


https://arxiv.org/pdf/2304.00685
초록(abstract)
대부분의 시각 인식 연구는 딥 뉴럴 네트워크(DNN) 훈련에서 군중이 라벨링한 데이터에 크게 의존하며, 각각의 시각 인식 작업에 대해 DNN을 훈련시키는 경우가 많아 매우 번거롭고 시간이 많이 소요되는 시각 인식 패러다임을 형성하게 됩니다. 이러한 두 가지 문제를 해결하기 위해, 최근에는 웹 스케일 이미지-텍스트 쌍에서 풍부한 시각-언어 상관관계를 학습하고, 단일 Vision-Language Model(VLM)로 다양한 시각 인식 작업에 대한 제로샷 예측을 가능하게 하는 VLM이 집중적으로 연구되고 있습니다. 본 논문은 다양한 시각 인식 작업을 위한 VLM에 대한 체계적인 리뷰를 제공합니다. 리뷰 내용은 다음과 같습니다:
- 시각 인식 패러다임의 발전을 소개하는 배경
- 널리 채택된 네트워크 아키텍처, 사전 학습 목표 및 다운스트림 작업을 요약하는 VLM의 기초
- VLM 사전 학습 및 평가에서 널리 사용되는 데이터셋
- 기존 VLM 사전 학습 방법, VLM 전이 학습 방법 및 VLM 지식 증류 방법의 리뷰 및 분류
- 리뷰된 방법들의 벤치마킹, 분석 및 논의
- 향후 시각 인식을 위한 VLM 연구에서 탐구될 수 있는 여러 연구 과제 및 잠재적 연구 방향
이 논와 관련된 프로젝트는 여기에서 확인할 수 있습니다.
키워드: 시각 인식, Vision-Language Model, 사전 학습, 전이 학습, 지식 증류, 이미지 분류, 객체 탐지, 의미론적 분할, 딥 뉴럴 네트워크, 딥 러닝, 빅 모델, 빅 데이터
1. 서론 (INTRODUCTION)
시각 인식(예: 이미지 분류, 객체 탐지 및 의미론적 분할)은 컴퓨터 비전 연구에서 오랜 과제이며, 자율 주행 [1], 원격 감지 [2], 로봇 공학 [3] 등 수많은 컴퓨터 비전 응용 프로그램의 초석이기도 합니다. 딥러닝의 등장으로 [4], [5], [6] 시각 인식 연구는 End-to-End 학습 가능한 Deep Neural Networks(DNNs)를 활용하여 큰 성공을 거두었습니다. 그러나 전통적인 기계 학습 [7], [8], [9]에서 딥러닝으로의 전환은 두 가지 새로운 큰 도전 과제를 안겨주었습니다. 첫째, 딥러닝을 처음부터 시작하는 고전적인 설정 하에서 DNN 훈련의 느린 수렴 속도 [4], [5], [6]와, 둘째, DNN 훈련에서 대규모의 작업별로 특화되고 군중이 라벨링한 데이터를 수집하는 데 많은 노동이 필요하다는 점입니다 [10].
End-to-End
End-to-End(엔드투엔드)는 컴퓨터 과학과 공학, 특히 기계 학습과 딥러닝에서 자주 사용되는 개념으로, 시스템의 입력부터 출력까지 전체 과정을 하나의 통합된 시스템으로 처리하는 것을 의미합니다. 이는 중간 단계의 수작업 또는 개별적인 처리 없이, 전체 과정을 자동화된 방식으로 처리하는 것을 목표로 합니다.
End-to-End의 주요 특징
- 통합된 학습: End-to-End 학습에서는 입력 데이터에서 시작하여 최종 출력에 이르는 모든 과정을 하나의 모델이 학습합니다. 예를 들어, 이미지 인식 시스템에서 원시 이미지 데이터를 입력으로 받아 최종적으로 이미지에 대한 라벨을 출력하는 모든 과정을 하나의 신경망이 학습합니다.
- 단순화된 프로세스: 전통적인 방식에서는 여러 단계로 나누어 각각의 단계를 따로 설계하고 최적화해야 했지만, End-to-End 접근법에서는 이러한 단계를 모두 통합하여 단일 모델로 처리합니다. 이로 인해 모델 설계와 학습 과정이 단순화됩니다.
- 자동화: 중간 단계의 수작업 개입을 최소화하고, 전체 프로세스를 자동화할 수 있습니다. 이는 데이터 전처리, 특징 추출, 모델 학습 및 평가 등 모든 단계를 자동으로 수행할 수 있게 합니다.
예시
- 음성 인식: 전통적인 음성 인식 시스템은 음향 모델, 발음 사전, 언어 모델 등 여러 단계를 거쳐 음성을 텍스트로 변환합니다. 그러나 End-to-End 음성 인식 시스템에서는 음성 입력을 받아 직접 텍스트를 출력하는 하나의 통합된 신경망을 사용합니다.
- 기계 번역: 전통적인 기계 번역 시스템은 문장을 단어 단위로 분할하고, 각각의 단어를 번역한 후 문법에 맞게 재조합하는 과정을 거칩니다. 반면에 End-to-End 기계 번역 시스템은 입력 문장을 받아서 직접 출력 문장을 생성합니다.
- 자율 주행: 자율 주행 자동차는 센서 데이터를 받아서 객체 인식, 경로 계획, 차량 제어 등을 개별적으로 처리할 수 있지만, End-to-End 자율 주행 시스템에서는 입력 데이터(예: 카메라 이미지)를 받아서 직접 조향, 가속, 제동 등의 명령을 출력합니다.
End-to-End 접근법은 데이터와 계산 자원이 충분한 경우 매우 강력할 수 있으며, 모델이 모든 단계를 동시에 학습하면서 최적의 성능을 달성할 수 있게 합니다.
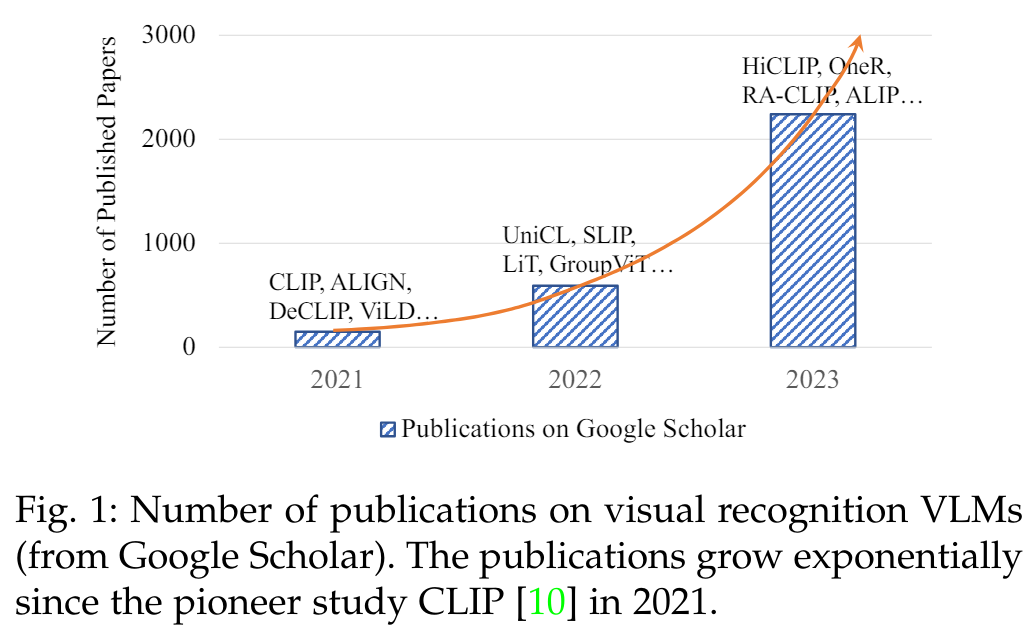
최근, 새로운 학습 패러다임인 사전 학습(Pre-training), 미세 조정(Finetuning), 및 예측(Prediction)이 다양한 시각 인식 작업에서 큰 효과를 입증했습니다 [11], [12], [13]. 이 새로운 패러다임 하에서는, 먼저 DNN 모델을 특정 대규모 학습 데이터(주석이 달린 데이터나 주석이 없는 데이터)로 사전 학습합니다. 그런 다음, 사전 학습된 모델을 작업별로 주석이 달린 학습 데이터로 미세 조정합니다. 이는 그림 2 (a) 및 (b)에 설명되어 있습니다. 사전 학습된 모델에서 학습된 포괄적인 지식을 통해, 이 학습 패러다임은 네트워크 수렴을 가속화하고 다양한 다운스트림 작업에 대해 성능이 좋은 모델을 훈련시킬 수 있습니다.

그럼에도 불구하고, 사전 학습(Pre-training), 미세 조정(Fine-tuning) 및 예측(Prediction) 패러다임은 여전히 각 다운스트림 작업에서 라벨이 있는 학습 데이터를 사용하여 작업별 미세 조정 단계를 추가로 필요로 합니다. 자연어 처리 분야의 발전 [14], [15], [16]에 영감을 받아, 최근에는 Vision-Language Model Pre-training과 Zero-shot Prediction이라는 새로운 딥러닝 패러다임이 많은 주목을 받고 있습니다 [10], [17], [18]. 이 패러다임에서는, Vision-Language Model(VLM)을 인터넷에서 거의 무한히 제공되는 대규모 이미지-텍스트 쌍을 사용하여 사전 학습하며, 사전 학습된 VLM은 미세 조정 없이도 다운스트림 시각 인식 작업에 직접 적용될 수 있습니다. 이는 그림 2 (c)에 설명되어 있습니다. VLM 사전 학습은 일반적으로 특정 Vision-Language 목표에 의해 가이드됩니다 [10], [18], [19]. 이러한 목표는 대규모 이미지-텍스트 쌍 [20], [21]에서 이미지-텍스트 상관관계를 학습할 수 있게 합니다. 예를 들어, CLIP [10]은 이미지-텍스트 대비 목표를 사용하여 쌍을 이루는 이미지와 텍스트를 임베딩 공간에서 가깝게 하고 다른 것들은 멀리 두도록 학습합니다. 이렇게 함으로써, 사전 학습된 VLM은 풍부한 시각-언어 상관관계 지식을 습득하고, 주어진 이미지와 텍스트의 임베딩을 매칭하여 제로샷 예측을 수행할 수 있습니다. 이 새로운 학습 패러다임은 웹 데이터를 효과적으로 활용하고, 작업별 미세 조정 없이 제로샷 예측을 가능하게 하여 간단하게 구현할 수 있으면서도 매우 뛰어난 성능을 발휘합니다. 예를 들어, 사전 학습된 CLIP은 클래식 이미지 분류 [22], [23], [24], [25], [26]부터 인간 행동 인식 및 광학 문자 인식 [10], [27], [28], [29], [30]에 이르기까지 36개의 시각 인식 작업에서 뛰어난 제로샷 성능을 달성했습니다.
다운스트림
다운스트림(downstream)은 컴퓨터 과학, 특히 기계 학습 및 딥러닝 분야에서 자주 사용되는 용어로, 기본 모델이나 시스템이 초기 단계에서 처리된 데이터를 가지고 후속 작업을 수행하는 과정이나 단계들을 의미합니다.
좀 더 구체적으로 설명하자면:
- 다운스트림 작업(downstream task): 사전 학습된 모델을 사용하여 해결하고자 하는 특정 작업입니다. 예를 들어, 이미지 분류, 객체 탐지, 의미론적 분할 등입니다. 이러한 작업들은 모델이 사전 학습(Pre-training)을 통해 습득한 지식을 바탕으로 수행됩니다.
- 사전 학습(Pre-training): 대규모 데이터셋을 사용하여 모델의 초기 학습을 수행하는 단계입니다. 이 단계에서는 모델이 다양한 일반적 패턴과 지식을 학습합니다.
- 미세 조정(Fine-tuning): 다운스트림 작업에 맞게 사전 학습된 모델을 추가로 학습시키는 단계입니다. 이 단계에서는 다운스트림 작업에 특화된 데이터를 사용하여 모델의 성능을 최적화합니다.
다운스트림 작업은 보통 사전 학습된 모델을 실제 응용 프로그램이나 특정 문제 해결에 적용하는 마지막 단계에 해당합니다.
패러다임
패러다임(paradigm)은 특정 분야에서 문제를 이해하고 해결하는 데 사용되는 전형적인 패턴이나 모델을 의미합니다. 이 용어는 주로 과학, 철학, 사회과학 등에서 사용되며, 어떤 분야에서 일반적으로 수용되는 이론, 방법론, 규범 등을 포함합니다.
논문에서 패러다임(paradigm)은 다음과 같은 의미로 사용됩니다:
- 기존 학습 패러다임: 전통적인 딥러닝 접근 방식인 사전 학습(Pre-training), 미세 조정(Fine-tuning), 예측(Prediction)의 순서를 따르는 학습 모델입니다. 이 패러다임은 기본적으로 대규모 데이터를 사용하여 모델을 사전 학습한 후, 각 다운스트림 작업에 대해 별도의 라벨이 있는 데이터를 사용하여 모델을 미세 조정하는 단계로 구성됩니다.
- 새로운 학습 패러다임: Vision-Language Model Pre-training과 Zero-shot Prediction의 새로운 접근 방식입니다. 이 패러다임에서는 대규모 이미지-텍스트 쌍을 사용하여 모델을 사전 학습하고, 사전 학습된 모델을 특정 작업에 대해 추가로 미세 조정할 필요 없이 바로 적용하여 제로샷 예측을 수행합니다.
즉, 패러다임은 특정 문제를 해결하기 위해 채택된 일련의 방법론적 접근 방식이나 절차를 의미하며, 여기서는 딥러닝 모델의 학습 및 적용 방법에 대한 새로운 전형적인 모델이나 방법론을 나타냅니다.
Zero-shot Prediction(제로샷 예측)
Zero-shot Prediction(제로샷 예측)은 기계 학습 및 딥러닝 분야에서, 모델이 학습 단계에서 한 번도 보지 못한 새로운 클래스를 인식하고 예측할 수 있는 능력을 의미합니다. 이는 모델이 학습되지 않은 새로운 작업이나 클래스에 대해 정확한 예측을 할 수 있는 기술입니다.
Zero-shot Prediction의 주요 개념
- 사전 학습된 지식: Zero-shot Prediction은 모델이 방대한 데이터셋으로 사전 학습되었기 때문에 가능해집니다. 모델은 이미지, 텍스트 등 다양한 데이터로부터 풍부한 패턴과 개념을 학습하게 됩니다.
- 임베딩 공간: 모델은 이미지와 텍스트를 동일한 임베딩 공간으로 매핑합니다. 이를 통해, 모델은 서로 다른 데이터 유형 간의 상관관계를 이해할 수 있습니다. 예를 들어, 특정 이미지와 그 이미지에 해당하는 텍스트 설명이 동일한 임베딩 공간에서 가깝게 위치하게 됩니다.
- 언어적 설명 활용: 새로운 클래스는 텍스트로 설명될 수 있습니다. 예를 들어, '얼룩말'이라는 새로운 클래스를 모델이 본 적이 없다면, '흰색과 검은색 줄무늬를 가진 말과 같은 동물'이라는 설명을 통해 모델은 이 새로운 클래스를 이해하고 예측할 수 있습니다.
Zero-shot Prediction의 작동 방식
- 사전 학습(Pre-training): 모델은 대규모의 이미지-텍스트 쌍 데이터로 사전 학습됩니다. 이 과정에서 모델은 이미지와 텍스트 간의 관계를 학습하게 됩니다.
- 임베딩 생성: 모델은 입력된 이미지와 텍스트를 임베딩 공간으로 매핑합니다. 예를 들어, CLIP 모델은 이미지와 텍스트를 동일한 임베딩 공간에 배치하여, 연관된 이미지와 텍스트가 가까이 위치하도록 학습합니다.
- 제로샷 예측: 새로운 클래스에 대한 텍스트 설명을 입력으로 주어지면, 모델은 이 설명을 임베딩 공간으로 변환합니다. 그런 다음, 주어진 이미지의 임베딩과 비교하여 가장 가까운 텍스트 설명을 찾아 새로운 클래스를 예측합니다.
예시
- 이미지 분류: 모델이 '펭귄'이라는 클래스를 본 적이 없더라도, '남극에 사는 흑백의 새'라는 텍스트 설명을 통해 펭귄 이미지를 정확히 분류할 수 있습니다.
- 객체 탐지: 모델은 '공원에서 흔히 볼 수 있는 나무처럼 생긴 큰 구조물'이라는 설명을 통해 새로운 종류의 나무를 인식할 수 있습니다.
- 자율 주행: 모델이 특정 교통 표지판을 학습한 적이 없더라도, '빨간색 원 안에 있는 흰색 삼각형'이라는 설명을 통해 해당 표지판을 인식하고 반응할 수 있습니다.
Zero-shot Prediction은 모델이 학습되지 않은 새로운 상황에서도 유연하게 대응할 수 있게 하여, 다양한 실제 응용에서 매우 유용합니다.
Vision-Language Model(VLM) Pre-training과 Zero-shot Prediction의 큰 성공 이후, 두 가지 연구 분야가 다양한 VLM 사전 학습 연구를 넘어 집중적으로 조사되었습니다.
- 첫 번째 연구 분야는 전이 학습(Transfer Learning)을 통한 VLM 탐구입니다 [31], [32], [33], [34]. 이는 프롬프트 튜닝(prompt tuning) [31], [32], 시각 적응(visual adaptation) [33], [34] 등 여러 전이 접근 방식을 통해 입증되었으며, 모두 사전 학습된 VLM을 다양한 다운스트림 작업에 효과적으로 적응시키는 것을 목표로 합니다.
- 두 번째 연구 분야는 지식 증류(Knowledge Distillation)를 통한 VLM 탐구입니다 [35], [36], [37]. 몇몇 연구 [35], [36], [37]는 VLM에서 다운스트림 작업으로 지식을 증류하여 객체 탐지, 의미론적 분할 등에서 더 나은 성능을 목표로 합니다.
프롬프트 튜닝(prompt tuning)
Prompt tuning은 자연어 처리(NLP)와 Vision-Language Model(VLM) 분야에서 주로 사용되는 기법으로, 미세 조정(fine-tuning) 대신 특정 작업에 맞게 프롬프트(prompt)를 조정하여 모델의 성능을 향상시키는 방법입니다. 이 접근법은 특히 사전 학습된 대규모 언어 모델을 활용할 때 유용합니다.
Prompt Tuning의 주요 개념
- 프롬프트의 정의: 프롬프트는 모델에 입력으로 주어지는 텍스트의 맥락을 제공합니다. 예를 들어, "이 문장의 감정을 분석하세요: [문장]"과 같은 프롬프트가 있을 수 있습니다. 이 프롬프트는 모델이 주어진 작업을 이해하고 수행하는 데 도움이 됩니다.
- 프롬프트 조정: 프롬프트 튜닝에서는 모델 자체를 변경하거나 훈련시키기보다는, 주어진 작업에 맞게 프롬프트를 조정합니다. 이 방법은 모델이 사전 학습된 지식을 최대한 활용하면서도 특정 작업에 적합하도록 합니다.
- 적응성: 프롬프트 튜닝은 다양한 작업에 쉽게 적응할 수 있습니다. 예를 들어, 텍스트 분류, 텍스트 생성, 시각 인식 등 다양한 작업에서 사용될 수 있습니다.
예시
- 텍스트 분류: 모델이 사전 학습된 상태에서, "이 문장의 감정은 무엇입니까? 긍정적, 부정적, 중립적 중에서 선택하세요: [문장]"과 같은 프롬프트를 사용하여 특정 문장의 감정을 분류하도록 조정할 수 있습니다.
- 텍스트 생성: "다음 문장을 완성하세요: [문장의 시작 부분]"과 같은 프롬프트를 사용하여 모델이 문장을 이어서 생성하도록 할 수 있습니다.
- 시각 인식: Vision-Language 모델에서는 "이 이미지에 대해 설명하세요: [이미지]"와 같은 프롬프트를 사용하여 이미지에 대한 설명을 생성하도록 할 수 있습니다.
장점
- 효율성: 모델 자체를 다시 훈련시키는 것보다 프롬프트를 조정하는 것이 훨씬 빠르고 비용 효율적입니다.
- 유연성: 다양한 작업에 쉽게 적용할 수 있습니다.
- 사전 학습된 지식 활용: 모델의 사전 학습된 지식을 최대한 활용할 수 있습니다.
결론
Prompt tuning은 사전 학습된 대규모 모델을 다양한 다운스트림 작업에 맞게 효과적으로 활용하는 방법으로, 모델의 성능을 향상시키면서도 훈련 비용을 절감할 수 있는 효율적인 기법입니다.
시각 적응(visual adaptation)
시각 적응(Visual Adaptation)
시각 적응(Visual Adaptation)은 주로 Vision-Language Model(VLM)이나 딥러닝 모델에서 사전 학습된 모델을 특정 시각 인식 작업에 맞게 조정하는 과정입니다. 이 기법은 사전 학습된 모델이 다양한 다운스트림 시각 작업(예: 이미지 분류, 객체 탐지, 의미론적 분할 등)에서 더 좋은 성능을 발휘하도록 도와줍니다.
주요 개념
- 사전 학습된 모델: 모델은 먼저 대규모의 이미지-텍스트 쌍을 사용하여 사전 학습됩니다. 이 과정에서 모델은 일반적인 시각-언어 상관관계와 패턴을 학습합니다.
- 작업별 적응: 사전 학습된 모델을 특정 시각 인식 작업에 맞게 적응시키는 과정입니다. 이를 통해 모델은 특정 작업에서 더 나은 성능을 발휘할 수 있습니다.
- 전이 학습(Transfer Learning): 시각 적응은 전이 학습의 한 형태로 볼 수 있습니다. 모델이 사전 학습된 지식을 바탕으로 새로운 작업에 적응하여 학습하는 것입니다.
시각 적응의 방법
- 미세 조정(Fine-tuning): 사전 학습된 모델을 특정 작업에 맞게 추가 학습시키는 과정입니다. 예를 들어, 이미지 분류를 위한 모델을 객체 탐지 작업에 맞게 미세 조정할 수 있습니다.
