐션(Z) 행렬 계산
- 각 head의 어텐션 행렬을 모두 연결 : (N+1, D/k, k)의 크기
- 연결된 값에 가중치 행렬을 곱해서 최종적으로 원하는 값 얻음
(Multi-head Attention은 같은 구조에서 head weight만 달라지므로 한번에 묶어서 계산) - (N+1, D/k, k) * (k, D/k, D) = (N+1, D)의 크기
- 입력과 출력이 같은 크기로 유지됨
- Encoder를 여러번 반복하기 위해서

Residual Connection
특징
- 특정 레이어를 건너 뛰어서 입력
- 초기의 모델 수렴 속도가 높아진다
- 입력 데이터와 self-Attention의 결과를 더함
Multi-Layer Perceptron
특징
- 2개의 완전연결 계층(Fully Connected Layer)과 GELU 활성화 함수(Activation)를 적용한다.
GELU(Gaussian Error Linear Unit)함수 특징
- 입력값과 입력값의 누적 정규 분포의 곱을 사용한 형태
- 활성화 함수의 조건을 만족
- 모든 점에서 미분 가능
- 단조 증가 함수 아님 - 장점 : 입력값 x가 다른 입력에 비해 얼마나 큰지에 대한 비율로 값이 조정되므로 확률적 해석 가능



코드 참고
class MLP(nn.Module):
def __init__(self, in_features, hidden_features, out_features, p=0.):
super(MLP, self).__init__()
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = nn.GELU()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(p)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
[MLP Head]
특징
- L번 반복한 Transformer Encoder의 마지막 출력에서 [CLS] 토큰만 분류 문제에 사용
- 마지막에 MLP를 이용하여 클래스 분류
ViT의 학습 & 결과
학습
Vision Transformer의 학습 방식
- large 데이터셋으로 사전학습 & 작은 데이터셋에 대해 fine-tuning 하는 방식
(이미지 resize & MLP 헤드 부분을 클래스 수에 맞게 교체) - 학습을 위해 large 데이터셋 사용 (ImageNet, ImageNet-21k, JFT 사용)
- 전처리는 Resize, RandomCrop, RandomHorizontalFlip (이미지 크기 변경, 자르기, p의 확률로 좌우반전)
- 광범위하게 Dropout 적용 (p, k, v prediction 제외)
- ImageNet, CIFAR10/100, 9-task VTAB 등 데이터셋에 대해 transfer learning 진행
사전 학습 조건
- 사전 학습 조건은 다음과 같습니다.
- Optimizer : ADAM
- 스케줄링 : linear learning rate decay
- weight decay : 0.1 (강한 regularization 사용)
- 배치 사이즈 : 4,096
- Label smoothing 사용 (regularization 사용)
- validation accuracy 기준 early-stopping
전이학습(transfer learning) 조건
- Optimizer : SGD 모멘텀
- 스케줄링 : cosine learning rate decay
- weight decay : 미적용
- grad clipping 적용
- 배치 사이즈 : 512
결과 및 해석
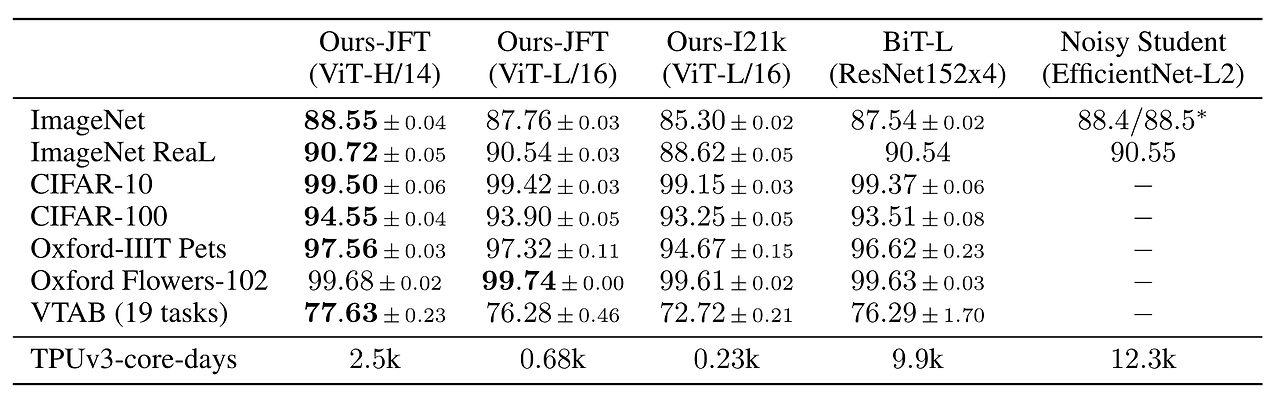
ViT-Base, ViT-Large, ViT-Huge 3가지 모델에 대해 테스트
- CNN 모델에 비해 성능이 좋음
- 학습 시간도 절약한 것을 볼 수 있음
테스크 그룹을 나누어, 유사한 종류의 데이터를 묶어서 성능 비교
- ViT가 가장 좋은 성능을 보이고 있음