- 프롬프트 튜닝(Prompt Tuning): 프롬프트 튜닝과 유사하게, 특정 시각 작업에 맞는 입력 형식을 조정하여 모델의 성능을 향상시킵니다.
- 데이터 확장(Data Augmentation): 다양한 시각 작업에 맞게 데이터셋을 확장하여 모델이 더 다양한 시각 패턴을 학습하도록 합니다.
예시
- 이미지 분류: 사전 학습된 Vision-Language 모델을 특정 이미지 분류 작업에 맞게 미세 조정하여, 특정 클래스의 이미지를 더 정확하게 분류할 수 있도록 합니다.
- 객체 탐지: 모델이 사전 학습된 일반적인 시각-언어 상관관계를 바탕으로, 특정 객체 탐지 작업에 맞게 적응하여 더 정확한 객체 탐지를 수행할 수 있습니다.
- 의미론적 분할: 사전 학습된 모델을 특정 의미론적 분할 작업에 맞게 조정하여, 이미지 내에서 객체를 더 정확하게 분할할 수 있도록 합니다.
장점
- 효율성: 사전 학습된 모델을 재사용함으로써 학습 비용과 시간을 절감할 수 있습니다.
- 유연성: 다양한 시각 인식 작업에 쉽게 적용할 수 있습니다.
- 성능 향상: 작업별로 모델을 적응시킴으로써 성능을 향상시킬 수 있습니다.
결론
시각 적응(Visual Adaptation)은 사전 학습된 Vision-Language 모델을 다양한 시각 인식 작업에 맞게 조정하여 더 나은 성능을 발휘하도록 하는 중요한 기법입니다. 이를 통해 모델의 효율성과 유연성을 높이고, 다양한 응용 분야에서 뛰어난 성능을 달성할 수 있습니다.
지식 증류(Knowledge Distillation)
지식 증류(Knowledge Distillation)
지식 증류(Knowledge Distillation)는 딥러닝 및 기계 학습에서 사용되는 기술로, 크고 복잡한 모델(teacher model)에서 작은 모델(student model)로 지식을 전이하여 작은 모델이 더 효율적으로 학습하고 예측할 수 있도록 하는 방법입니다. 이 기법은 원래 Hinton 등(2015)에 의해 소개되었습니다.
주요 개념
- Teacher Model: 크고 복잡한 사전 학습된 모델로, 많은 파라미터를 가지고 있으며 높은 성능을 발휘하지만 계산 비용이 많이 듭니다.
- Student Model: 크기가 작고 경량화된 모델로, 빠르고 효율적으로 예측을 수행할 수 있도록 설계되었습니다. 그러나 단독 학습 시 성능이 낮을 수 있습니다.
- Logits: Teacher Model의 출력 값으로, 각 클래스에 대한 예측 확률을 나타냅니다. 이 값들을 사용하여 Student Model을 학습시킵니다.
지식 증류의 과정
- Teacher Model 학습: 먼저, Teacher Model을 대규모 데이터셋으로 학습시킵니다. 이 모델은 높은 성능을 가지고 있으며, 다양한 패턴과 지식을 습득합니다.
- Logits 추출: Teacher Model의 학습이 완료된 후, 주어진 입력 데이터에 대해 Teacher Model의 logits을 추출합니다. logits은 각 클래스에 대한 예측 확률을 포함합니다.
- Student Model 학습: Student Model은 두 가지 손실 함수를 사용하여 학습됩니다. 하나는 Teacher Model의 logits을 모방하기 위한 손실 함수이고, 다른 하나는 실제 라벨에 대한 전통적인 교차 엔트로피 손실 함수입니다. 이렇게 함으로써 Student Model은 Teacher Model의 지식을 효과적으로 전이받습니다.
예시
- 이미지 분류: 대형 Convolutional Neural Network(CNN) 모델을 Teacher Model로 사용하여 높은 정확도를 달성한 후, 이 모델의 지식을 소형 CNN 모델에 증류하여 모바일 장치에서도 효율적으로 동작할 수 있도록 합니다.
- 자연어 처리: 대형 Transformer 모델을 Teacher Model로 사용하여 언어 이해 작업을 수행한 후, 이 지식을 소형 Transformer 모델에 증류하여 성능을 유지하면서도 연산 효율을 높입니다.
장점
- 모델 경량화: 작은 모델(Student Model)이 큰 모델(Teacher Model)의 성능을 상당 부분 유지하면서도 계산 비용과 메모리 사용량을 줄일 수 있습니다.
- 효율성: 모델이 경량화됨에 따라 실시간 애플리케이션, 모바일 장치 및 임베디드 시스템에서 효율적으로 사용할 수 있습니다.
- 성능 향상: 직접 학습한 작은 모델보다 성능이 향상될 수 있습니다.
결론
지식 증류(Knowledge Distillation)는 대형 모델에서 작은 모델로 지식을 효과적으로 전이하여, 작은 모델이 더 효율적으로 작동할 수 있도록 돕는 강력한 기술입니다. 이를 통해 경량화된 모델에서도 높은 성능을 유지할 수 있으며, 다양한 실제 응용 분야에서 유용하게 사용할 수 있습니다.
최근 많은 논문들이 보여주듯이, VLM에서 방대한 지식을 얻는 것에 대한 연구 커뮤니티의 강한 관심에도 불구하고(그림 1 참조), 기존의 VLM 기반 시각 인식 연구들을 정리하고, 직면한 도전 과제 및 미래 연구 방향을 도울 수 있는 종합적인 설문 조사가 부족한 실정입니다.
우리는 이미지 분류, 객체 탐지, 의미론적 분할 등 다양한 시각 인식 작업에서 VLM 연구를 체계적으로 조사하여 이 격차를 메우고자 합니다. 우리는 배경, 기초, 데이터셋, 기술적 접근 방식, 벤치마킹 및 미래 연구 방향을 포함한 다양한 관점에서 설문 조사를 수행합니다. 이 설문 조사를 통해 현재까지의 성과와 앞으로 이 유망한 연구 방향에서 달성할 수 있는 바를 명확히 파악할 수 있을 것이라고 믿습니다.
본 연구의 주요 기여는 다음 세 가지로 요약할 수 있습니다.
첫째, 이미지 분류, 객체 탐지 및 의미론적 분할을 포함한 시각 인식 작업을 위한 Vision-Language Models(VLMs)에 대한 체계적인 리뷰를 제공합니다. 우리의 지식에 따르면, 이는 시각 인식을 위한 VLM에 대한 최초의 설문 조사로, 기존 연구들을 포괄적으로 요약하고 분류하여 이 유망한 연구 분야의 전반적인 그림을 제시합니다.
둘째, 여러 공개 데이터셋을 활용한 기존 연구들의 포괄적인 벤치마킹과 논의를 포함하여, 시각 인식을 위한 VLM의 최신 진행 상황을 연구합니다.
셋째, 시각 인식을 위한 VLM에서 추구할 수 있는 여러 연구 과제와 잠재적인 연구 방향을 제시합니다.
본 설문의 나머지 부분은 다음과 같이 구성됩니다.
- 2장: 시각 인식의 패러다임 발전과 관련된 여러 설문 조사를 소개합니다.
- 3장: 널리 사용되는 딥 네트워크 아키텍처, 사전 학습 목표, 사전 학습 프레임워크 및 VLM 평가에서의 다운스트림 작업을 포함하여 VLM의 기초를 설명합니다.
- 4장: VLM 사전 학습 및 평가에서 일반적으로 사용되는 데이터셋을 소개합니다.
- 5장: VLM 사전 학습 방법을 리뷰하고 분류합니다.
- 6장 및 7장: 각각 VLM을 위한 전이 학습 및 지식 증류 접근 방식을 체계적으로 리뷰합니다.
- 8장: 여러 널리 채택된 데이터셋에 대해 리뷰된 방법들을 벤치마킹합니다.
- 9장: 시각 인식을 위한 VLM 연구의 여러 유망한 방향을 공유합니다.
2. 배경 (BACKGROUND)
2.1 시각 인식을 위한 학습 패러다임
2.1.1 전통적인 기계 학습과 예측
딥러닝 시대 이전, 시각 인식 연구는 손수 제작된 특징(feature engineering)과 가벼운 학습 모델에 크게 의존했습니다. 이 모델들은 손수 제작된 특징을 미리 정의된 의미적 범주로 분류했습니다. 그러나 이 패러다임은 특정 시각 인식 작업에 효과적인 특징을 만들기 위해 도메인 전문가가 필요하며, 복잡한 작업을 잘 처리하지 못하고 확장성도 떨어집니다.
2.1.2 딥러닝을 처음부터 시작하여 예측
딥러닝의 등장으로, 시각 인식 연구는 End-to-End 학습 가능한 딥 뉴럴 네트워크(DNN)를 활용하여 큰 성공을 거두었습니다. 이는 복잡한 특징 공학을 피하고, 신경망의 아키텍처 설계에 집중하여 효과적인 특징을 학습할 수 있게 했습니다. 예를 들어, ResNet은 스킵 디자인을 통해 매우 깊은 네트워크를 가능하게 하였으며, 대규모의 군중이 라벨링한 데이터를 사용하여 ImageNet 벤치마크에서 전례 없는 성능을 달성했습니다. 그러나 전통적인 기계 학습에서 딥러닝으로의 전환은 두 가지 새로운 큰 도전 과제를 가져왔습니다. 첫째, 딥러닝을 처음부터 시작하는 고전적인 설정 하에서 DNN 훈련의 느린 수렴 속도, 둘째, DNN 훈련에서 대규모, 작업 특화, 그리고 군중이 라벨링한 데이터를 수집하는 데 많은 노동이 필요하다는 점입니다.
2.1.3 지도 학습 사전 학습, 미세 조정 및 예측
라벨이 달린 대규모 데이터셋에서 학습된 특징이 다운스트림 작업에 전이될 수 있다는 발견과 함께, 딥러닝을 처음부터 시작하여 예측하는 패러다임은 점차 지도 학습 사전 학습, 미세 조정 및 예측이라는 새로운 패러다임으로 대체되었습니다. 이 새로운 학습 패러다임은 그림 2 (a)에 설명된 대로, 대규모 라벨이 달린 데이터(예: ImageNet)로 DNN을 사전 학습한 후, 작업별 학습 데이터로 사전 학습된 DNN을 미세 조정합니다. 사전 학습된 DNN이 특정 시각적 지식을 학습했기 때문에, 네트워크 수렴을 가속화하고 제한된 작업별 학습 데이터로도 성능이 좋은 모델을 훈련할 수 있습니다.
2.1.4 비지도 학습 사전 학습, 미세 조정 및 예측
지도 학습 사전 학습, 미세 조정 및 예측 패러다임은 많은 시각 인식 작업에서 최첨단 성능을 달성하지만, 사전 학습 단계에서 대규모 라벨이 달린 데이터가 필요합니다. 이 제약을 완화하기 위해, 비지도 학습 사전 학습, 미세 조정 및 예측이라는 새로운 학습 패러다임이 도입되었습니다. 이 패러다임은 라벨이 없는 데이터로부터 유용하고 전이 가능한 표현을 학습하기 위해 자기 지도 학습(self-supervised learning)을 탐구합니다. 이는 그림 2 (b)에 설명된 바와 같이, 다양한 자기 지도 학습 목표를 사용하여 달성됩니다. 여기에는 패치 간의 관계를 모델링하는 마스크 이미지 모델링(masked image modelling) [41], 훈련 샘플을 대조하여 판별적 특징을 학습하는 대조 학습(contrastive learning) [12] 등이 포함됩니다. 이렇게 자기 지도 방식으로 사전 학습된 모델은 이후 라벨이 있는 작업별 학습 데이터를 사용하여 다운스트림 작업에 미세 조정됩니다. 이 패러다임은 사전 학습에 라벨이 필요하지 않기 때문에 더 많은 학습 데이터를 활용하여 유용하고 전이 가능한 특징을 학습할 수 있으며, 이는 지도 학습 사전 학습과 비교했을 때 더 나은 성능을 발휘할 수 있습니다 [12], [13].
2.1.5 VLM 사전 학습과 제로샷 예측
지도 학습 또는 비지도 학습을 통한 사전 학습과 미세 조정은 네트워크 수렴을 개선하지만, 여전히 라벨이 있는 작업 데이터를 사용한 미세 조정 단계가 필요합니다(그림 2 (a) 및 (b) 참조). 자연어 처리 분야에서 큰 성공을 거둔 것에 영감을 받아, 시각 인식을 위한 Vision-Language Model(VLM) 사전 학습과 제로샷 예측이라는 새로운 딥러닝 패러다임이 제안되었습니다(그림 2 (c) 참조). 인터넷에서 거의 무한히 제공되는 대규모 이미지-텍스트 쌍을 사용하여, VLM은 특정 시각-언어 목표에 따라 사전 학습됩니다. 이를 통해 풍부한 시각-언어 지식을 습득하며, 주어진 이미지와 텍스트의 임베딩을 매칭하여 다운스트림 시각 인식 작업에서 미세 조정 없이 제로샷 예측을 수행할 수 있습니다.
사전 학습과 미세 조정과 비교할 때, 이 새로운 패러다임은 대규모 웹 데이터를 효과적으로 활용하고, 작업별 미세 조정 없이 제로샷 예측을 가능하게 합니다. 대부분의 기존 연구는 VLM을 개선하기 위해 세 가지 관점에서 접근합니다: 1) 대규모 정보가 풍부한 이미지-텍스트 데이터 수집, 2) 빅 데이터로부터 효과적으로 학습할 수 있는 고용량 모델 설계, 3) 효과적인 VLM 학습을 위한 새로운 사전 학습 목표 설계. 본 논문에서는 이 새로운 시각-언어 학습 패러다임에 대한 체계적인 survey를 제공하여, 기존 VLM 연구, 직면한 도전 과제 및 이 유망한 연구 분야의 미래 방향에 대한 명확한 큰 그림을 제공하는 것을 목표로 합니다.
2.2 시각 인식을 위한 VLM의 발전
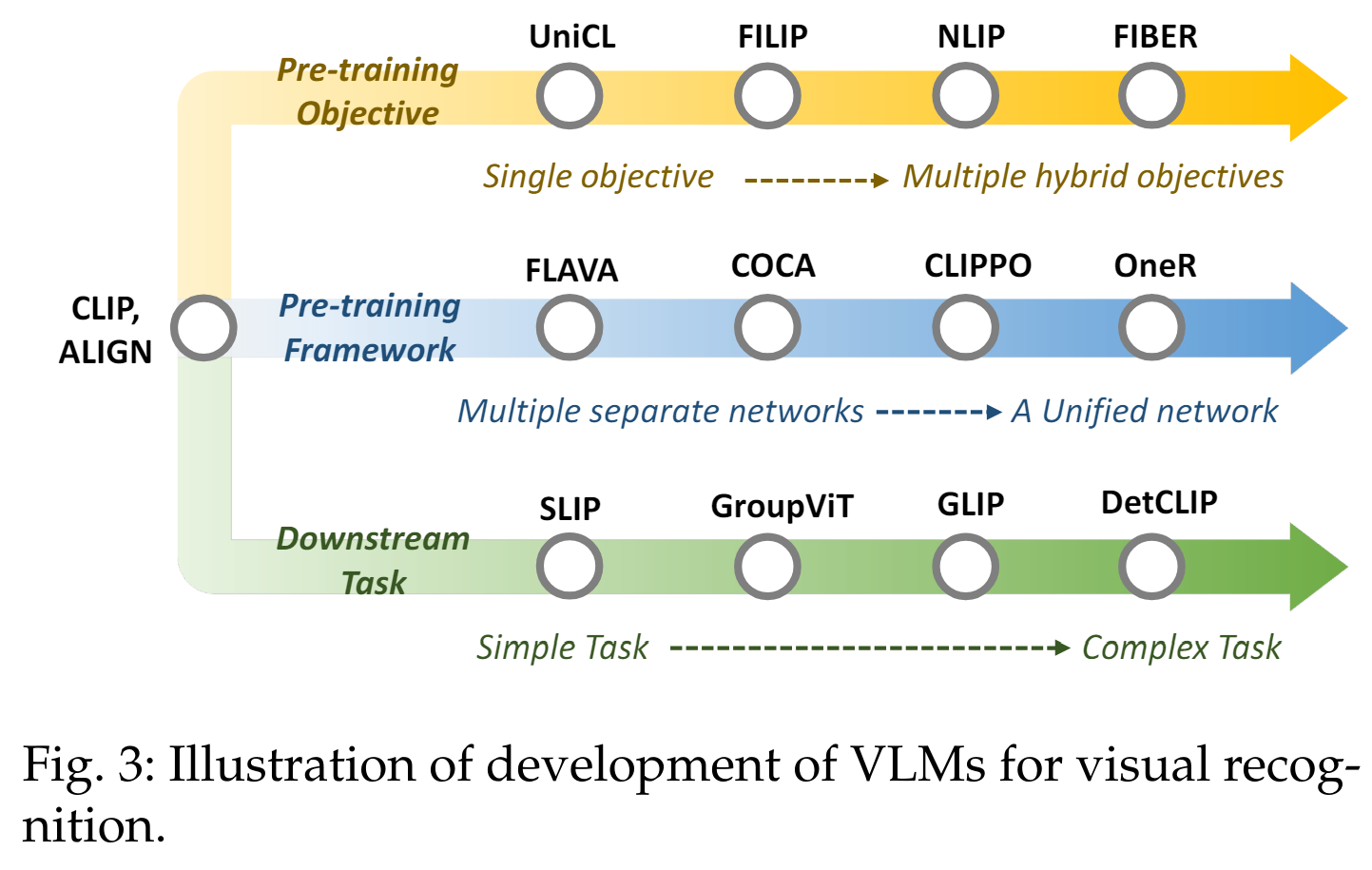
시각 인식 관련 VLM 연구는 CLIP의 개발 이후 큰 진전을 이루었습니다. 우리는 그림 3에 설명된 세 가지 측면에서 시각 인식을 위한 VLM을 소개합니다:
(1) 사전 학습 목표: "단일 목표"에서 "다중 혼합 목표"로
초기 VLM은 일반적으로 단일 사전 학습 목표를 채택했습니다. 예를 들어, CLIP은 이미지와 텍스트를 대조하여 학습하는 단일 대조 목표를 사용했습니다. 그러나 최근의 VLM은 여러 목표를 혼합하여 사용합니다. 이는 대조, 정렬, 생성 목표와 같은 다양한 목표를 결합하여, 모델이 더 강력해지고, 다양한 다운스트림 작업에서 더 좋은 성능을 발휘할 수 있도록 합니다. 이러한 접근 방식은 다양한 목표들이 상호 보완적으로 작용하여 모델의 성능을 향상시키기 때문입니다.
(2) 사전 학습 프레임워크: "다수의 개별 네트워크"에서 "통합된 네트워크"로
초기 VLM은 두 개의 타워로 구성된 사전 학습 프레임워크를 사용했습니다. 예를 들어, 이미지와 텍스트를 각각 별도의 네트워크로 처리한 후, 최종적으로 결합하는 방식입니다. 그러나 이러한 방식은 GPU 메모리 사용량이 많고, 데이터 모달리티 간의 통신이 비효율적일 수 있습니다. 최근의 VLM은 통합된 네트워크 프레임워크를 시도하고 있습니다. 이는 하나의 네트워크가 이미지와 텍스트를 동시에 인코딩하여, 더 적은 메모리 사용량으로 효율적인 통신을 가능하게 합니다.
(3) 다운스트림 작업: 단순한 작업에서 복잡한 작업으로
초기 VLM은 주로 이미지 수준의 시각 인식 작업에 중점을 두었습니다. 예를 들어, 이미지 분류와 같은 단순한 작업입니다. 그러나 최근의 VLM은 보다 범용적으로 복잡한 작업에도 적용할 수 있습니다. 이는 밀집 예측 작업으로, 이미지 내 특정 객체의 위치를 식별하고 구분하는 등의 복잡한 작업을 포함합니다. 이러한 작업은 위치 관련 지식이 필요하며, 모델이 더 정교한 시각적 이해를 필요로 합니다.
설명 추가
설명 추가
- 사전 학습 목표: 단일 목표를 사용하면 특정 작업에 특화된 모델을 만들 수 있지만, 여러 목표를 사용하면 다양한 작업에서 모델의 성능을 향상시킬 수 있습니다. 대조 학습은 모델이 구별 가능한 특징을 학습하도록 돕고, 정렬 목표는 이미지와 텍스트 간의 일치성을 높이며, 생성 목표는 모델이 새로운 데이터를 생성할 수 있도록 합니다.
- 사전 학습 프레임워크: 다수의 개별 네트워크를 사용하는 방식은 병렬 처리의 장점이 있지만, 통합된 네트워크는 데이터 간의 상호작용을 더 효율적으로 처리할 수 있습니다. 이는 특히 대규모 데이터셋을 처리할 때 유리하며, 모델의 학습 속도를 높이고 메모리 사용을 최적화할 수 있습니다.
- 다운스트림 작업: 단순한 이미지 분류 작업에서는 이미지 전체를 하나의 범주로 분류하지만, 복잡한 작업에서는 이미지 내의 각 객체를 개별적으로 인식하고 위치를 파악해야 합니다. 이는 모델이 더 정밀한 예측을 필요로 하며, 복잡한 시각적 정보를 처리할 수 있는 능력을 요구합니다. 예를 들어, 객체 탐지나 의미론적 분할과 같은 작업은 이미지 내의 여러 객체를 구분하고, 각 객체의 경계를 정확히 예측해야 합니다.
2.3 관련 Surveys
반면에, 우리는 세 가지 주요 측면에서 시각 인식 작업을 위한 VLM을 검토합니다:
- 시각 인식 작업을 위한 VLM 사전 학습의 최근 진행 상황,
- VLM에서 시각 인식 작업으로의 두 가지 전형적인 전이 접근 방식,
- 시각 인식 작업에서 VLM 사전 학습 방법의 벤치마킹.
3 VLM 기초
VLM 사전 학습은 [10], [17] 이미지-텍스트 상관관계를 학습하여 시각 인식 작업에서 효과적인 제로샷 예측을 목표로 합니다 [6], [55], [56]. 주어진 이미지-텍스트 쌍 [20], [21]을 사용하여, 먼저 텍스트 인코더와 이미지 인코더를 사용하여 이미지와 텍스트 특징을 추출한 후 [6], [14], [57], [58], 특정 사전 학습 목표를 통해 시각-언어 상관관계를 학습합니다 [10], [17]. 따라서 VLM은 주어진 이미지와 텍스트의 임베딩을 매칭하여 제로샷 방식으로 보지 못한 데이터에서 평가될 수 있습니다 [10], [17]. 이 섹션에서는 이미지와 텍스트 특징을 추출하기 위한 일반적인 네트워크 아키텍처, 시각-언어 상관관계를 모델링하기 위한 사전 학습 목표, VLM 사전 학습을 위한 프레임워크 및 VLM 평가를 위한 다운스트림 작업 등을 포함한 VLM 사전 학습의 기초를 소개합니다.
설명 추가
VLM(비전-언어 모델) 사전 학습은 이미지-텍스트 상관관계를 학습하여 시각 인식 작업에서 효과적인 제로샷 예측을 목표로 합니다. 이는 VLM이 사전 학습 단계에서 다양한 이미지와 텍스트 쌍을 통해 학습하여, 이후에 새로운 데이터셋에서 별도의 추가 학습 없이도 정확한 예측을 할 수 있도록 합니다.
주요 개념
- 이미지-텍스트 쌍:
- VLM 사전 학습은 인터넷 등에서 대규모로 수집된 이미지-텍스트 쌍을 사용합니다. 예를 들어, 이미지와 그에 대한 설명 문장을 함께 학습 데이터로 사용합니다.
- 텍스트 인코더와 이미지 인코더:
- 텍스트 인코더는 텍스트 데이터를 임베딩 벡터로 변환하고, 이미지 인코더는 이미지 데이터를 임베딩 벡터로 변환합니다. 이 과정을 통해 모델은 텍스트와 이미지의 특징을 추출합니다.
- 사전 학습 목표:
- 사전 학습 목표는 이미지와 텍스트 간의 상관관계를 학습하는 데 중점을 둡니다. 예를 들어, CLIP과 같은 모델은 이미지와 텍스트를 임베딩 공간에서 가깝게 위치시키는 대조 학습 목표를 사용합니다. 이는 이미지와 텍스트가 서로 얼마나 잘 맞는지를 학습하는 데 도움을 줍니다.
- 제로샷 예측:
- 제로샷 예측은 모델이 학습 데이터에서 보지 못한 새로운 클래스나 작업에 대해 예측할 수 있는 능력을 의미합니다. 이는 모델이 사전 학습 단계에서 습득한 지식을 바탕으로 새로운 데이터에서도 정확한 예측을 할 수 있도록 합니다.
설명 추가
- 이미지와 텍스트 특징 추출:
- VLM 사전 학습의 첫 단계는 이미지와 텍스트의 특징을 추출하는 것입니다. 이를 위해 텍스트 인코더와 이미지 인코더가 사용됩니다. 텍스트 인코더는 단어, 구문, 문장의 의미를 임베딩 벡터로 변환하고, 이미지 인코더는 이미지의 시각적 특징을 임베딩 벡터로 변환합니다. 이 과정을 통해 모델은 다양한 데이터 모달리티(텍스트와 이미지)를 공통된 임베딩 공간에서 표현할 수 있게 됩니다.
- 시각-언어 상관관계 학습:
- 사전 학습 목표는 이미지와 텍스트 간의 상관관계를 학습하는 데 중점을 둡니다. 예를 들어, 대조 학습(contrastive learning)은 긍정적인 쌍(서로 연관된 이미지와 텍스트)을 가깝게, 부정적인 쌍(서로 연관되지 않은 이미지와 텍스트)을 멀리 위치시키는 방식으로 학습합니다. 이를 통해 모델은 이미지와 텍스트 간의 의미적 유사성을 학습할 수 있습니다.
- 사전 학습 프레임워크:
- VLM 사전 학습을 위한 프레임워크는 다양한 데이터셋과 사전 학습 목표를 사용하여 모델을 학습시키는 구조입니다. 초기의 VLM 프레임워크는 이미지와 텍스트를 별도의 네트워크로 처리하는 방식을 사용했지만, 최근의 프레임워크는 통합된 네트워크를 사용하여 더 효율적으로 학습합니다.
- 다운스트림 작업:
- VLM의 성능을 평가하기 위해 다양한 다운스트림 작업이 사용됩니다. 예를 들어, 이미지 분류, 객체 탐지, 의미론적 분할 등이 있습니다. 이러한 작업에서 제로샷 예측을 수행하여 모델의 일반화 능력을 평가합니다.
이 섹션에서는 이러한 VLM 사전 학습의 기초를 자세히 소개하며, 이를 통해 VLM이 어떻게 이미지와 텍스트 간의 상관관계를 학습하고 다양한 시각 인식 작업에서 제로샷 예측을 수행할 수 있는지 설명합니다.
3.1 네트워크 아키텍처
VLM 사전 학습은 이미지와 텍스트 특징을 추출하는 Deep Neural Network(DNN)를 사용하여 N개의 이미지-텍스트 쌍으로 구성된 사전 학습 데이터셋 D에서 수행됩니다. 여기서 xIn과 xTn은 각각 이미지 샘플과 그에 대응하는 텍스트 샘플을 나타냅니다. DNN은 이미지 인코더 fθ와 텍스트 인코더 fϕ를 가지고 있으며, 이들은 이미지-텍스트 쌍 {xIn, xTn}을 이미지 임베딩 zIn = fθ(xIn)과 텍스트 임베딩 zTn = fϕ(xTn)으로 각각 인코딩합니다. 이 섹션에서는 VLM 사전 학습에서 널리 사용되는 DNN의 아키텍처를 소개합니다.
3.1.1 이미지 특징 학습을 위한 아키텍처
이미지 특징을 학습하기 위해 널리 채택된 두 가지 네트워크 아키텍처가 있습니다. 즉, CNN 기반 아키텍처와 Transformer 기반 아키텍처입니다.
CNN 기반 아키텍처:
다양한 ConvNet (예: VGG [5], ResNet [6], EfficientNet [59])이 이미지 특징을 학습하기 위해 설계되었습니다. VLM 사전 학습에서 가장 인기 있는 ConvNet 중 하나인 ResNet [6]은 컨볼루션 블록 간에 스킵 연결을 채택하여 그래디언트 소실 및 폭발 문제를 완화하고 매우 깊은 신경망을 가능하게 합니다. 더 나은 특징 추출과 비전-언어 모델링을 위해, 여러 연구 [10]에서는 원래의 네트워크 아키텍처 [6], [59]를 수정했습니다. 예를 들어, ResNet의 경우 ResNet-D [60]를 도입하고, [61]에서의 anti-aliased rect-2 블러 풀링을 사용하며, 글로벌 평균 풀링을 Transformer의 멀티-헤드 어텐션 [58]에서의 어텐션 풀링으로 대체합니다.
Transformer 기반 아키텍처:
Transformers는 최근 이미지 분류 [57], 객체 탐지 [62], 의미론적 분할 [63] 등의 시각 인식 작업에서 광범위하게 탐구되었습니다. 이미지 특징 학습을 위한 표준 Transformer 아키텍처로서, ViT [57]는 멀티-헤드 셀프 어텐션 레이어와 피드포워드 네트워크로 구성된 Transformer 블록을 여러 개 쌓아 구성됩니다. 입력 이미지는 먼저 고정 크기의 패치로 분할된 후 선형 투영과 위치 임베딩을 거쳐 Transformer 인코더로 전달됩니다. [10], [18], [64]는 Transformer 인코더 전에 정규화 레이어를 추가하여 ViT를 수정했습니다.
3.1.2 언어 특징 학습을 위한 아키텍처
Transformer 및 그 변형 모델 [14], [16], [58]은 텍스트 특징을 학습하기 위해 널리 채택되었습니다. 표준 Transformer [58]는 인코더-디코더 구조를 가지고 있으며, 인코더는 각각 멀티-헤드 셀프 어텐션 레이어와 다층 퍼셉트론(MLP)으로 구성된 6개의 블록을 포함합니다. 디코더 또한 각각 멀티-헤드 어텐션 레이어, 마스크드 멀티-헤드 레이어 및 MLP로 구성된 6개의 블록을 포함합니다. 대부분의 VLM 연구, 예를 들어 CLIP [10],는 표준 Transformer [58]를 약간 수정하여 사용하며, GPT2 [16]의 가중치 초기화 없이 처음부터 학습을 시작합니다.
3.2 VLM 사전 학습 목표
VLM의 핵심으로서, 다양한 Vision-Language 사전 학습 목표가 설계되어 풍부한 Vision-Language 상관관계를 학습할 수 있게 합니다 [10], [12], [14], [19], [42], [65], [66], [67].
이러한 목표는 크게 세 가지 범주로 나눌 수 있습니다: 대조 목표(contrastive objectives), 생성 목표(generative objectives), 정렬 목표(alignment objectives).
3.2.1 대조 목표 (Contrastive Objectives)
대조 목표는 짝을 이룬 샘플을 특징 공간에서 가깝게 위치시키고 다른 샘플들은 멀리 위치시켜 구별 가능한 표현을 학습하도록 VLM을 훈련시킵니다 [10], [12], [65].
이미지 대조 학습(Image Contrastive Learning)은 쿼리 이미지가 임베딩 공간에서 긍정적 키(즉, 데이터 증강)와 가깝게, 부정적 키(즉, 다른 이미지)와 멀리 위치하도록 강제하여 구별 가능한 이미지 특징을 학습하는 것을 목표로 합니다 [12], [13].
B개의 이미지 배치가 주어지면, 대조 학습 목표(예: InfoNCE [68] 및 그 변형 [12], [13])는 일반적으로 다음과 같이 공식화됩니다:
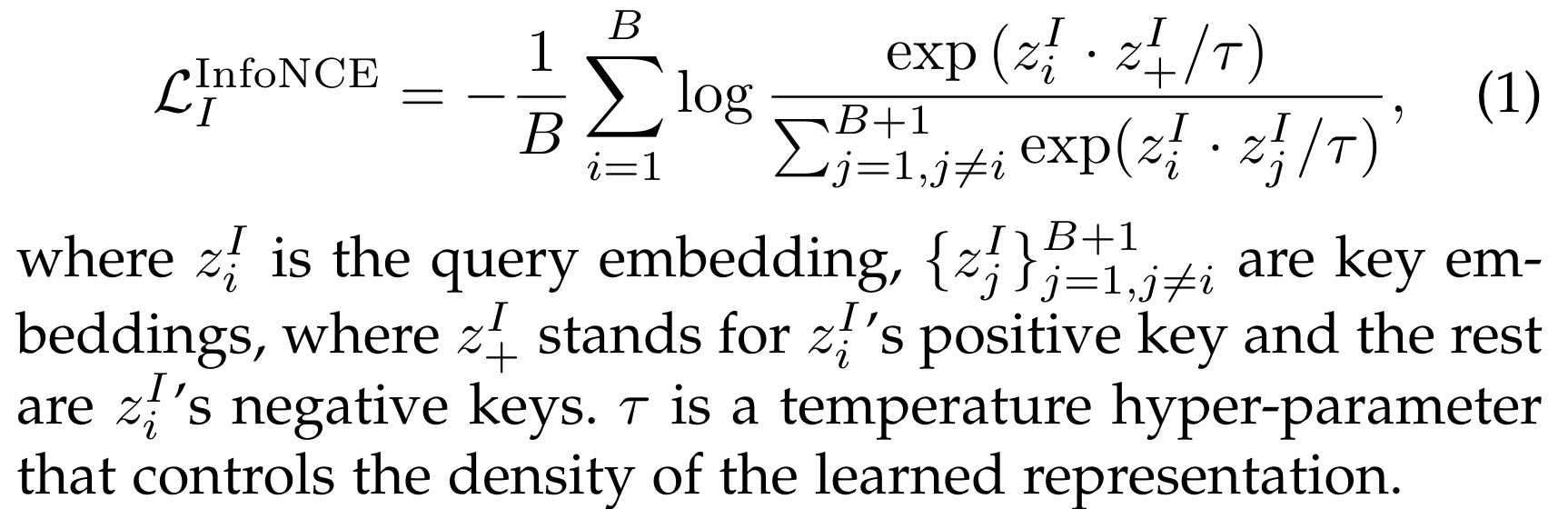
이미지-텍스트 대비 학습(Image-Text Contrastive Learning)은 짝을 이룬 이미지와 텍스트의 임베딩을 가깝게 하고 다른 임베딩은 멀어지게 하여 구별할 수 있는 이미지-텍스트 표현을 학습하는 것을 목표로 합니다【10】【17】. 이는 대칭적인 이미지-텍스트 infoNCE 손실을 최소화함으로써 보통 달성됩니다【10】. 즉, L_IT_infoNCE = LI→T + LT→I로 정의됩니다. 여기서 LI→T는 쿼리 이미지와 텍스트 키를 비교하고, LT→I는 쿼리 텍스트와 이미지 키를 비교합니다. B개의 이미지-텍스트 쌍으로 이루어진 배치가 주어졌을 때, LI→T와 LT→I는 다음과 같이 정의됩니다:
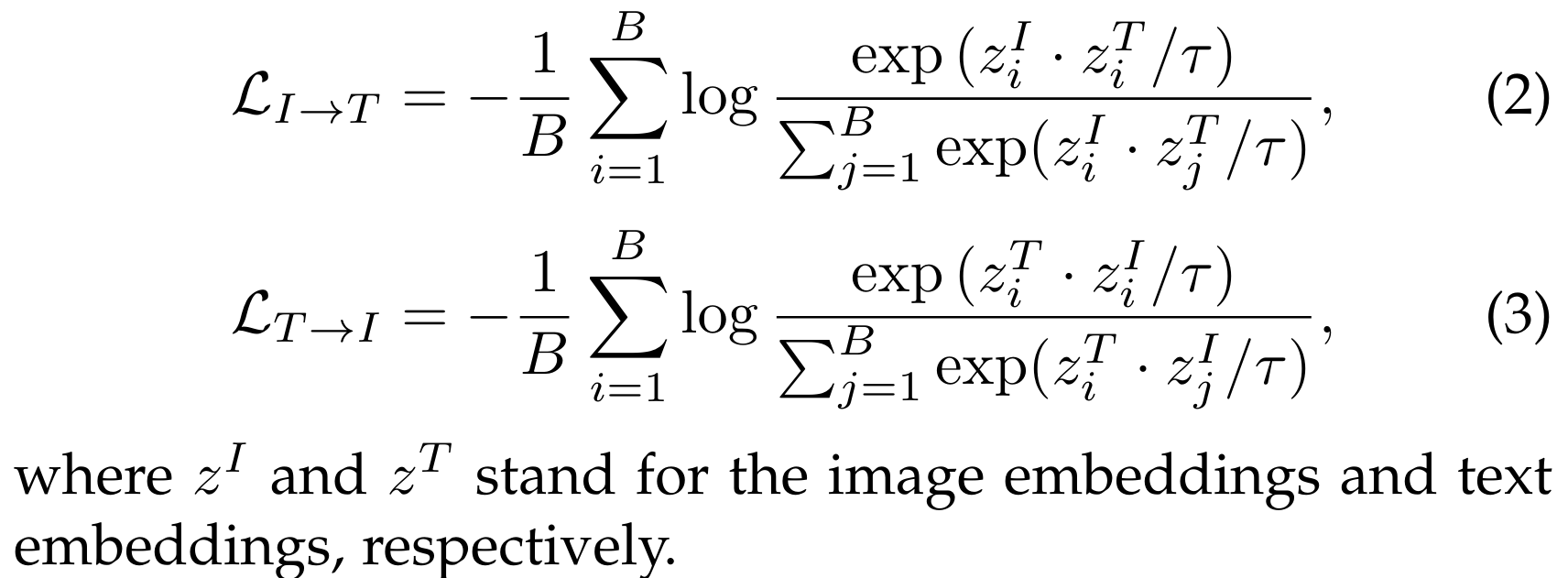
추가 설명
- 대비 학습(Contrastive Learning): 이 방법은 두 가지 데이터(여기서는 이미지와 텍스트)를 비교하여 관련된 데이터는 가깝게, 관련되지 않은 데이터는 멀어지게 학습하는 방법입니다.
- 임베딩(Embedding): 고차원의 데이터를 저차원으로 변환하여, 비교하거나 연산하기 쉽게 만드는 과정입니다.
- 대칭적인 이미지-텍스트 infoNCE 손실: infoNCE 손실 함수는 두 데이터의 유사성을 극대화하고 비유사성을 최소화하는 손실 함수입니다. 이 경우, 이미지와 텍스트 간의 관계를 학습하기 위해 사용됩니다.
- LI→T와 LT→I:
- LI→T (이미지에서 텍스트로): 쿼리 이미지와 텍스트 키를 비교하여 손실을 계산합니다.
- LT→I (텍스트에서 이미지로): 쿼리 텍스트와 이미지 키를 비교하여 손실을 계산합니다.
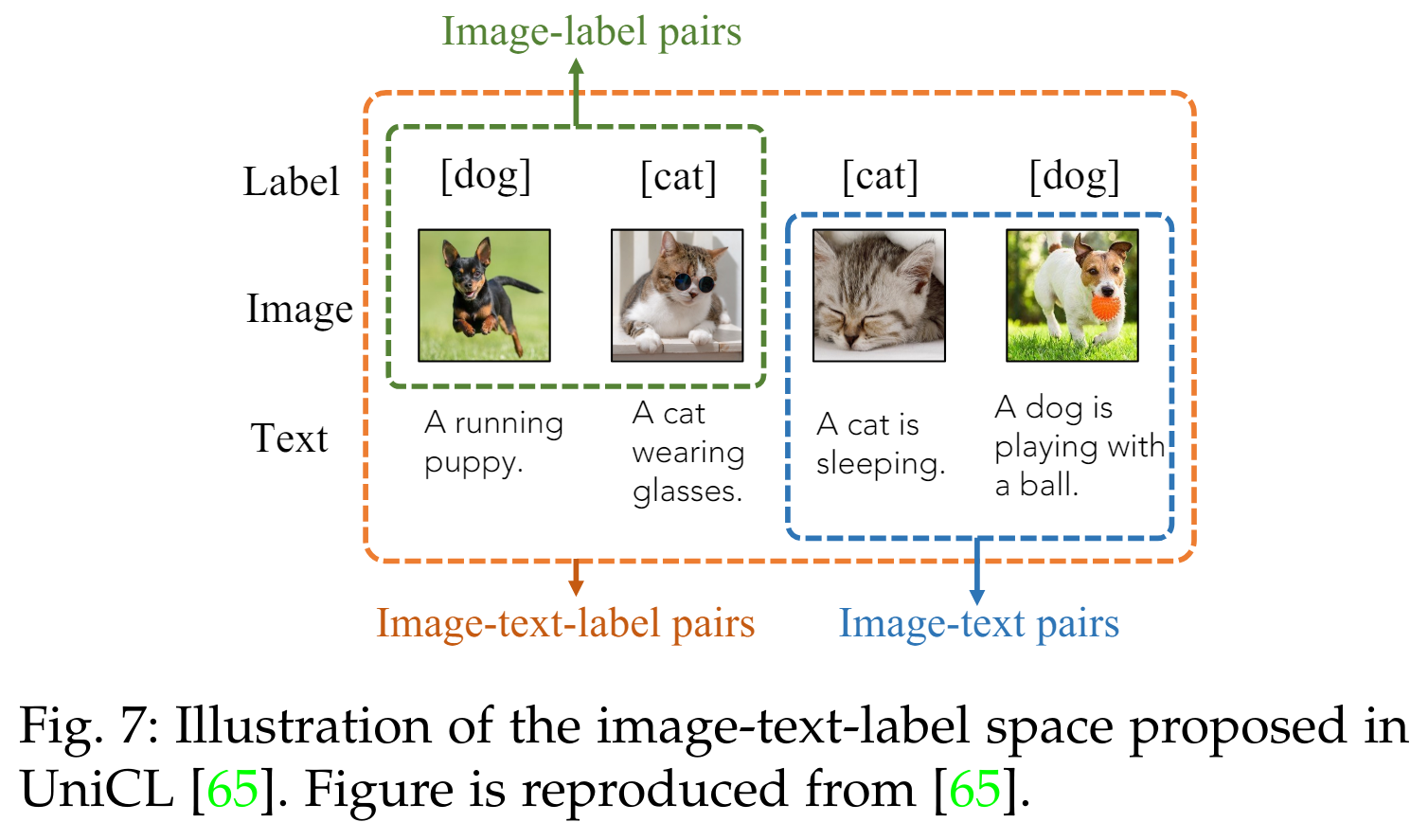
이미지-텍스트-레이블 대비 학습(Image-Text-Label Contrastive Learning). 이미지-텍스트-레이블 대비 학습【65】은 이미지-텍스트 대비 학습에 지도 대비 학습(Supervised Contrastive Learning)【69】을 도입한 것으로, 다음과 같이 식 2와 식 3을 재구성하여 정의됩니다:
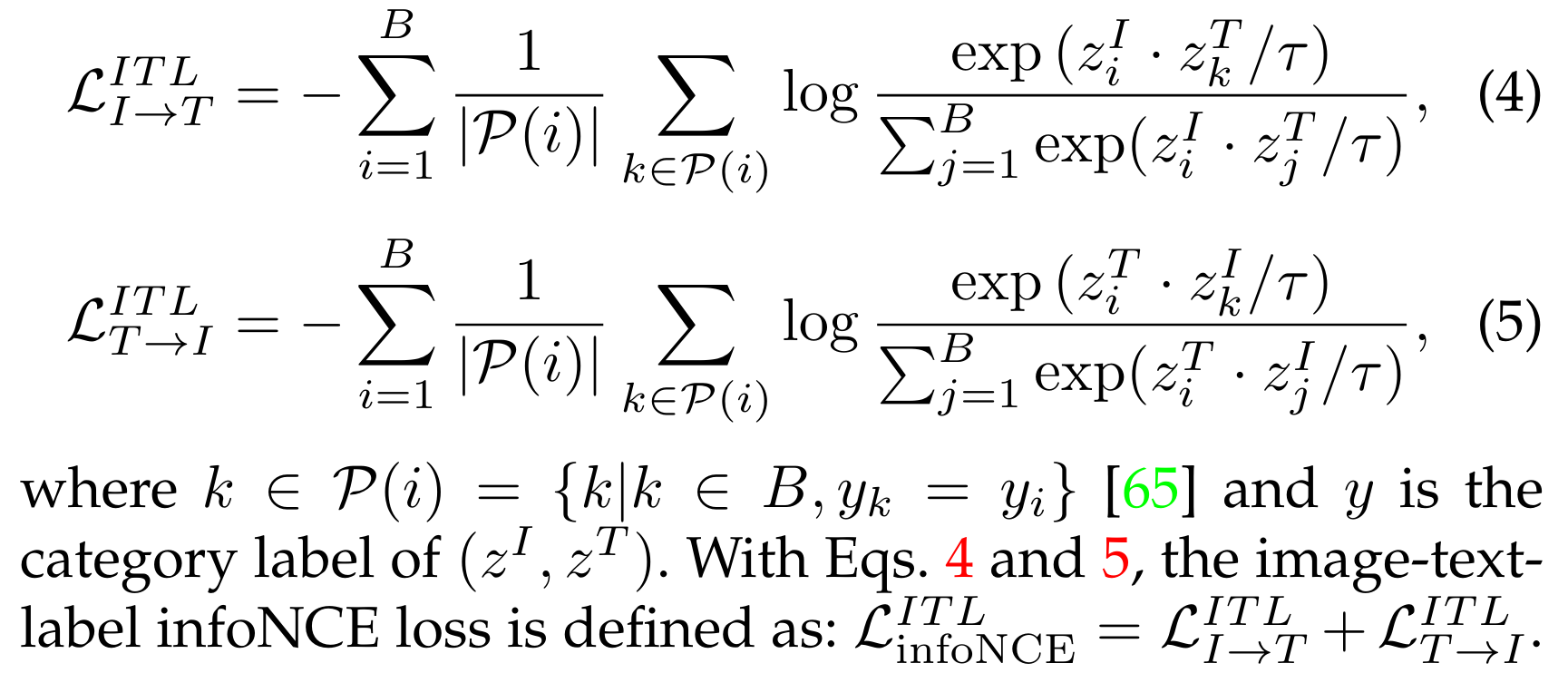
3.2.2 생성 목표 (Generative Objectives)
생성 목표는 이미지 생성 [12], [70], 언어 생성 [14], [19], 또는 크로스 모달 생성 [42]를 통해 네트워크가 이미지/텍스트 데이터를 생성하도록 훈련하여 의미론적 특징을 학습하는 것입니다.