그림을 통한 성능 확인

RGB embedding filter 그림
- ViT도 CNN과 같은 형태로 학습됨
- RGB embedding filter : Transformer Encoder에 입력되기 전 Embedding을 할 때 사용한 filter
- 이 필터의 일부분을 시각화하면 CNN의 low level layer에서와 유사한 형태의 결과가 시각화
- CNN처럼 학습이 잘 되었음을 의미
Positional Embedding Similarity 그림
- Positional Embedding이 데이터의 위치를 의미하도록 잘 학습됨
- Positional Embedding에는 패치마다 대응되는 Embedding 벡터 존재
- 모든 패치 p(i., p_i)에 대해 cosine silmilarity를 구했을 때, 각 행 열에 해당하는 부분의 패치가 similarity가 높음
- Position이 의미 있도록 잘 학습됨
atteintion이 관심을 두는 위치의 편차 그림
- low level layer에서는 가까운 곳에서부터 먼 곳까지 모두 살펴봄
- high level layer에서는 전체적인 시각으로 바라봄
- y축 distance : 어떤 query 위치를 기준으로 의미있는 영역가지의 평균 거리
- 이 거리가 짧을수록 가까운 영역에 대해 집중
- 이 거리가 길수록 먼 영역에 대해 집중 - Vision Transformer는 layer가 깊어질수록 점점 더 큰 영역 보게 됨
- CNN의 convolution 연산의 특성과 비슷한 성질
ViT 파생 모델







참고 자료
https://arxiv.org/pdf/2010.11929
https://github.com/google-research/vision_transformer
GitHub - google-research/vision_transformer
Contribute to google-research/vision_transformer development by creating an account on GitHub.
github.com
https://gaussian37.github.io/dl-concept-vit/
Vision Transformer (AN IMAGE IS WORTH 16X16 WORDS, TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE)
gaussian37's blog
gaussian37.github.io
https://jaehoon-daddy.tistory.com/99
[Transformer] ViT 코드 구현
안녕하세요. 이번 포스팅은 ViT 코드 구현을 해보려고 합니다. ViT에 대해서는 Transformer 포스팅에서 살짝 언급했었는데요, ViT는 이제 많은 vision task의 backbone으로 쓰이고 있습니다. [Transformer] Transfo
jaehoon-daddy.tistory.com
https://visionhong.github.io/paper_review/Vision-Transformer/
[논문리뷰] Vision Transformer(ViT)
논문에 대해 자세하게 다루는 글이 많기 때문에 앞으로 논문 리뷰는 모델 구현코드 위주로 작성하려고 한다.
visionhong.github.io
1. 트랜스포머 입문
1.1 트랜스포머 소개 1.2 트랜스포머의 인코더 이해하기 1.3 트랜스포머 디코더 이해하기 1.4 인코더와 디코더 결합 1.5 트랜스포머 학습 트랜스포머(transformer) 자연어 처리에서 주로 사용하는 딥러
kk-yy.tistory.com
https://seongkyun.github.io/study/2019/10/27/cnn_stationarity/
CNN의 stationarity와 locality · Seongkyun Han's blog
위의 이미지와 동일하지만 눈, 코 특징이 사진의 왼쪽 상단에 존재한다는 것만 다르다. 위 이미지와 특징의 위치가 서로 다른데, 사람 몸이라는 동일한 출력값을 내놓기에 역시 translation invariant
seongkyun.github.io
https://standing-o.github.io/posts/vision-transformer/
Vision Transformer (ViT)
Vision Transformer (ViT) 의 기본 원리와 구조 Vision Transformer, ViT, BEIT, CCT, CVT, DeiT, MobileViT, PvT, Swin Transformer, T2T-VIT, Deformable
standing-o.github.io
http://dsba.korea.ac.kr/seminar/?mod=document&uid=1793
[ Paper Review ] Swin Transformer : Hierarchical Vision Transformer using Shifted Windows
1. Topic 다양한 vision 문제에 적용할 수 있는 Swin Transformer 모델을 소개합니다. 2. Overview 1) 텍스트와 다른 이미지의 두 가지 특징인 해상도와 물체의 크기를 고려할 수 있는 모델 구조 제안 Patch Mergi
dsba.korea.ac.kr
'Computer Vision > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (1) | 2024.05.20 |
|---|