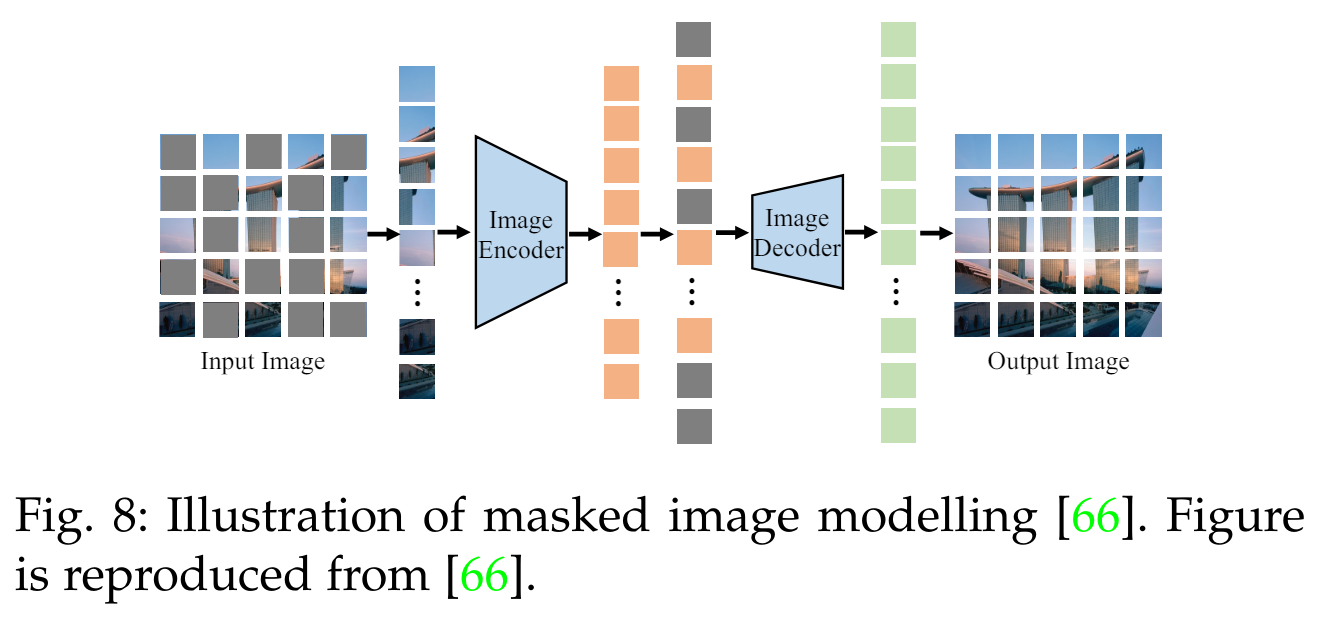
마스크드 이미지 모델링 (Masked Image Modelling)은 이미지를 마스킹하고 재구성함으로써 패치 간 상관관계를 학습합니다 [41], [70]. 이는 입력 이미지의 일부 패치를 무작위로 마스킹하고, 인코더가 마스킹되지 않은 패치를 기반으로 마스킹된 패치를 재구성하도록 훈련합니다. B개의 이미지 배치가 주어졌을 때, 손실 함수(loss function)는 다음과 같이 공식화할 수 있습니다:
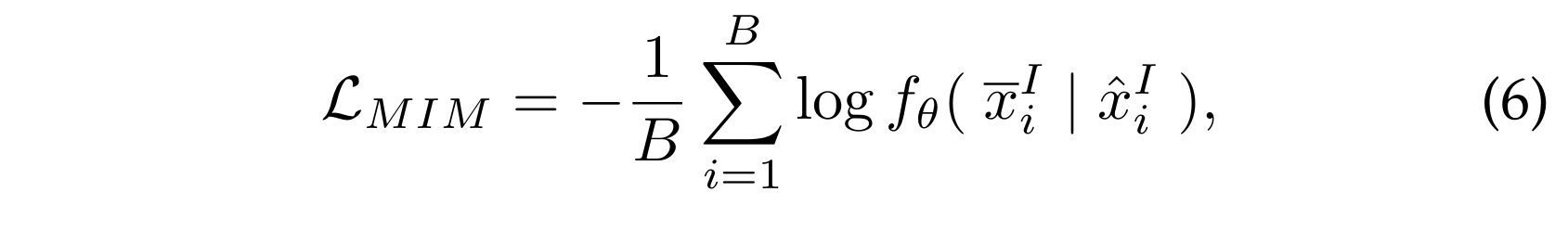

마스크드 언어 모델링 (Masked Language Modelling)은 자연어 처리(NLP)에서 널리 채택된 사전 학습 목표입니다 [14]. 이는 입력 텍스트 토큰의 일정 비율(예: BERT에서 15% [14])을 무작위로 마스킹하고, 마스킹되지 않은 토큰을 사용하여 이를 재구성합니다. 그 과정은 다음과 같습니다:
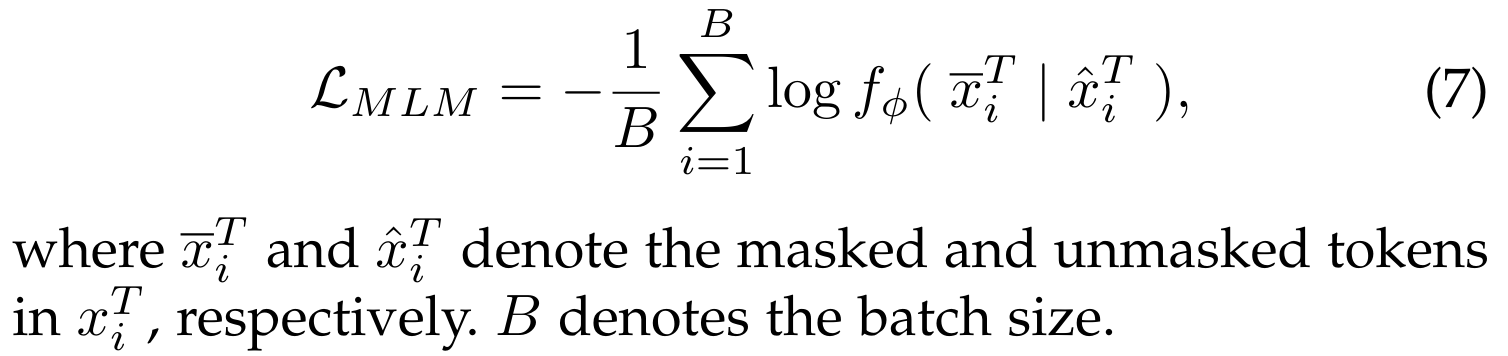
마스크드 크로스 모달 모델링 (Masked Cross-Modal Modelling)은 마스크드 이미지 모델링과 마스크드 언어 모델링을 통합한 것입니다 [42]. 이미지-텍스트 쌍이 주어졌을 때, 이미지 패치의 일부와 텍스트 토큰의 일부를 무작위로 마스킹하고, 마스킹되지 않은 이미지 패치와 마스킹되지 않은 텍스트 토큰을 기반으로 이를 재구성하도록 학습합니다. 그 과정은 다음과 같습니다:
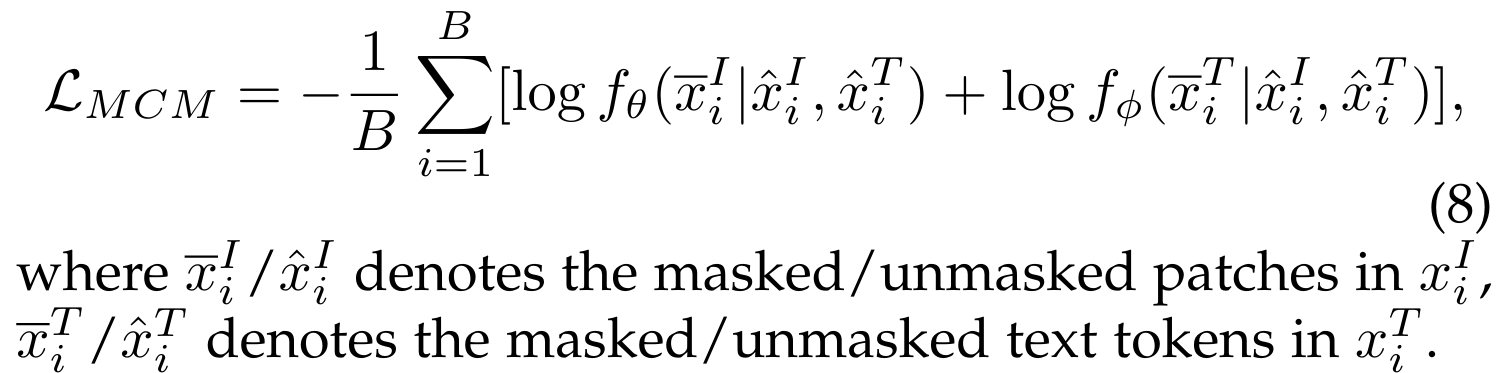
이미지-텍스트 생성 (Image-to-Text Generation)은 이미지와 짝을 이루는 텍스트를 기반으로 텍스트를 자동 회귀 방식으로 예측하는 것을 목표로 합니다 [19]:

자동 회귀 방식
자동 회귀 방식(Autoregressive)은 예측 모델에서 현재의 출력이 이전의 출력에 의존하는 방법을 의미합니다. 쉽게 말해서, 하나의 데이터 포인트를 예측할 때 이전에 예측된 데이터 포인트를 기반으로 한다는 뜻입니다.
예를 들어, 텍스트 생성 모델에서 자동 회귀 방식은 첫 번째 단어를 예측한 후, 그 단어를 사용하여 두 번째 단어를 예측하고, 두 번째 단어와 첫 번째 단어를 사용하여 세 번째 단어를 예측하는 방식입니다. 이 과정은 순차적으로 진행되며, 각 단계의 예측이 다음 단계의 입력으로 사용됩니다.
이해를 돕기 위해, 자동 회귀 방식을 사용하는 이미지-텍스트 생성의 간단한 예를 들어볼게요:
- 이미지가 주어졌을 때, 첫 번째 단어를 예측합니다.
- 예측된 첫 번째 단어를 바탕으로 두 번째 단어를 예측합니다.
- 예측된 첫 번째, 두 번째 단어를 바탕으로 세 번째 단어를 예측합니다.
- 이 과정을 반복하여 전체 문장을 생성합니다.
따라서 자동 회귀 방식은 예측 과정이 연속적이고 순차적으로 진행된다는 특징이 있습니다.
3.2.3 정렬 목표 (Alignment Objectives)
정렬 목표는 임베딩 공간에서 글로벌 이미지-텍스트 매칭 [71], [72] 또는 로컬 영역-단어 매칭 [45], [67]을 통해 이미지-텍스트 쌍을 정렬합니다.
이미지-텍스트 매칭 (Image-Text Matching)은 이미지와 텍스트 간의 전반적인 상관관계를 모델링합니다 [71], [72]. 이는 이미지와 텍스트 간의 정렬 확률을 측정하는 스코어 함수 S(·) 와 이진 분류 손실을 통해 공식화할 수 있습니다:
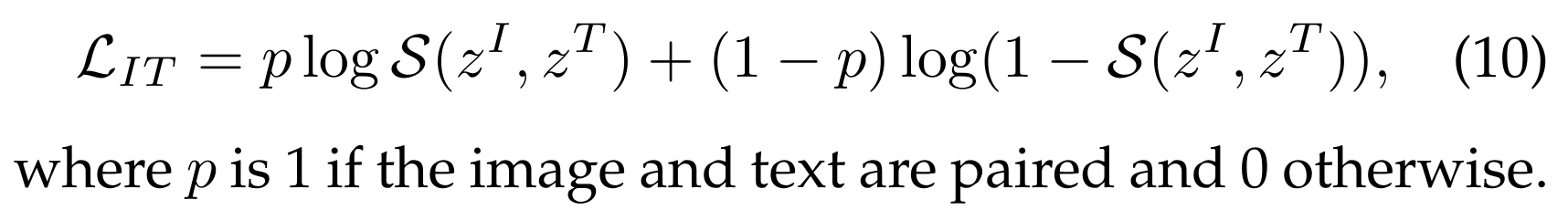
영역-단어 매칭 (Region-Word Matching)은 이미지-텍스트 쌍에서 "이미지 영역"과 "단어" 간의 로컬 크로스 모달 상관관계를 모델링하는 것을 목표로 합니다 [45], [67]. 이는 객체 탐지와 같은 밀집 시각 인식 작업에 사용됩니다. 이를 다음과 같이 공식화할 수 있습니다:

3.3 VLM 사전 학습 프레임워크 (VLM Pre-training Frameworks)
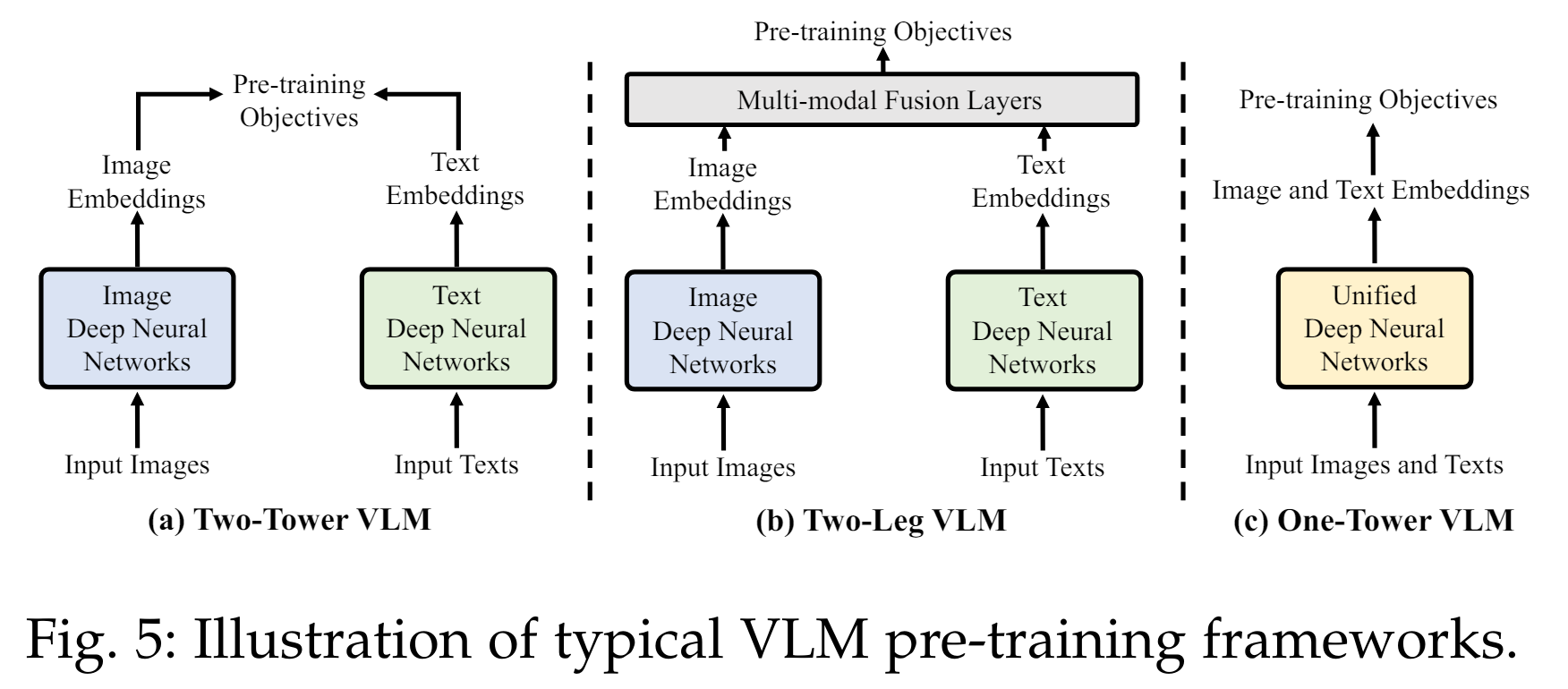
이 섹션에서는 VLM 사전 학습에서 널리 채택된 프레임워크인 two-tower, two-leg, one-tower 사전 학습 프레임워크를 소개합니다.
특히, two-tower 프레임워크는 VLM 사전 학습에서 널리 채택되었습니다 [10], [17]. 이 프레임워크에서는 입력 이미지와 텍스트를 각각 두 개의 별도 인코더로 인코딩합니다. 이는 그림 5 (a)에 나와 있습니다. 약간 다르게, two-leg 프레임워크 [19], [42]는 이미지와 텍스트 모달리티 간의 특징 상호작용을 가능하게 하는 추가적인 멀티모달 융합 레이어(multi-modal fusion layers)를 도입합니다. 이는 그림 5 (b)에 나와 있습니다. 비교하자면, one-tower VLMs [43], [44]은 비전과 언어 학습을 단일 인코더에서 통합하려고 시도합니다. 이는 그림 5 (c)에 나와 있으며, 데이터 모달리티 간의 효율적인 소통을 촉진하려는 목적입니다.
two-tower
VLM(Vision-Language Model) 사전 학습에서 "two-tower" 프레임워크는 이미지와 텍스트를 각각 별도의 인코더로 처리하는 방식을 의미합니다. 이를 더 자세히 설명하면 다음과 같습니다:
Two-Tower 프레임워크
구조:
- 이미지 인코더: 이미지를 인코딩하는 전용 네트워크(예: CNN, Convolutional Neural Network).
- 텍스트 인코더: 텍스트를 인코딩하는 전용 네트워크(예: Transformer).
작동 방식:
- 이미지와 텍스트의 개별 인코딩:
- 입력된 이미지는 이미지 인코더를 통해 임베딩 벡터로 변환됩니다.
- 입력된 텍스트는 텍스트 인코더를 통해 임베딩 벡터로 변환됩니다.
- 임베딩 벡터의 비교:
- 이미지 임베딩 벡터와 텍스트 임베딩 벡터는 공통 임베딩 공간에서 비교됩니다.
- 이를 통해 이미지와 텍스트 간의 유사도나 연관성을 측정할 수 있습니다.
장점:
- 모달리티 간 독립성 유지: 이미지와 텍스트를 별도로 처리하기 때문에 각 모달리티에 최적화된 인코더를 사용할 수 있습니다.
- 모델의 유연성: 이미지와 텍스트 인코더를 독립적으로 개발 및 개선할 수 있습니다.
예시:
- 예를 들어, 이미지 분류와 텍스트 설명 생성 작업에서, 이미지 인코더는 이미지를 이해하고, 텍스트 인코더는 설명을 생성하는 데 특화될 수 있습니다.
그림 설명
- 그림 5 (a)에 나오는 것처럼, 두 개의 타워(tower) 형태로 이미지 인코더와 텍스트 인코더가 병렬로 배치되어 각각의 데이터를 처리합니다.
사용 예시
- 이미지-텍스트 매칭: 이미지와 텍스트가 짝을 이루는지 확인하기 위해 두 개의 임베딩을 비교합니다.
- 이미지 캡션 생성: 이미지를 설명하는 텍스트를 생성하기 위해 이미지 임베딩을 기반으로 텍스트 임베딩을 생성합니다.
이와 같은 two-tower 프레임워크는 이미지와 텍스트의 통합 처리를 통해 다양한 멀티모달(multi-modal) 작업에서 높은 성능을 보일 수 있습니다.
two-leg
VLM 사전 학습에서 "two-leg" 프레임워크는 이미지와 텍스트를 각각 별도의 인코더로 처리하는 것은 two-tower 프레임워크와 같지만, 추가적으로 이미지와 텍스트 간의 상호작용을 위한 멀티모달 융합 레이어(multi-modal fusion layers)를 포함하는 방식을 의미합니다. 이를 더 자세히 설명하면 다음과 같습니다:
Two-Leg 프레임워크
구조:
- 이미지 인코더: 이미지를 인코딩하는 전용 네트워크 (예: CNN, Convolutional Neural Network).
- 텍스트 인코더: 텍스트를 인코딩하는 전용 네트워크 (예: Transformer).
- 멀티모달 융합 레이어: 이미지와 텍스트 임베딩 간의 상호작용을 촉진하는 추가 레이어.
작동 방식:
- 이미지와 텍스트의 개별 인코딩:
- 입력된 이미지는 이미지 인코더를 통해 임베딩 벡터로 변환됩니다.
- 입력된 텍스트는 텍스트 인코더를 통해 임베딩 벡터로 변환됩니다.
- 멀티모달 융합:
- 이미지와 텍스트의 임베딩 벡터는 멀티모달 융합 레이어에서 상호작용합니다.
- 이 융합 레이어는 두 모달리티의 정보를 결합하여 더 풍부한 표현을 만듭니다.
- 통합 임베딩 생성:
- 멀티모달 융합 레이어를 통해 생성된 통합 임베딩 벡터는 이미지와 텍스트 간의 복잡한 상관관계를 더 잘 반영합니다.
장점:
- 강화된 상호작용: 이미지와 텍스트 간의 상호작용이 강화되어, 두 모달리티 간의 연관성을 더 잘 학습할 수 있습니다.
- 풍부한 표현: 멀티모달 융합 레이어를 통해 얻어진 임베딩은 두 모달리티의 특징을 더 풍부하게 반영합니다.
예시:
- 예를 들어, 이미지 설명 생성 작업에서, 이미지 임베딩과 텍스트 임베딩이 융합되어 이미지의 세부 사항과 관련된 더 정확한 설명을 생성할 수 있습니다.
그림 설명
- 그림 5 (b)에 나오는 것처럼, 이미지 인코더와 텍스트 인코더가 각각의 데이터를 처리한 후, 멀티모달 융합 레이어에서 결합됩니다.
사용 예시
- 이미지-텍스트 검색: 이미지와 텍스트 간의 더 정확한 매칭을 위해 두 모달리티의 임베딩을 융합하여 사용합니다.
- 복합 객체 인식: 이미지와 텍스트 간의 복잡한 상호작용을 학습하여 복합 객체 인식 작업에서 성능을 향상시킵니다.
이와 같은 two-leg 프레임워크는 이미지와 텍스트의 통합 처리를 통해 다양한 멀티모달 작업에서 높은 성능을 보일 수 있습니다.
one-tower
One-Tower 프레임워크
VLM 사전 학습에서 "one-tower" 프레임워크는 이미지와 텍스트를 통합하여 단일 인코더로 처리하는 방식을 의미합니다. 이 방식은 두 모달리티(이미지와 텍스트)를 단일 네트워크로 결합하여 동시에 학습하고, 이를 통해 두 모달리티 간의 통신과 상호작용을 더욱 원활하게 합니다. 자세한 설명은 다음과 같습니다:
구조:
- 단일 인코더: 이미지와 텍스트 데이터를 동시에 처리할 수 있는 단일 네트워크. 이 네트워크는 통합된 입력을 받아 이미지와 텍스트의 특징을 동시에 학습합니다.
작동 방식:
- 통합 입력:
- 입력된 이미지와 텍스트는 단일 인코더에 동시에 입력됩니다.
- 단일 인코더는 이미지와 텍스트를 통합된 방식으로 처리하여 임베딩 벡터를 생성합니다.
- 통합 임베딩 생성:
- 단일 인코더는 이미지와 텍스트의 특징을 결합하여 하나의 통합 임베딩 벡터를 생성합니다.
- 이 임베딩 벡터는 두 모달리티의 정보를 포함하고 있어 다양한 작업에 사용할 수 있습니다.
장점:
- 효율적인 통합: 이미지와 텍스트를 동시에 처리하여 두 모달리티 간의 상호작용을 극대화합니다.
- 단순화된 구조: 두 개의 별도 인코더를 사용하는 대신 단일 인코더를 사용하여 모델의 구조를 단순화합니다.
예시:
- 예를 들어, 이미지와 텍스트 간의 상호작용이 중요한 이미지 캡션 생성 작업에서, 단일 인코더는 이미지의 특징과 텍스트의 특징을 동시에 학습하여 더 자연스러운 설명을 생성할 수 있습니다.
그림 설명
- 그림 5 (c)에 나오는 것처럼, 이미지와 텍스트가 단일 인코더에 입력되어 통합 임베딩이 생성됩니다.
사용 예시
- 이미지 캡션 생성: 이미지와 텍스트의 통합 임베딩을 사용하여 이미지의 내용을 설명하는 텍스트를 생성합니다.
- 복합 시각 질문 응답: 이미지와 텍스트 간의 통합된 정보를 사용하여 시각적 질문에 대한 답변을 제공합니다.
이와 같은 one-tower 프레임워크는 이미지와 텍스트의 통합 처리를 통해 다양한 멀티모달 작업에서 높은 성능을 보일 수 있습니다.
3.4 평가 설정 및 다운스트림 작업 (Evaluation Setups and Downstream Tasks)
이 섹션에서는 VLM 평가에서 널리 채택된 설정과 다운스트림 작업을 소개합니다. 설정에는 zero-shot 예측과 linear probing이 포함되며, 다운스트림 작업에는 이미지 분류, 객체 탐지, 의미론적 분할, 이미지-텍스트 검색, 그리고 동작 인식이 포함됩니다.
3.4.1 Zero-shot 예측 (Zero-shot Prediction)
Zero-shot 예측은 VLMs의 일반화 능력을 평가하는 가장 일반적인 방법입니다 [10], [17], [18], [64], [84]. Zero-shot 예측은 특정 작업에 대한 세부 조정 없이 사전 학습된 VLMs를 직접 다운스트림 작업에 적용합니다 [10].
이미지 분류 (Image Classification) [5], [6]는 이미지를 미리 정의된 범주로 분류하는 것을 목표로 합니다. VLMs는 이미지와 텍스트의 임베딩을 비교하여 zero-shot 이미지 분류를 수행하며, 이때 "prompt engineering"을 사용하여 "a photo of a [label]."과 같은 작업 관련 프롬프트를 생성합니다 [10].
의미론적 분할 (Semantic Segmentation) [56]은 이미지의 각 픽셀에 범주 레이블을 할당하는 것을 목표로 합니다. 사전 학습된 VLMs는 주어진 이미지 픽셀과 텍스트의 임베딩을 비교하여 분할 작업에 대해 zero-shot 예측을 수행합니다.
객체 탐지 (Object Detection) [11], [55]는 이미지에서 객체를 위치 지정하고 분류하는 것을 목표로 하며, 이는 다양한 비전 애플리케이션에 중요합니다. 보조 데이터셋에서 학습된 객체 위치 지정 능력을 사용하여, 사전 학습된 VLMs는 주어진 객체 제안(object proposals)과 텍스트의 임베딩을 비교하여 객체 탐지 작업에 대해 zero-shot 예측을 수행합니다.
이미지-텍스트 검색 (Image-Text Retrieval) [87]은 한 모달리티에서 단서를 받아 다른 모달리티에서 요구되는 샘플을 검색하는 것을 목표로 하며, 텍스트 기반 이미지 검색(text-to-image retrieval)과 이미지 기반 텍스트 검색(image-to-text retrieval) 두 가지 작업으로 구성됩니다.
3.4.2 Linear Probing
Linear probing은 VLM 평가에서 널리 채택된 방법입니다 [10]. 이 방법은 사전 학습된 VLM을 고정하고, VLM이 인코딩한 임베딩을 분류하기 위해 선형 분류기(linear classifier)를 훈련하여 VLM 표현을 평가합니다. 이미지 분류 (Image Classification) [5], [6]와 동작 인식 (Action Recognition) [28], [29]은 이러한 평가에서 널리 사용되며, 동작 인식 작업에서는 효율적인 인식을 위해 비디오 클립이 자주 서브 샘플링됩니다 [10].
Linear probing
Linear probing은 머신 러닝에서 사전 학습된 모델의 성능을 평가하기 위해 사용하는 방법 중 하나입니다. 이 방법은 다음과 같은 절차를 따릅니다:
- 사전 학습된 모델 고정: 먼저, 사전 학습된 모델 (예: VLM, Vision-Language Model)의 가중치를 고정합니다. 이때 모델은 업데이트되지 않습니다.
- 임베딩 추출: 고정된 모델을 사용하여 입력 데이터(예: 이미지나 텍스트)를 통과시켜 임베딩(embedding)을 추출합니다. 임베딩은 입력 데이터의 특징을 잘 요약한 벡터 표현입니다.
- 선형 분류기 훈련: 추출된 임베딩을 입력으로 사용하여 선형 분류기(linear classifier)를 훈련합니다. 선형 분류기는 입력 데이터의 임베딩을 사용하여 특정 작업(예: 이미지 분류, 동작 인식)을 수행하도록 학습됩니다.
- 평가: 훈련된 선형 분류기를 사용하여 성능을 평가합니다. 이 과정을 통해 사전 학습된 모델의 임베딩이 얼마나 유용한지, 그리고 해당 모델이 다양한 작업에 잘 일반화되는지를 확인할 수 있습니다.
이 방법은 사전 학습된 모델의 표현 능력을 평가하는 데 효과적입니다. 모델의 파라미터를 고정하고, 단순한 선형 분류기를 추가하여 모델의 임베딩이 다양한 작업에서 얼마나 잘 작동하는지를 측정합니다.
쉽게 말해, linear probing은 복잡한 모델을 추가 학습시키지 않고, 그 모델이 이미 학습한 정보를 이용해 간단한 분류 작업을 얼마나 잘 수행할 수 있는지 평가하는 방법입니다.
4 데이터셋 (Datasets)
이 섹션에서는 VLM 사전 학습과 평가에 일반적으로 사용되는 데이터셋을 요약하여 Table 1-2에 자세히 설명합니다.
4.1 VLM 사전 학습을 위한 데이터셋 (Datasets for Pre-training VLMs)
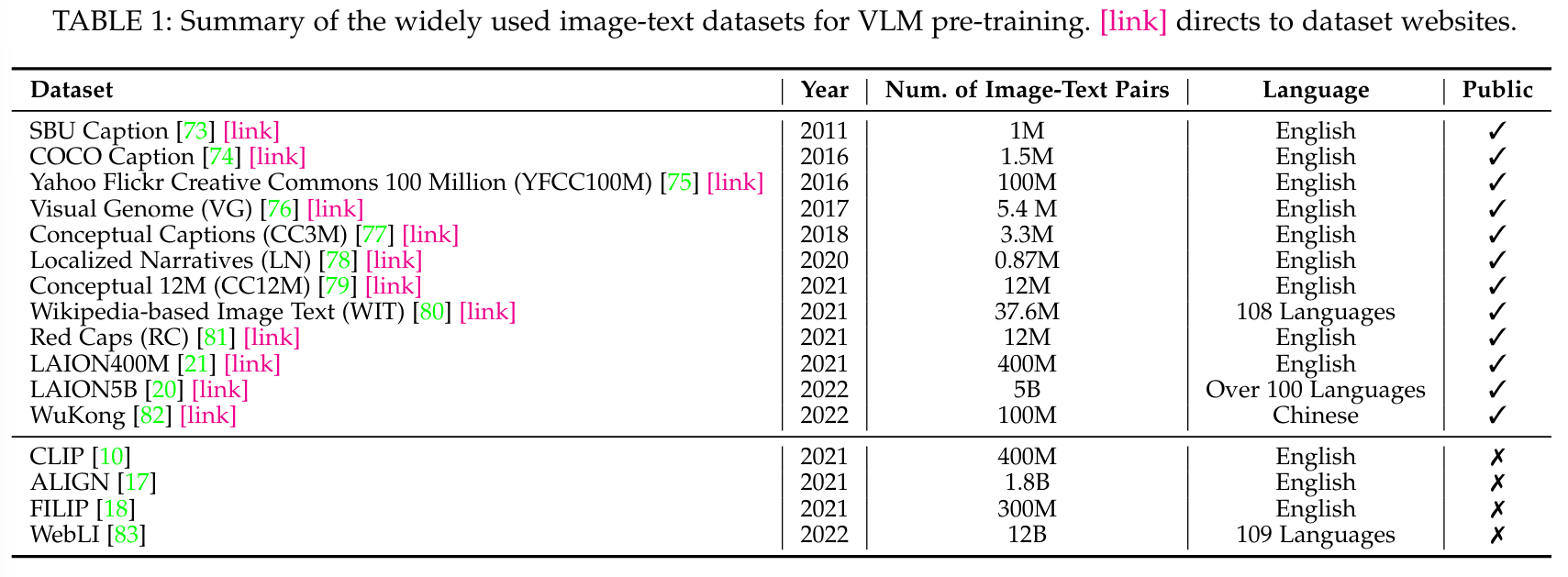
VLM 사전 학습을 위해 여러 대규모 이미지-텍스트 데이터셋이 인터넷에서 수집되었습니다 [10], [17], [20], [21]. 전통적인 군중 라벨링 데이터셋 [40], [90], [110]과 비교하여, 이미지-텍스트 데이터셋 [10], [21]은 훨씬 더 크고 수집 비용이 저렴합니다. 예를 들어, 최근의 이미지-텍스트 데이터셋은 일반적으로 억 단위의 규모입니다 [20], [21], [83]. 이미지-텍스트 데이터셋 외에도, 몇몇 연구에서는 [19], [43], [45], [67] 더 나은 비전-언어 모델링을 위해 부가적인 정보를 제공하는 보조 데이터셋(auxiliary datasets)을 활용합니다. 예를 들어, GLIP [67]은 Object365 [85]를 활용하여 영역 수준의 특징을 추출합니다. VLM 사전 학습을 위한 이미지-텍스트 데이터셋과 보조 데이터셋의 세부 사항은 Appendix B에 제공됩니다.
4.2 VLM 평가를 위한 데이터셋 (Datasets for VLM Evaluation)
많은 데이터셋이 VLM 평가에서 사용되었습니다(Table 2 참조). 여기에는 이미지 분류를 위한 27개, 객체 탐지를 위한 4개, 의미론적 분할을 위한 4개, 이미지-텍스트 검색을 위한 2개, 그리고 동작 인식을 위한 3개가 포함됩니다(데이터셋 세부 사항은 Appendix C에 제공). 예를 들어, 27개의 이미지 분류 데이터셋은 애완동물 식별을 위한 Oxford-IIIT PETS [26], 자동차 인식을 위한 Stanford Cars [25]와 같은 세밀한 작업부터, ImageNet [40]과 같은 일반 작업에 이르기까지 다양한 시각적 인식 작업을 다룹니다.
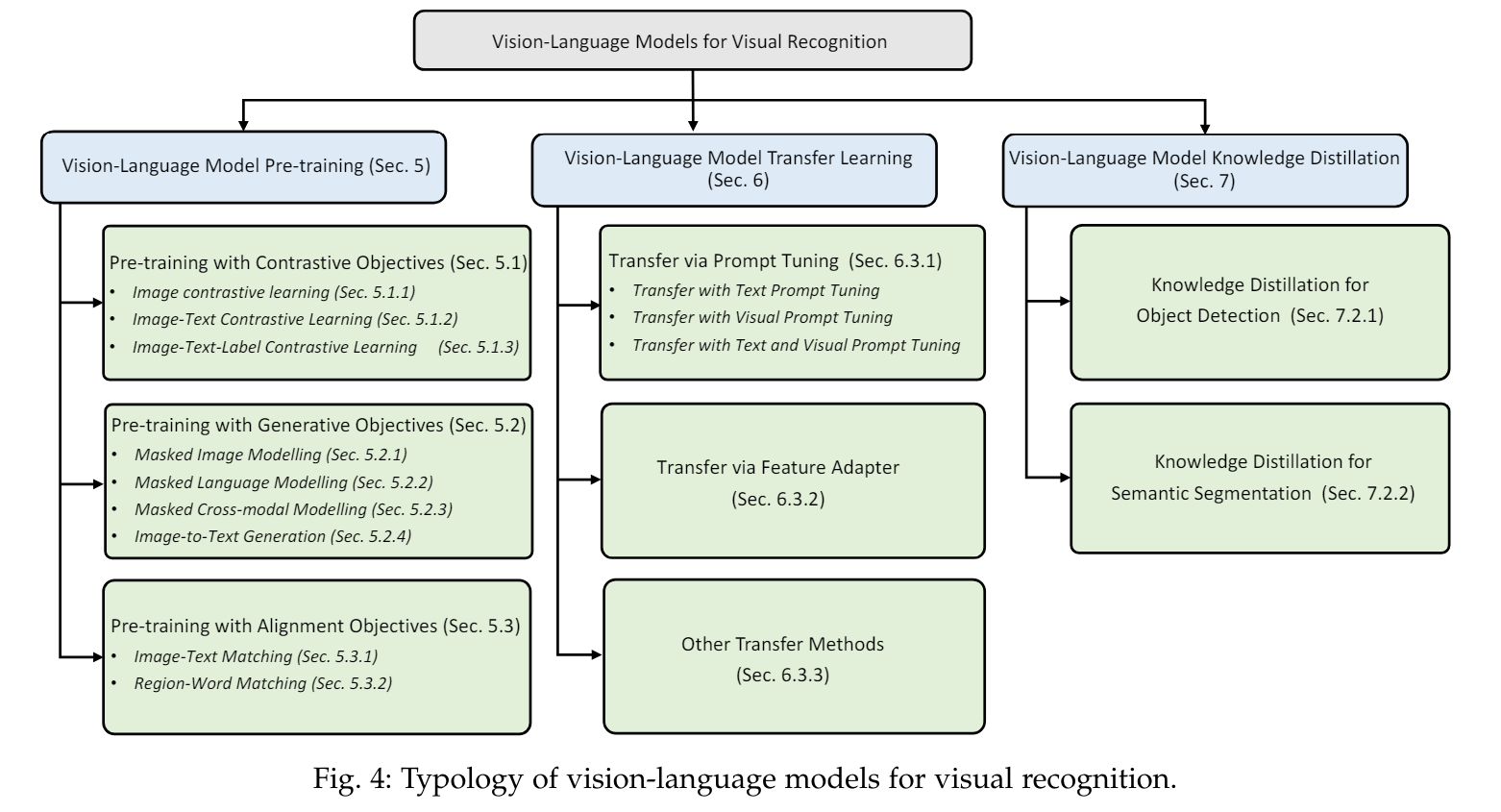
5 비전-언어 모델 사전 학습 (Vision-Language Model Pre-Training)
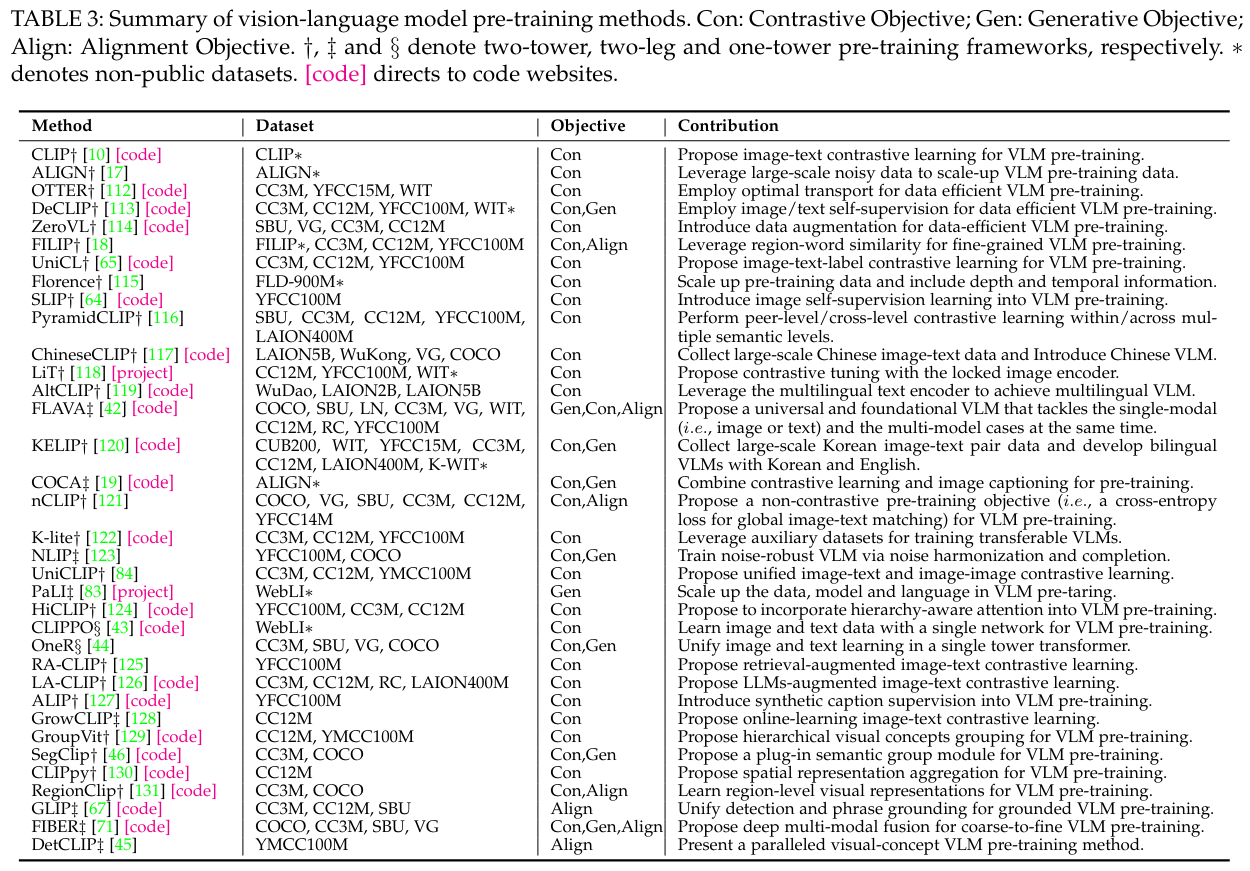
VLM 사전 학습은 세 가지 주요 목표인 대조 목표(contrastive objectives), 생성 목표(generative objectives), 정렬 목표(alignment objectives)로 탐구되었습니다. 이 섹션에서는 Table 3에 나열된 여러 VLM 사전 학습 연구를 통해 이를 검토합니다.
5.1 대조 목표를 사용한 VLM 사전 학습 (VLM Pre-Training with Contrastive Objectives)
대조 학습(contrastive learning)은 VLM 사전 학습에서 널리 탐구되었으며, 구별 가능한 이미지-텍스트 특징을 학습하기 위한 대조 목표를 설계합니다 [10], [64], [113].
5.1.1 이미지 대조 학습 (Image Contrastive Learning)
이 사전 학습 목표는 이미지 모달리티에서 구별 가능한 특징을 학습하는 것을 목표로 하며, 종종 이미지 데이터의 잠재력을 최대한 활용하기 위한 보조 목표로 사용됩니다. 예를 들어, SLIP [64]은 구별 가능한 이미지 특징을 학습하기 위해 Eq. 1에 정의된 표준 infoNCE 손실을 사용합니다.
대조 학습
대조 학습(Contrastive Learning)은 머신 러닝, 특히 딥러닝에서 데이터를 구별하고 유사성을 학습하는 방법 중 하나입니다. 대조 학습의 주요 목표는 비슷한 데이터 포인트는 가까이, 다른 데이터 포인트는 멀리 떨어지도록 임베딩 공간에서 배치하는 것입니다.
대조 학습의 작동 방식
- 양성 쌍(Positive Pairs)과 음성 쌍(Negative Pairs):
- 양성 쌍: 서로 관련 있는 두 데이터 포인트 (예: 동일한 이미지의 두 가지 다른 표현).
- 음성 쌍: 서로 관련이 없는 두 데이터 포인트 (예: 서로 다른 두 이미지).
- 임베딩 벡터 생성:
- 데이터 포인트를 모델에 입력하여 임베딩 벡터(고차원 공간에서의 표현)를 생성합니다.
- 유사성 측정:
- 양성 쌍의 임베딩 벡터 간의 거리는 가깝게, 음성 쌍의 임베딩 벡터 간의 거리는 멀게 유지하도록 학습합니다.
- 일반적으로 코사인 유사도(cosine similarity)나 내적(dot product) 등의 방법을 사용하여 임베딩 벡터 간의 유사성을 측정합니다.
- 손실 함수(Loss Function):
- 대조 학습에서 자주 사용되는 손실 함수는 infoNCE 손실입니다. 이 손실 함수는 양성 쌍의 유사도를 최대화하고, 음성 쌍의 유사도를 최소화하도록 설계되었습니다.
예시: 이미지-텍스트 대조 학습 (Image-Text Contrastive Learning)
이미지-텍스트 대조 학습은 이미지와 텍스트 간의 관계를 학습하기 위해 사용됩니다. 예를 들어, CLIP 모델에서는 다음과 같은 방식으로 대조 학습이 진행됩니다:
- 양성 쌍 생성:
- 동일한 이미지를 설명하는 텍스트와 해당 이미지를 양성 쌍으로 만듭니다.
- 음성 쌍 생성:
- 서로 관련 없는 이미지와 텍스트를 음성 쌍으로 만듭니다.
- 임베딩 벡터 생성:
- 이미지 인코더와 텍스트 인코더를 사용하여 이미지와 텍스트 각각의 임베딩 벡터를 생성합니다.
- 유사성 측정:
- 양성 쌍의 이미지 임베딩과 텍스트 임베딩의 유사도를 높이고, 음성 쌍의 유사도를 낮추도록 모델을 학습시킵니다.
대조 학습을 통해 학습된 모델은 이미지와 텍스트 간의 복잡한 관계를 이해할 수 있게 되며, 이를 기반으로 다양한 다운스트림 작업(예: 이미지 분류, 객체 탐지 등)에서 뛰어난 성능을 발휘할 수 있습니다.
infoNCE 손실
infoNCE 손실은 대조 학습(Contrastive Learning)에서 자주 사용되는 손실 함수 중 하나입니다. 이 손실 함수는 양성 쌍(positive pairs)의 유사도를 최대화하고, 음성 쌍(negative pairs)의 유사도를 최소화하는 방식으로 모델을 학습시킵니다. infoNCE는 "Information Noise-Contrastive Estimation"의 약자로, 본래 확률 분포 추정을 위해 제안되었지만, 최근 대조 학습에 많이 활용되고 있습니다.
손실 함수:
- infoNCE 손실 함수는 양성 쌍의 유사도를 높이는 동시에, 다른 모든 음성 쌍의 유사도를 낮추도록 설계되었습니다.
- 수학적으로, infoNCE 손실은 다음과 같이 정의됩니다:

- 는 임베딩 벡터 zi와 zj간의 유사도(내적 또는 코사인 유사도).
- τ는 온도 하이퍼파라미터(temperature hyperparameter)로, 유사도 분포의 스케일을 조절합니다.
- 분자는 양성 쌍의 유사도를 나타내고, 분모는 양성 쌍과 모든 음성 쌍의 유사도의 합을 나타냅니다.
5.1.2 이미지-텍스트 대조 학습 (Image-Text Contrastive Learning)
이미지-텍스트 대조 학습은 이미지-텍스트 쌍을 대조함으로써 비전-언어 상관관계를 학습하는 것을 목표로 합니다. 즉, 짝지어진 이미지와 텍스트의 임베딩을 가깝게 끌어당기고, 다른 임베딩은 멀리 밀어냅니다 [10]. 예를 들어, CLIP [10]은 Fig. 6에서 이미지와 텍스트 임베딩 간의 내적(dot-product)을 통해 이미지-텍스트 유사성을 측정하는 대칭적 이미지-텍스트 infoNCE 손실을 Eq. 2에서 사용합니다. 사전 학습된 VLM은 따라서 다운스트림 시각 인식 작업에서 zero-shot 예측을 가능하게 하는 이미지-텍스트 상관관계를 학습합니다.
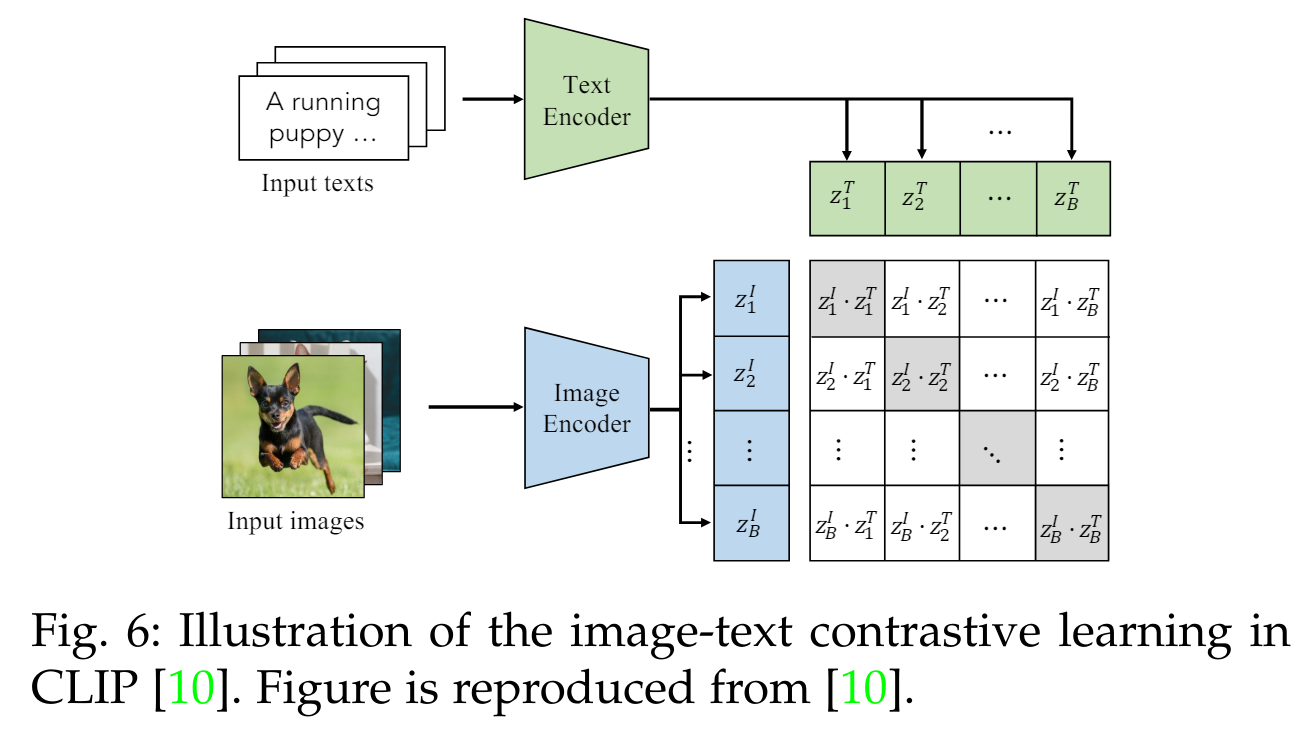
CLIP의 큰 성공에 영감을 받아, 많은 연구들이 다양한 관점에서 대칭적 이미지-텍스트 infoNCE 손실(symmetrical image-text infoNCE loss)을 개선하고 있습니다. 예를 들어, ALIGN [17]은 대규모(즉, 18억 개)지만 노이즈가 많은 이미지-텍스트 쌍을 사용하여 노이즈에 강한 대조 학습을 통해 VLM 사전 학습을 확장합니다. 몇몇 연구들 [112], [113], [114]은 대신 훨씬 적은 이미지-텍스트 쌍을 사용하여 데이터 효율적인 VLM 사전 학습을 탐구합니다.
symmetrical image-text infoNCE loss
Symmetrical image-text infoNCE loss는 이미지와 텍스트 간의 대칭적 관계를 학습하기 위해 사용되는 손실 함수입니다. 이는 이미지와 텍스트 쌍의 임베딩 간 유사성을 최대화하고, 무관한 이미지와 텍스트 임베딩 간의 유사성을 최소화하는 방식으로 작동합니다. 이 접근법은 CLIP (Contrastive Language–Image Pre-training) 모델에서 사용되었으며, 대조 학습을 통해 이미지와 텍스트 간의 강한 상관관계를 학습하는 데 효과적입니다.
대칭적 손실의 의미
대칭적이라는 용어는 이미지-텍스트 관계를 학습할 때 양방향으로 동일하게 적용된다는 의미입니다. 즉, 이미지 임베딩이 텍스트 임베딩과의 유사도를 학습할 뿐만 아니라, 텍스트 임베딩도 이미지 임베딩과의 유사도를 학습합니다. 이를 통해 모델은 더 강력하고 일관된 이미지-텍스트 상관관계를 학습하게 됩니다.
예를 들어, CLIP 모델에서는 다음과 같은 방식으로 대칭적 infoNCE 손실이 적용됩니다:
- 이미지에서 텍스트로:
- 특정 이미지가 주어졌을 때, 해당 이미지와 관련된 텍스트 설명의 임베딩 유사도를 최대화합니다.
- 텍스트에서 이미지로:
- 특정 텍스트 설명이 주어졌을 때, 해당 설명과 관련된 이미지의 임베딩 유사도를 최대화합니다.
이러한 대칭적 접근은 모델이 이미지와 텍스트 간의 관계를 더 잘 이해하도록 도와줍니다.
요약
- Symmetrical image-text infoNCE loss는 이미지와 텍스트 간의 유사성을 학습하기 위한 대조 학습 손실 함수입니다.
- 이미지와 텍스트 임베딩의 유사도를 최대화하고, 무관한 임베딩 간의 유사도를 최소화합니다.
- 대칭적으로 적용되어 이미지와 텍스트 간의 강력한 상관관계를 학습합니다.
예를 들어, DeCLIP [113]은 유사한 쌍의 정보를 활용하기 위해 최근접 이웃 감독(nearest-neighbor supervision)을 도입하여 제한된 데이터로도 효과적인 사전 학습을 가능하게 합니다. OTTER [112]는 최적 수송(optimal transport)을 사용하여 이미지를 텍스트와 유사한 쌍으로 묶어 필요한 학습 데이터를 크게 줄입니다. ZeroVL [114]는 편향되지 않은 데이터 샘플링과 동전 뒤집기 믹스업(coin flipping mixup)을 통한 데이터 증강을 통해 제한된 데이터 자원을 활용합니다.
또 다른 후속 연구들 [18], [116], [129]은 다양한 의미 수준에서 이미지-텍스트 대조 학습을 수행하여 포괄적인 비전-언어 상관관계 모델링을 목표로 합니다. 예를 들어, FILIP [18]은 대조 학습에 영역-단어 정렬(region-word alignment)을 도입하여 세밀한 비전-언어 대응 지식을 학습할 수 있게 합니다. PyramidCLIP [116]은 여러 의미 수준을 구성하고, 효과적인 VLM 사전 학습을 위해 교차 수준(cross-level)과 동등 수준(peer-level) 대조 학습을 모두 수행합니다.
또한, 몇몇 최신 연구들은 이미지-텍스트 쌍을 증강하여 이를 더욱 개선합니다 [125], [126], [127], [128]. 예를 들어, LA-CLIP [126]과 ALIP [127]은 대형 언어 모델을 사용하여 주어진 이미지에 대한 합성 캡션을 증강합니다. RA-CLIP [125]은 이미지-텍스트 쌍 증강을 위해 관련 있는 이미지-텍스트 쌍을 검색합니다. 데이터 모달리티 간의 효율적인 소통을 촉진하기 위해, [44]와 [43]은 비전과 언어 학습을 단일 인코더에서 통합하려고 시도합니다.

5.1.3 이미지-텍스트-레이블 대조 학습 (Image-Text-Label Contrastive Learning)
이 유형의 사전 학습은 Eq. 4에서 정의된 대로 이미지 분류 레이블 [65]을 이미지-텍스트 대조 학습에 도입합니다. 이는 이미지, 텍스트, 분류 레이블을 Fig. 7에 나와 있는 것처럼 공유된 공간으로 인코딩합니다. 이 방법은 이미지 레이블을 통한 지도 학습과 이미지-텍스트 쌍을 통한 비지도 VLM 사전 학습을 모두 활용합니다. UniCL [65]에서 보고된 바와 같이, 이러한 사전 학습은 구별 가능한 특징과 작업 특화된 특징(예: 이미지 분류)을 동시에 학습할 수 있게 합니다. 후속 연구 [115]에서는 약 9억 개의 이미지-텍스트 쌍을 사용하여 UniCL을 확장함으로써 다양한 다운스트림 인식 작업에서 뛰어난 성능을 달성했습니다.
5.1.4 논의 (Discussion)
대조 목표는 양성 쌍이 음성 쌍에 비해 유사한 임베딩을 갖도록 강제합니다. 이는 VLM이 구별 가능한 비전과 언어 특징을 학습하도록 장려합니다 [10], [17]. 더 구별 가능한 특징은 일반적으로 더 확실하고 정확한 zero-shot 예측을 가능하게 합니다. 그러나 대조 목표에는 두 가지 한계가 있습니다: (1) 양성 쌍과 음성 쌍을 공동으로 최적화하는 것은 복잡하고 도전적입니다 [10], [17]; (2) 특징의 구별 가능성을 조절하기 위한 휴리스틱 온도 하이퍼파라미터(temperature hyper-parameter)를 포함합니다. 이는 3.2.1절에서 설명되었습니다.
휴리스틱
휴리스틱(Heuristic)은 문제 해결이나 학습, 발견을 위해 사용되는 경험적이고 실용적인 방법을 의미합니다. 이는 항상 최적의 해결책을 보장하지는 않지만, 실용적이고 효율적으로 문제를 해결하거나 의사 결정을 내릴 수 있도록 도와줍니다. 휴리스틱은 일반적으로 복잡한 문제를 간단히 하기 위해 사용되며, 경험과 직관에 기반한 규칙이나 접근법을 포함합니다.
휴리스틱의 주요 특징
- 경험 기반: 휴리스틱은 과거의 경험과 직관을 바탕으로 합니다. 이는 문제 해결을 위한 경험적 규칙이나 지침을 포함합니다.
- 실용성: 항상 최적의 해결책을 찾지는 않지만, 대부분의 상황에서 충분히 좋은 해결책을 빠르게 찾을 수 있습니다.
- 단순화: 복잡한 문제를 더 간단한 문제로 변환하여 해결합니다.
- 효율성: 제한된 시간이나 자원 내에서 빠른 결정을 내릴 수 있게 합니다.
예시
- 온도 하이퍼파라미터(Temperature Hyper-Parameter): 머신 러닝에서 대조 학습에 사용되는 휴리스틱 중 하나로, 모델의 출력 분포의 스케일을 조절하여 학습의 안정성과 성능을 향상시킵니다.
- 탐욕적 알고리즘(Greedy Algorithm): 각 단계에서 가장 최적이라고 생각되는 선택을 하는 방법으로, 전체 문제의 최적 해결책을 보장하지는 않지만, 실용적인 시간 내에 좋은 해결책을 찾을 수 있습니다.
응용 분야
- 컴퓨터 과학: 알고리즘 설계, 최적화 문제, 인공지능에서 자주 사용됩니다.
- 의사 결정: 제한된 정보와 시간 내에서 결정을 내려야 하는 상황에서 유용합니다.
- 문제 해결: 복잡한 문제를 단순화하고, 경험에 기반한 해결책을 제시합니다.
휴리스틱은 복잡하고 계산 비용이 많이 드는 문제를 해결하기 위한 실용적인 접근법을 제공하며, 최적화 문제나 머신 러닝 모델의 학습 과정에서 자주 사용됩니다.
5.2 생성 목표를 사용한 VLM 사전 학습 (VLM Pre-training with Generative Objectives)
생성 VLM 사전 학습은 마스크드 이미지 모델링, 마스크드 언어 모델링, 마스크드 크로스 모달 모델링 및 이미지-텍스트 생성을 통해 이미지나 텍스트를 생성하는 방법을 학습하여 의미론적 지식을 습득합니다.
5.2.1 마스크드 이미지 모델링 (Masked Image Modelling)
이 사전 학습 목표는 Eq. 6에서 정의된 대로 이미지를 마스킹하고 재구성하여 이미지의 맥락 정보를 학습하도록 안내합니다. 마스크드 이미지 모델링 (예: MAE [41]와 BeiT [70])에서는 이미지의 특정 패치를 마스킹하고, 인코더는 마스킹되지 않은 패치를 기반으로 이를 재구성하도록 훈련됩니다(Fig. 8 참조). 예를 들어, FLAVA [42]는 BeiT [70]에서와 같이 직사각형 블록 마스킹을 채택하고, KELIP [120]과 SegCLIP [46]은 MAE를 따라 훈련 중에 큰 비율(즉, 75%)의 패치를 마스킹합니다.
5.2.2 마스크드 언어 모델링 (Masked Language Modelling)
마스크드 언어 모델링은 NLP에서 널리 채택된 사전 학습 목표로, Eq. 7에서 정의된 대로 VLM 사전 학습에서 텍스트 특징 학습의 효과를 보여줍니다. 이 방법은 각 입력 텍스트의 일부 토큰을 마스킹하고 네트워크를 훈련시켜 마스킹된 토큰을 예측하도록 합니다(Fig. 9 참조). [14]를 따라, FLAVA [42]는 텍스트 토큰의 15%를 마스킹하고 나머지 토큰으로부터 이를 재구성하여 단어 간 상관관계를 모델링합니다. FIBER [71]는 VLM 사전 학습 목표 중 하나로 마스크드 언어 모델링 [14]을 채택하여 더 나은 언어 특징을 추출합니다.
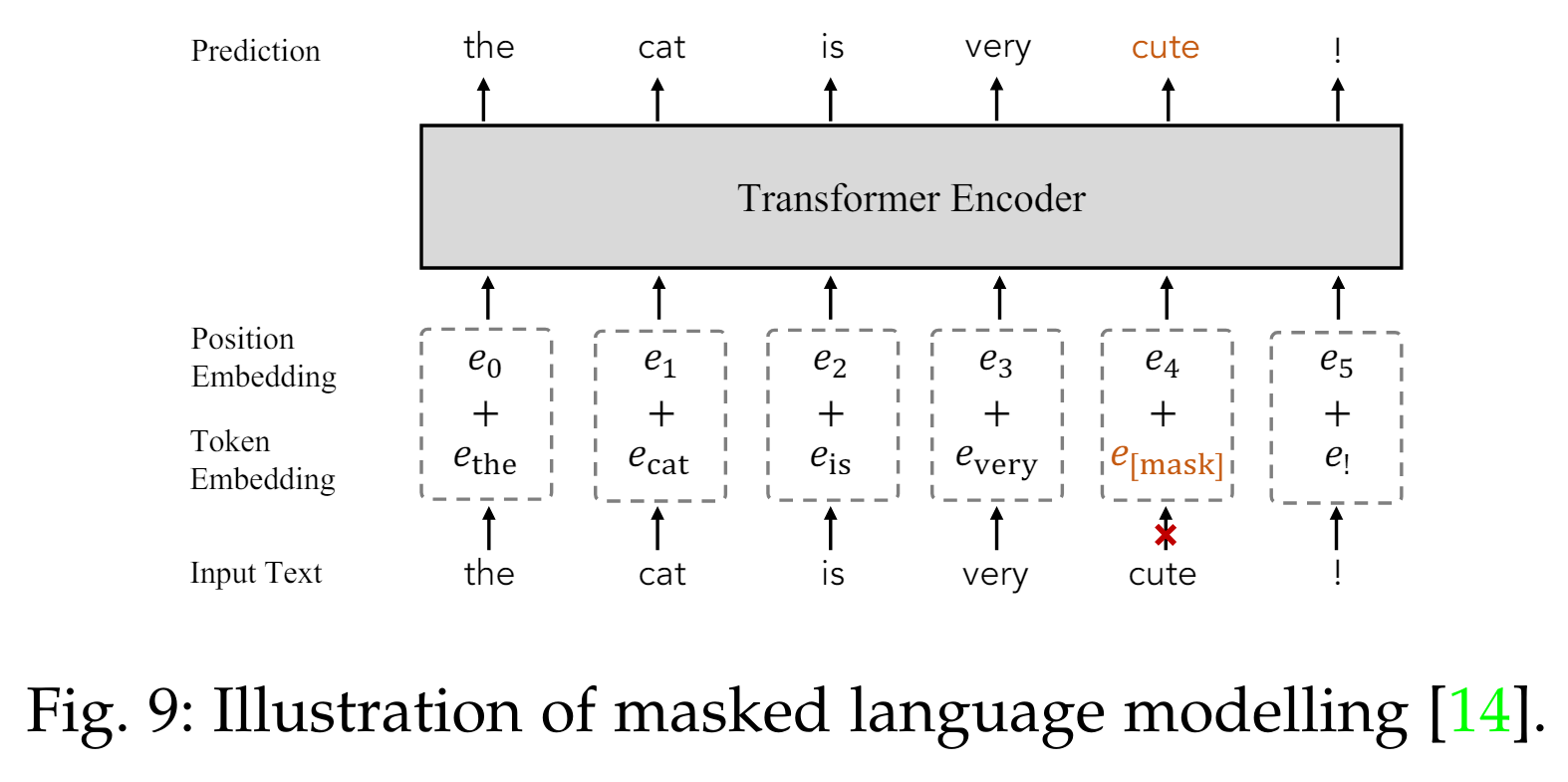
5.2.3 마스크드 크로스 모달 모델링 (Masked Cross-Modal Modelling)
마스크드 크로스 모달 모델링은 Eq. 8에서 정의된 대로 이미지 패치와 텍스트 토큰을 함께 마스킹하고 재구성합니다. 이는 마스크드 이미지 모델링과 마스크드 언어 모델링의 이점을 모두 계승합니다. 특정 비율의 이미지 패치와 텍스트 토큰을 마스킹하고, 마스킹되지 않은 이미지 패치와 텍스트 토큰의 임베딩을 기반으로 이를 재구성하도록 VLM을 훈련시킵니다. 예를 들어, FLAVA [42]는 [70]에서처럼 약 40%의 이미지 패치를, [14]에서처럼 15%의 텍스트 토큰을 마스킹한 후, MLP를 사용하여 마스킹된 패치와 토큰을 예측하여 풍부한 vision-language 상관관계 정보를 캡처합니다.
5.2.4 이미지-텍스트 생성 (Image-to-Text Generation)
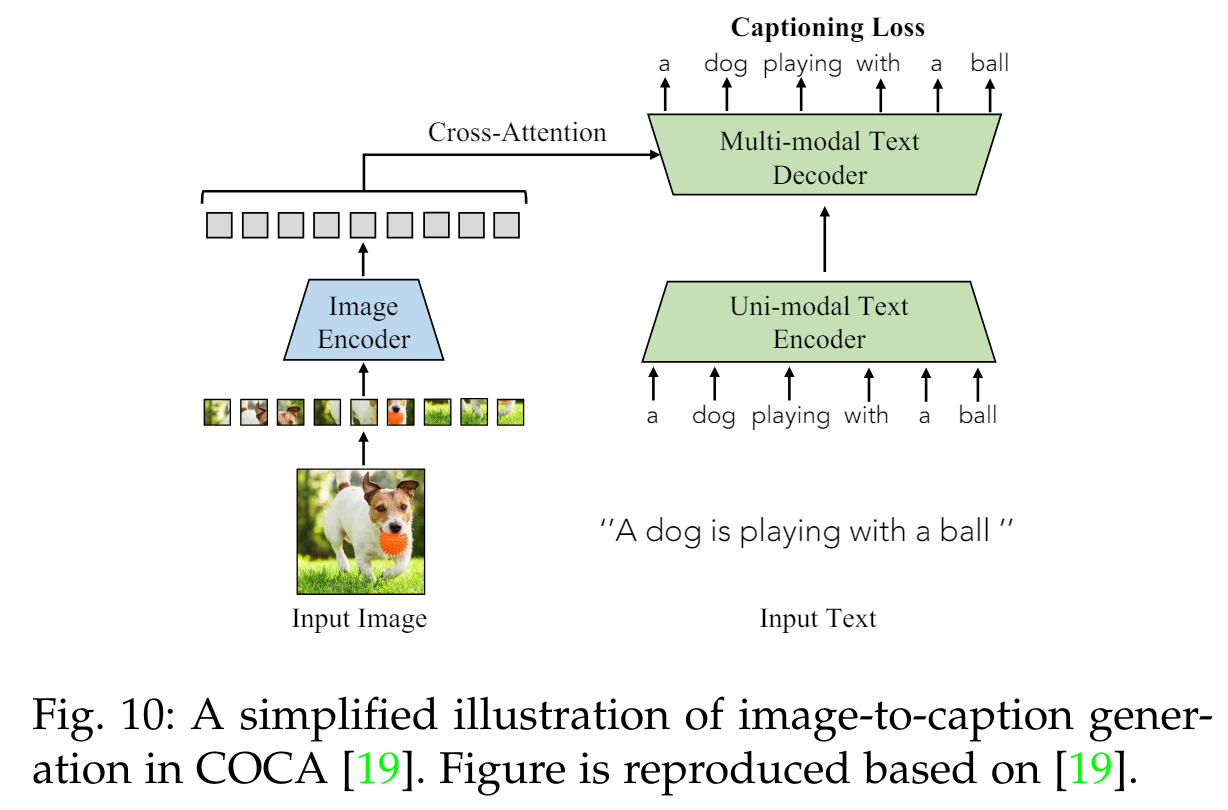
이미지-텍스트 생성은 주어진 이미지에 대한 설명 텍스트를 생성하여 세밀한 vision-language 상관관계를 캡처하는 것을 목표로 합니다. VLM을 훈련시켜 토큰화된 텍스트를 예측하도록 합니다. 먼저 입력 이미지를 중간 임베딩으로 인코딩한 다음, 이를 설명 텍스트로 디코딩합니다(Eq. 9 참조). 예를 들어, COCA [19], NLIP [123], PaLI [83]는 표준 인코더-디코더 아키텍처와 이미지 캡셔닝 목표를 사용하여 VLM을 훈련합니다(Fig. 10 참조).
5.2.5 논의 (Discussion)
생성 목표는 크로스 모달 생성 또는 마스크드 이미지/언어/크로스 모달 모델링을 통해 작동하여, VLM이 더 나은 zero-shot 예측을 위해 풍부한 vision, language 및 vision-language 맥락을 학습하도록 장려합니다. 따라서 생성 목표는 일반적으로 풍부한 맥락 정보를 학습하기 위해 다른 VLM 사전 학습 목표 위에 추가적인 목표로 채택됩니다 [19], [42], [113].
5.3 정렬 목표를 사용한 VLM 사전 학습 (VLM Pre-training with Alignment Objectives)
정렬 목표는 주어진 텍스트가 주어진 이미지를 올바르게 설명하는지 예측하는 학습을 통해 VLM이 쌍을 이룬 이미지와 텍스트를 정렬하도록 강제합니다. 이는 VLM 사전 학습을 위해 크게 글로벌 이미지-텍스트 매칭과 로컬 영역-단어 매칭으로 분류될 수 있습니다.
5.3.1 이미지-텍스트 매칭 (Image-Text Matching)
이미지-텍스트 매칭은 Eq. 10에서 정의된 대로 쌍을 이룬 이미지와 텍스트를 직접 정렬하여 글로벌 이미지-텍스트 상관관계를 모델링합니다. 예를 들어, 주어진 이미지-텍스트 쌍 배치에서 FLAVA [42]는 분류기와 이진 분류 손실을 통해 주어진 이미지를 그에 해당하는 텍스트와 매칭합니다. FIBER [71]는 [72]를 따라 쌍 간 유사성을 통해 하드 네거티브(hard negatives)를 찾아 이미지와 텍스트 간의 더 나은 정렬을 도모합니다.
하드 네거티브(Hard Negative)
하드 네거티브(Hard Negative)는 머신 러닝과 특히 대조 학습(Contrastive Learning)에서 중요한 개념으로, 모델이 학습하기 어렵다고 여겨지는 음성 샘플(negative sample)을 의미합니다. 하드 네거티브 샘플은 주어진 양성 샘플(positive sample)과 매우 유사하지만 실제로는 다른 클래스에 속하는 샘플입니다.
하드 네거티브의 중요성
- 효과적인 학습: 하드 네거티브 샘플을 사용하면 모델이 더 효과적으로 학습할 수 있습니다. 모델이 양성 샘플과 하드 네거티브 샘플을 구별하기 위해 더 세밀한 특징을 학습해야 하기 때문입니다.
- 성능 향상: 하드 네거티브 샘플을 포함한 학습은 모델의 일반화 성능을 향상시킵니다. 이는 모델이 다양한 상황에서 더 정확하게 예측할 수 있도록 도와줍니다.
예시
예를 들어, 이미지-텍스트 매칭 작업에서 양성 샘플은 특정 이미지와 해당 이미지를 설명하는 텍스트 쌍입니다. 하드 네거티브 샘플은 해당 이미지와 비슷한 다른 이미지를 설명하는 텍스트 쌍일 수 있습니다. 모델은 이 하드 네거티브 샘플을 양성 샘플과 구별하기 위해 더 세밀한 특징을 학습해야 합니다.
적용 방법
- 샘플 선택: 학습 과정에서 모델은 양성 샘플과 함께 여러 음성 샘플을 처리합니다. 이 중에서 가장 유사한 음성 샘플을 하드 네거티브 샘플로 선택합니다.
- 손실 함수: 하드 네거티브 샘플을 포함한 손실 함수를 사용하여 모델을 학습합니다. 이는 모델이 하드 네거티브 샘플과 양성 샘플을 명확히 구별할 수 있도록 도와줍니다.
FIBER와 같은 모델에서의 사용 예
FIBER [71]는 하드 네거티브 샘플을 찾아 이미지와 텍스트 간의 더 나은 정렬을 도모합니다. 이를 통해 모델은 단순한 음성 샘플보다 더 어려운 샘플을 학습하게 되어, 더 강력하고 일반화된 특징을 학습할 수 있습니다.
하드 네거티브 샘플을 사용하는 방법은 모델의 학습 효율성을 크게 높이고, 다양한 실제 상황에서 더 좋은 성능을 발휘하도록 합니다.
5.3.2 영역-단어 매칭 (Region-Word Matching)
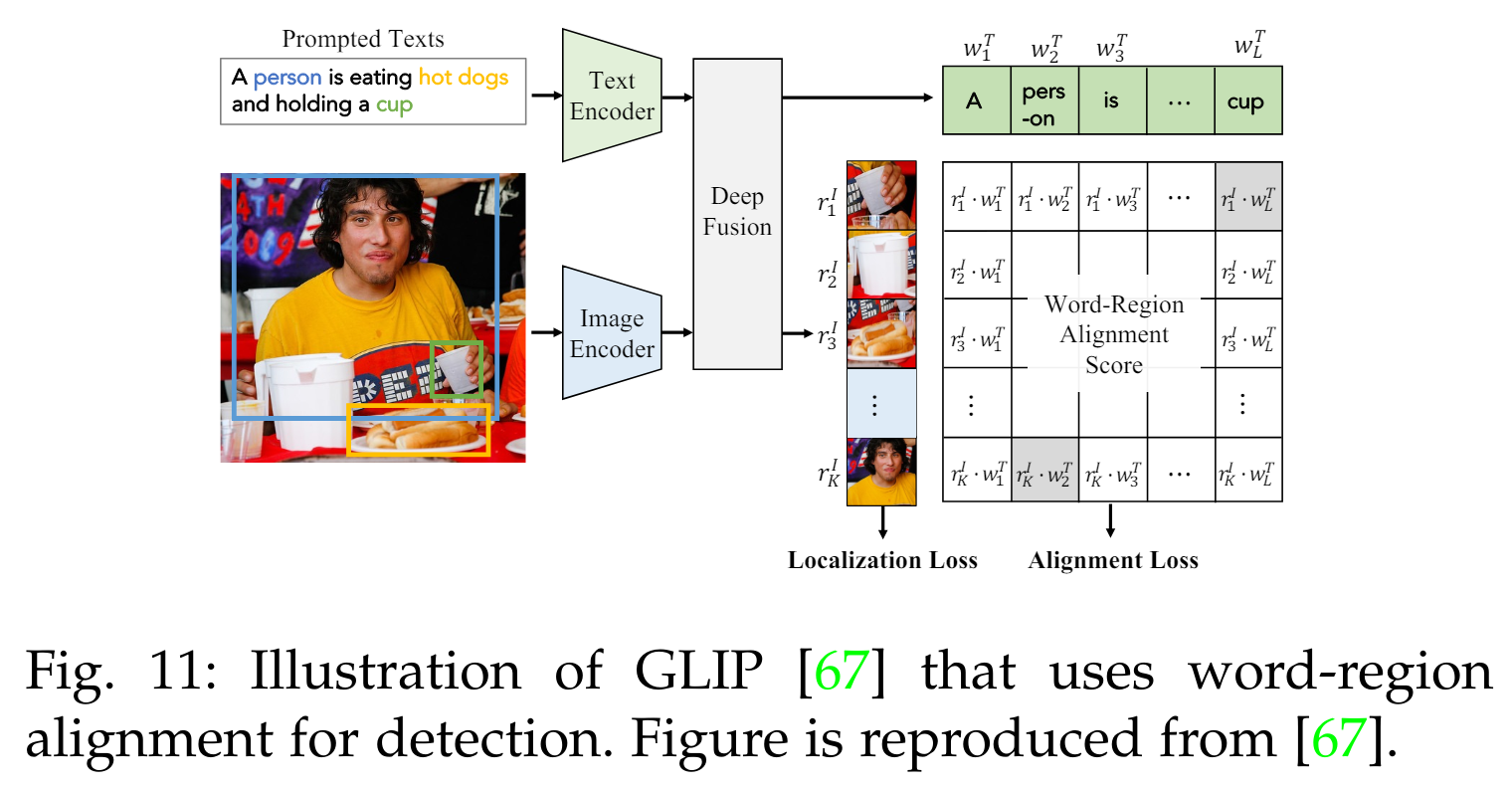
영역-단어 매칭 목표는 쌍을 이루는 이미지 영역과 단어 토큰을 정렬하여 로컬 세밀한 vision-language 상관관계를 모델링합니다. 이는 객체 탐지와 의미론적 분할에서 zero-shot 밀집 예측에 크게 도움이 됩니다. 예를 들어, GLIP [67], FIBER [71], DetCLIP [45]은 객체 분류 로짓을 영역-단어 정렬 점수로 대체합니다. 즉, 지역적 시각 특징과 토큰 단위 특징 간의 내적 유사도를 사용합니다(Fig. 11 참조).
5.3.3 논의 (Discussion)
정렬 목표는 주어진 이미지와 텍스트 데이터가 일치하는지 여부를 예측하는 방법을 학습합니다. 이는 단순하고 최적화하기 쉬우며, 이미지와 텍스트 데이터를 로컬에서 정렬하여 세밀한 vision-language 상관관계를 모델링하는 데 쉽게 확장될 수 있습니다. 반면에, 이러한 목표는 종종 비전 또는 언어 모달리티 내의 상관관계 정보를 거의 학습하지 못합니다. 따라서 정렬 목표는 종종 비전과 언어 모달리티 간의 상관관계 모델링을 강화하기 위해 다른 VLM 사전 학습 목표에 보조 손실로 채택됩니다 [42], [121].

5.4 요약 및 논의 (Summary and Discussion)
요약하자면, VLM 사전 학습은 이미지-텍스트 대조 학습, 마스크드 크로스 모달 모델링, 이미지-텍스트 생성, 이미지-텍스트/영역-단어 매칭과 같은 다양한 크로스 모달 목표를 통해 vision-language 상관관계를 모델링합니다. 또한, 이미지 모달리티에 대한 마스크드 이미지 모델링과 텍스트 모달리티에 대한 마스크드 언어 모델링과 같이 각각의 모달리티의 데이터 잠재력을 최대한 활용하기 위한 다양한 단일 모달 목표도 탐구되었습니다.
반면에, 최근 VLM 사전 학습은 이미지 분류와 같은 이미지 수준의 인식 작업에서 이점을 갖는 글로벌 vision-language 상관관계 학습에 중점을 둡니다. 동시에 여러 연구 [45], [46], [67], [71], [129], [130], [131]는 객체 탐지와 의미론적 분할에서 더 나은 밀집 예측을 목표로 영역-단어 매칭을 통해 로컬 세밀한 vision-language 상관관계를 모델링합니다.
6 VLM 전이 학습 (VLM Transfer Learning)
세부 조정(fine-tuning) 없이 사전 학습된 VLM을 다운스트림 작업에 직접 적용하는 zero-shot 예측을 넘어, 최근에는 전이 학습이 연구되고 있습니다. 이는 프롬프트 튜닝(prompt tuning) [31], [132], 특징 어댑터(feature adapter) [33], [34] 등을 통해 VLM을 다운스트림 작업에 맞게 조정하는 방법입니다. 이 섹션에서는 사전 학습된 VLM을 위한 전이 학습의 동기, 일반적인 전이 학습 설정, 그리고 프롬프트 튜닝 방법, 특징 어댑터 방법 및 기타 방법을 포함한 세 가지 전이 학습 접근법을 소개합니다.
특징 어댑터
특징 어댑터(Feature Adapter)는 사전 학습된 모델을 특정 다운스트림 작업에 맞게 조정하기 위해 사용되는 방법입니다. 이는 주로 전이 학습에서 사용되며, 사전 학습된 모델의 가중치를 고정하거나 최소한으로 변경하면서, 새로운 작업에 맞는 추가적인 레이어나 모듈을 학습시키는 방식입니다.
특징 어댑터의 주요 개념
- 기존 모델 고정: 사전 학습된 모델(예: VLM)의 대부분의 가중치는 고정되어 변경되지 않습니다. 이렇게 하면 사전 학습 동안 학습된 유용한 일반 특징을 보존할 수 있습니다.
- 어댑터 레이어 추가: 모델의 특정 층에 어댑터 레이어(adapter layer)라는 작은 신경망 모듈을 추가합니다. 이 어댑터 레이어는 다운스트림 작업에 필요한 새로운 특징을 학습합니다.
- 효율적인 학습: 어댑터 레이어의 파라미터 수가 상대적으로 적기 때문에, 전체 모델을 재학습하는 것보다 계산 비용이 적고 더 빠르게 학습할 수 있습니다.
특징 어댑터의 작동 방식
- 사전 학습된 모델 사용: 이미지나 텍스트와 같은 입력 데이터를 사전 학습된 모델에 입력합니다.
- 어댑터 레이어 추가: 특정 층(예: Transformer의 각 층)에 어댑터 레이어를 추가하여, 모델의 출력에 변형을 가합니다.
- 어댑터 학습: 어댑터 레이어만 학습시키고, 사전 학습된 모델의 나머지 부분은 고정합니다. 이를 통해 모델이 새로운 작업에 맞게 조정됩니다.
예시
- NLP에서의 어댑터: BERT와 같은 대형 언어 모델에 어댑터 레이어를 추가하여 특정 텍스트 분류 작업에 맞게 조정합니다.
- 컴퓨터 비전에서의 어댑터: ResNet과 같은 사전 학습된 이미지 분류 모델에 어댑터 레이어를 추가하여 새로운 이미지 분류 작업에 맞게 조정합니다.
장점
- 효율성: 모델의 일부만 학습하기 때문에 계산 비용과 시간이 절약됩니다.
- 유연성: 다양한 다운스트림 작업에 쉽게 적용할 수 있습니다.
- 성능 향상: 사전 학습된 모델의 일반 특징을 활용하면서, 새로운 작업에 필요한 세부 특징을 학습할 수 있습니다.
사용 예시
- 전이 학습에서의 적용: 사전 학습된 VLM 모델에 어댑터 레이어를 추가하여 이미지 분류, 객체 탐지, 의미론적 분할 등의 다양한 다운스트림 작업에 맞게 모델을 조정합니다.
- 다중 작업 학습: 동일한 사전 학습된 모델에 여러 어댑터 레이어를 추가하여, 다양한 작업을 동시에 학습할 수 있습니다.
특징 어댑터는 사전 학습된 모델을 다양한 새로운 작업에 맞게 효율적으로 조정하는 강력한 방법입니다.
6.1 전이 학습의 동기 (Motivation of Transfer Learning)
사전 학습된 VLM이 강력한 일반화 능력을 보여주었지만, 다양한 다운스트림 작업에 적용될 때 두 가지 유형의 격차에 직면합니다: 1) 이미지와 텍스트 분포의 격차. 예를 들어, 다운스트림 데이터셋은 작업 특화된 이미지 스타일과 텍스트 형식을 가질 수 있습니다. 2) 학습 목표의 격차. VLM은 일반적으로 작업 비특화 목표로 학습되어 일반적인 개념을 학습하는 반면, 다운스트림 작업은 종종 조잡하거나 세밀한 분류, 영역 또는 픽셀 수준의 인식을 포함한 작업 특화 목표를 포함합니다.
6.2 전이 학습의 일반적인 설정 (Common Setup of Transfer Learning)
섹션 6.1에서 설명한 도메인 격차를 완화하기 위해 세 가지 전이 설정이 탐구되었습니다. 여기에는 지도 전이(supervised transfer), 소수 샘플 지도 전이(few-shot supervised transfer) 및 비지도 전이(unsupervised transfer)가 포함됩니다. 지도 전이는 모든 라벨이 있는 다운스트림 데이터를 사용하여 사전 학습된 VLM을 세부 조정합니다. 소수 샘플 지도 전이는 적은 양의 라벨이 있는 다운스트림 샘플만 사용하여 더 효율적인 주석 작업을 수행합니다. 반면, 비지도 전이는 라벨이 없는 다운스트림 데이터를 사용하여 VLM을 세부 조정합니다. 이는 더 도전적이지만 VLM 전이 학습에 더 유망하고 효율적입니다.
6.3 일반적인 전이 학습 방법 (Common Transfer Learning Methods)
Table 4에 나와 있듯이, 기존 VLM 전이 방법은 프롬프트 튜닝(prompt tuning) 접근법, 특징 어댑터(feature adapter) 접근법, 그리고 기타 방법으로 크게 세 가지 범주로 분류됩니다.
6.3.1 프롬프트 튜닝을 통한 전이 학습 (Transfer via Prompt Tuning)
NLP에서의 "프롬프트 학습" [165]에 영감을 받아, 많은 VLM 프롬프트 학습 방법들이 사전 학습된 VLM을 세부 조정하지 않고 최적의 프롬프트를 찾아 VLM을 다운스트림 작업에 맞게 조정하기 위해 제안되었습니다. 대부분의 기존 연구는 텍스트 프롬프트 튜닝, 비주얼 프롬프트 튜닝, 텍스트-비주얼 프롬프트 튜닝의 세 가지 접근법을 따릅니다.

텍스트 프롬프트 튜닝을 통한 전이 학습 (Transfer with Text Prompt Tuning)
각 작업에 대해 수동으로 텍스트 프롬프트를 설계하는 프롬프트 엔지니어링 [165]과 달리, 텍스트 프롬프트 튜닝은 각 클래스에 대해 몇 개의 라벨이 있는 다운스트림 샘플을 사용하여 더 효과적이고 효율적인 학습 가능한 텍스트 프롬프트를 탐구합니다.
예를 들어, CoOp [31]은 학습 가능한 단어 벡터를 사용하여 단일 클래스 이름에 대한 컨텍스트 단어를 학습하는 컨텍스트 최적화를 탐구합니다. 이는 카테고리 단어 [label]을 문장 '[V]1, [V]2, ..., [V]m [label]'로 확장합니다. 여기서 [V]는 다운스트림 샘플로 분류 손실을 최소화하여 최적화되는 학습 가능한 단어 벡터를 나타냅니다(Fig. 12 (a) 참조). 프롬프트 학습에서 제한된 다운스트림 샘플로 인해 발생하는 과적합을 완화하기 위해, CoCoOp [32]는 각 이미지에 대한 특정 프롬프트를 생성하는 조건부 컨텍스트 최적화를 탐구합니다. SubPT [132]는 학습된 프롬프트의 일반화를 향상시키기 위해 서브스페이스 프롬프트 튜닝을 설계합니다. LASP [133]는 학습 가능한 프롬프트를 수동으로 설계된 프롬프트로 규제합니다. VPT [135]는 인스턴스별 분포로 텍스트 프롬프트를 모델링하여 다운스트림 작업에서 더 나은 일반화를 제공합니다. KgCoOp [145]는 텍스트 지식의 망각을 완화하여 보지 못한 클래스의 일반화를 향상시킵니다.
또한, SoftCPT [141]는 여러 few-shot 작업에서 VLM을 동시에 세부 조정하여 멀티태스크 학습의 이점을 제공합니다. PLOT [138]는 최적 수송을 사용하여 카테고리의 다양한 특성을 설명하는 여러 프롬프트를 학습합니다. DualCoOp [139]와 TaI-DP [140]는 멀티라벨 분류 작업으로 VLM을 전이시키며, DualCoOp는 멀티라벨 분류를 위해 긍정적 프롬프트와 부정적 프롬프트를 모두 채택하고, TaI-DP는 조잡한 임베딩과 세밀한 임베딩을 모두 캡처하기 위해 이중 그레이닝 프롬프트 튜닝을 도입합니다. DenseCLIP [142]는 밀집 예측을 위해 시각적 특징을 사용하여 텍스트 프롬프트를 튜닝하는 언어 기반 세부 조정을 탐구합니다 [55], [56]. ProTeCt [146]는 계층적 분류 작업에 대한 모델 예측의 일관성을 향상시킵니다.
지도 학습 및 소수 샘플 지도 프롬프트 학습을 넘어, 최근 연구들은 더 나은 주석 효율성과 확장성을 위해 비지도 프롬프트 튜닝을 탐구합니다. 예를 들어, UPL [143]는 선택된 의사 라벨 샘플에서 자기 학습을 통해 학습 가능한 프롬프트를 최적화합니다. TPT [144]는 단일 다운스트림 샘플에서 적응형 프롬프트를 학습하는 테스트 시 프롬프트 튜닝을 탐구합니다.
비주얼 프롬프트 튜닝을 통한 전이 학습 (Transfer with Visual Prompt Tuning)
텍스트 프롬프트 튜닝과 달리, 비주얼 프롬프트 튜닝(Visual Prompt Tuning) [148], [166]은 Fig. 12 (b)에서 보이는 것처럼 이미지 인코더의 입력을 조절하여 VLM을 전이시킵니다. 예를 들어, VP [147]는 학습 가능한 이미지 변형(perturbations) v 를 채택하여 입력 이미지 xI 를 xI+v 로 수정합니다. 이는 인식 손실을 최소화하도록 v를 조정하는 것을 목표로 합니다. RePrompt [148]는 비주얼 프롬프트 튜닝에 검색 메커니즘을 통합하여 다운스트림 작업의 지식을 활용할 수 있게 합니다. 비주얼 프롬프트 튜닝은 다운스트림 작업에 픽셀 수준의 적응을 가능하게 하여, 특히 밀집 예측 작업에 크게 도움이 됩니다.
텍스트-비주얼 프롬프트 튜닝을 통한 전이 학습 (Transfer with Text-Visual Prompt Tuning)
텍스트-비주얼 프롬프트 튜닝은 텍스트와 이미지 입력을 동시에 조절하여, 여러 모달리티에서 프롬프트 최적화의 이점을 얻는 것을 목표로 합니다. 예를 들어, UPT [149]는 프롬프트 튜닝을 통합하여 텍스트와 이미지 프롬프트를 공동으로 최적화하며, 두 프롬프트 튜닝 작업의 상호 보완성을 입증합니다. MVLPT [150]는 멀티태스크 비전-언어 프롬프트 튜닝을 탐구하여 크로스 태스크 지식을 텍스트 및 이미지 프롬프트 튜닝에 통합합니다. MAPLE [151]은 시각적 프롬프트를 해당하는 언어 프롬프트와 정렬하여 멀티모달 프롬프트 튜닝을 수행하며, 텍스트 프롬프트와 이미지 프롬프트 간의 상호 촉진을 가능하게 합니다. CAVPT [152]는 클래스 인식 시각적 프롬프트와 텍스트 프롬프트 간의 크로스 어텐션을 도입하여 시각적 프롬프트가 시각적 개념에 더 집중하도록 합니다.
프롬프트 최적화
프롬프트 최적화(Prompt Optimization)는 주어진 작업에서 모델의 성능을 향상시키기 위해 프롬프트(질의 또는 입력)를 자동으로 조정하고 학습하는 과정을 의미합니다. 이는 텍스트, 이미지, 또는 텍스트와 이미지를 동시에 조절하여 최적의 결과를 도출하는 것을 목표로 합니다. 프롬프트 최적화는 모델이 주어진 작업을 더 잘 수행할 수 있도록 프롬프트를 최적화하여 학습하는 방법입니다.
프롬프트 최적화의 주요 개념
- 프롬프트 엔지니어링(Prompt Engineering):
- 초기에는 사람이 수동으로 프롬프트를 설계하여 모델에 입력했습니다. 예를 들어, "a photo of a [label]"와 같은 문장을 만들었습니다.
- 이 방법은 시간이 많이 걸리고 비효율적일 수 있습니다.
- 학습 가능한 프롬프트(Learnable Prompts):
- 프롬프트 최적화는 모델이 학습 가능한 프롬프트를 자동으로 최적화하도록 합니다. 이는 모델이 주어진 작업에 대해 최적의 프롬프트를 스스로 학습할 수 있게 합니다.
- 예를 들어, '[V]1, [V]2, ..., [V]m [label]'에서 [V]는 학습 가능한 단어 벡터입니다. 모델은 이 단어 벡터를 학습하여 최적의 문장을 만듭니다.
- 컨텍스트 최적화(Context Optimization):
- 특정 클래스 이름 주위에 적절한 컨텍스트 단어를 학습하여 프롬프트의 품질을 향상시킵니다.
논의 (Discussion)
프롬프트 튜닝은 몇 개의 학습 가능한 텍스트/이미지 프롬프트를 사용하여 입력 텍스트/이미지를 수정함으로써 parameter-efficient VLM 전이를 가능하게 합니다. 이는 간단하고 구현이 용이하며, 추가적인 네트워크 레이어나 복잡한 네트워크 수정이 거의 필요하지 않습니다. 따라서 프롬프트 튜닝은 블랙박스 방식으로 VLM을 적응시키는 것을 가능하게 하며, 이는 지적 재산권 문제를 포함하는 VLM 전이에서 명확한 이점을 제공합니다. 그러나 여전히 몇 가지 한계가 있습니다. 예를 들어, 프롬프트 튜닝은 원래 VLM의 매니폴드를 따르는 낮은 유연성을 갖습니다 [31].
parameter-efficient
"Parameter-efficient"는 모델을 학습하거나 조정할 때, 파라미터의 수를 최소화하면서도 효과적으로 학습을 수행할 수 있는 방법을 의미합니다. 이는 주로 자원 절약과 효율성을 강조하는 접근 방식으로, 모델의 성능을 유지하거나 향상시키면서도 필요한 학습 가능한 파라미터의 수를 줄이는 것을 목표로 합니다.
Parameter-efficient의 주요 개념
- 적은 파라미터 사용:
- 모델의 전체 파라미터 중 일부만 학습하거나 조정합니다. 이는 전체 모델을 재학습하는 것보다 훨씬 적은 계산 자원과 시간이 소요됩니다.
- 예를 들어, 프롬프트 튜닝에서는 입력 텍스트나 이미지의 프롬프트만 학습 가능한 파라미터로 설정하고 나머지 모델은 고정합니다.
- 효율적인 학습:
- 제한된 파라미터를 효율적으로 학습하여, 모델이 특정 작업에서 높은 성능을 발휘할 수 있도록 합니다.
- 이는 특히 대규모 모델을 다양한 다운스트림 작업에 적용할 때 유용합니다.
- 경제성:
- 전체 모델을 조정하지 않고 일부 파라미터만 학습하기 때문에 계산 비용이 절약되고, 메모리 사용량도 감소합니다.
- 이는 특히 자원이 제한된 환경에서 중요한 이점입니다.
예시: 프롬프트 튜닝에서의 파라미터 효율성
- 프롬프트 튜닝:
- 텍스트 프롬프트 튜닝에서는 입력 텍스트에 추가되는 학습 가능한 단어 벡터만 조정합니다.
- 비주얼 프롬프트 튜닝에서는 입력 이미지에 추가되는 학습 가능한 이미지 변형만 조정합니다.
- 텍스트-비주얼 프롬프트 튜닝에서는 텍스트와 이미지 모두의 프롬프트를 동시에 조정합니다.
- 장점:
- 전체 모델을 재학습할 필요 없이, 특정 작업에 맞춰 프롬프트만 조정하여 빠르고 효율적인 학습을 가능하게 합니다.
- 추가적인 네트워크 레이어나 복잡한 네트워크 수정 없이도 모델의 성능을 향상시킬 수 있습니다.
한계
- 유연성 제한: 원래 VLM의 매니폴드를 따르기 때문에, 프롬프트 튜닝은 모델의 유연성을 제한할 수 있습니다.
- 작업 특화 부족: 제한된 파라미터만 조정하기 때문에, 특정 작업에 대한 완벽한 최적화는 어려울 수 있습니다.
파라미터 효율성은 특히 대규모 모델을 다양한 작업에 적용할 때 중요한 개념입니다. 이는 모델의 성능을 유지하면서도 자원 절약과 효율성을 극대화할 수 있는 방법을 제공합니다.
매니폴드
"VLM의 매니폴드를 따른다"는 말은 프롬프트 튜닝이 주어진 Vision-Language Model (VLM)의 기존 구조와 학습된 표현 공간(manifold)을 준수하면서 최적화된다는 것을 의미합니다. 즉, 프롬프트 튜닝은 모델의 기존 매니폴드, 즉 모델이 사전 학습 과정에서 형성한 고차원 표현 공간 내에서 작업하는 방식으로 작동합니다.
매니폴드란 무엇인가?
매니폴드(manifold)는 기하학에서 사용되는 용어로, 고차원 공간에서 데이터가 놓여 있는 저차원 곡면을 의미합니다. 머신 러닝에서는 학습된 모델이 데이터의 패턴을 고차원 공간에서 어떻게 표현하는지를 나타내는 데 사용됩니다.
VLM의 매니폴드를 따른다는 것의 의미
- 기존 구조 준수:
- 프롬프트 튜닝은 모델의 기존 구조와 표현 방식을 변경하지 않고, 그 안에서 최적의 프롬프트를 찾아내는 것을 목표로 합니다.
- 모델이 이미 학습한 특징 공간을 활용하여 새로운 작업에 맞추는 방식입니다.
- 학습된 표현 공간 내에서 작업:
- 사전 학습된 VLM은 이미지와 텍스트 간의 상관관계를 이미 특정한 방식으로 학습했습니다. 프롬프트 튜닝은 이 학습된 표현 공간 내에서 입력을 조정하여 최적화를 수행합니다.
- 새로운 작업에 맞춰 모델의 매니폴드 내에서 적절한 프롬프트를 찾아내어 사용합니다.
예시를 통한 이해
- 프롬프트 튜닝: 예를 들어, CoOp (Context Optimization) 방법에서는 "[V]1, [V]2, ..., [V]m [label]"과 같은 학습 가능한 단어 벡터를 추가합니다. 이 벡터들은 모델이 이미 학습한 표현 공간 내에서 조정됩니다.
- 유연성 제한: 프롬프트 튜닝은 모델이 이미 학습한 매니폴드 내에서 작업하기 때문에, 모델의 기본 구조나 표현 방식을 벗어나지 않습니다. 이는 모델의 유연성을 제한할 수 있습니다. 즉, 모델이 사전 학습 중 학습한 방식에 크게 의존하게 됩니다.
장점과 한계
- 장점:
- 효율성: 전체 모델을 재학습하지 않고, 기존 모델의 구조와 표현 공간을 최대한 활용합니다.
- 간편성: 복잡한 네트워크 수정 없이 프롬프트만 조정하여 새로운 작업에 맞출 수 있습니다.
- 한계:
- 유연성 부족: 모델의 기존 매니폴드를 벗어나지 않기 때문에, 새로운 작업에 대한 완벽한 적응이 어려울 수 있습니다.
- 작업 특화 어려움: 특정 작업에 최적화된 구조나 표현 방식을 필요로 할 때, 기존 매니폴드를 따르는 접근법은 한계가 있을 수 있습니다.
결론적으로, "VLM의 매니폴드를 따른다"는 프롬프트 튜닝이 사전 학습된 모델의 기존 학습 패턴과 표현 방식을 최대한 활용하여 효율적으로 전이 학습을 수행한다는 것을 의미합니다. 이 접근법은 자원 효율적이고 간편하지만, 유연성 면에서 제약이 있을 수 있습니다.
6.3.2 특징 어댑터를 통한 전이 학습 (Transfer via Feature Adaptation)
특징 어댑터(Feature Adaptation)는 추가적인 경량 특징 어댑터를 사용하여 VLM의 이미지나 텍스트 특징을 조정합니다 [167]. 예를 들어, Clip-Adapter [33]는 CLIP의 언어 및 이미지 인코더 뒤에 몇 개의 학습 가능한 선형 레이어를 삽입하고, CLIP 아키텍처와 파라미터를 고정한 상태로 이를 최적화합니다(Fig. 13 참조). Tip-Adapter [34]는 few-shot 라벨이 있는 이미지의 임베딩을 어댑터 가중치로 직접 사용하는 학습 없는 어댑터를 제시합니다. SVL-Adapter [153]는 입력 이미지에 대해 자가 지도 학습을 수행하기 위해 추가적인 인코더를 사용하는 자가 지도 어댑터를 설계합니다. 요약하면, 특징 어댑터는 이미지와 텍스트 특징을 조정하여 VLM을 다운스트림 데이터에 맞추며, 이는 VLM 전이를 위한 프롬프트 튜닝의 유망한 대안입니다.
논의 (Discussion)
특징 어댑터는 추가적인 경량 특징 어댑터를 사용하여 이미지와 텍스트 특징을 조정함으로써 VLM을 적응시킵니다. 이 방법은 다양한 다운스트림 작업에 유연하게 맞춤 설정할 수 있는 아키텍처와 삽입 방식을 제공하여 유연하고 효과적입니다. 따라서, 특징 어댑터는 매우 다르고 복잡한 다운스트림 작업에서 VLM을 적응시키는 데 명확한 장점을 가지고 있습니다 [168], [169], [170], [171]. 반면, 네트워크 아키텍처를 수정해야 하므로 지적 재산권 문제를 포함하는 VLM을 처리할 수 없습니다.
6.3.3 기타 전이 학습 방법 (Other Transfer Methods)
여러 연구들은 직접적인 세부 조정(fine-tuning) [162], 아키텍처 수정 [163], 크로스 어텐션 [157], [158]을 통해 VLM을 전이시킵니다. 구체적으로, Wise-FT [162]는 세부 조정된 VLM과 원래 VLM의 가중치를 결합하여 다운스트림 작업에서 새로운 정보를 학습합니다. MaskCLIP [163]은 CLIP 이미지 인코더의 아키텍처를 수정하여 밀집 이미지 특징을 추출합니다. VT-CLIP [157]은 시각적 유도 어텐션을 도입하여 텍스트 특징을 다운스트림 이미지와 의미적으로 연관시켜 전이 성능을 향상시킵니다. CALIP [158]은 시각적 특징과 텍스트 특징 간의 효과적인 상호작용과 소통을 위해 파라미터 없는 어텐션을 도입하여 텍스트 인식 이미지 특징과 시각적 유도 텍스트 특징을 만듭니다. TaskRes [159]는 텍스트 기반 분류기를 직접 조정하여 사전 학습된 VLM의 기존 지식을 활용합니다. CuPL [160]과 VCD [161]는 GPT-3 [172]와 같은 대형 언어 모델을 사용하여 텍스트 프롬프트를 증강함으로써 풍부한 구별 텍스트 정보를 학습합니다.
크로스 어텐션
크로스 어텐션(Cross Attention)은 멀티모달 모델링에서 한 모달리티의 정보가 다른 모달리티의 정보를 주의(attention)하여 상호작용할 수 있도록 하는 기법입니다. 이는 두 가지 서로 다른 데이터 유형(예: 텍스트와 이미지)이 서로의 정보에 집중하고, 이를 바탕으로 더 풍부하고 의미 있는 특징을 학습할 수 있게 합니다.
크로스 어텐션의 주요 개념
- 어텐션 메커니즘:
- 어텐션 메커니즘은 모델이 입력 시퀀스의 다른 부분에 가중치를 부여하여 중요한 부분에 더 집중할 수 있게 하는 방법입니다. 이는 주로 시퀀스-투-시퀀스(seq2seq) 모델에서 사용됩니다.
- 크로스 어텐션:
- 크로스 어텐션은 서로 다른 두 모달리티(예: 텍스트와 이미지) 간의 상호작용을 촉진합니다.
- 예를 들어, 텍스트와 이미지가 주어졌을 때, 텍스트의 각 단어가 이미지의 각 부분(패치)에 주의를 기울이도록 하여 이미지의 정보를 텍스트에 통합합니다.
크로스 어텐션의 작동 방식
- 입력:
- 두 가지 서로 다른 모달리티의 입력(예: 텍스트와 이미지)이 주어집니다.
- 어텐션 계산:
- 텍스트 특징과 이미지 특징 간의 어텐션 점수를 계산합니다. 이 점수는 각 텍스트 토큰이 이미지의 각 패치에 얼마나 주의를 기울여야 하는지를 나타냅니다.
- 어텐션 점수는 주로 내적(dot product) 또는 유사도 계산을 통해 얻어집니다.
- 가중합:
- 어텐션 점수를 사용하여 이미지의 특징을 가중합하여 텍스트 특징에 통합합니다. 이를 통해 텍스트와 이미지 간의 상호작용이 이루어집니다.
- 출력:
- 크로스 어텐션을 통해 조정된 텍스트 특징과 이미지 특징을 사용하여 최종 예측을 수행합니다.
예시
- VT-CLIP:
- VT-CLIP [157]은 시각적 유도 어텐션을 도입하여 텍스트 특징을 다운스트림 이미지와 의미적으로 연관시킵니다. 이를 통해 텍스트와 이미지 간의 상관관계를 강화하여 전이 성능을 향상시킵니다.
- CALIP:
- CALIP [158]은 파라미터 없는 어텐션을 도입하여 시각적 특징과 텍스트 특징 간의 상호작용과 소통을 촉진합니다. 이는 텍스트 인식 이미지 특징과 시각적 유도 텍스트 특징을 만듭니다.
크로스 어텐션의 장점
- 멀티모달 상호작용: 서로 다른 모달리티 간의 정보 교환을 촉진하여 더 풍부하고 의미 있는 특징을 학습할 수 있습니다.
- 유연성: 다양한 멀티모달 작업에서 사용할 수 있으며, 텍스트-이미지 매칭, 이미지 캡셔닝 등 다양한 응용 분야에 적용할 수 있습니다.
한계
- 복잡성 증가: 추가적인 어텐션 계산으로 인해 모델의 복잡성과 계산 비용이 증가할 수 있습니다.
- 데이터 요구: 두 모달리티 간의 효과적인 상호작용을 위해 많은 양의 데이터가 필요할 수 있습니다.
결론적으로, 크로스 어텐션은 멀티모달 모델링에서 중요한 역할을 하며, 텍스트와 이미지 간의 상호작용을 통해 더 나은 특징 학습과 예측 성능을 제공합니다. 추가로 궁금한 점이나 더 자세한 설명이 필요하면 언제든지 말씀해 주세요!
6.4 요약 및 논의 (Summary and Discussion)
요약하자면, 프롬프트 튜닝과 특징 어댑터는 VLM 전이를 위한 두 가지 주요 접근 방식으로, 각각 입력 텍스트/이미지를 수정하고 이미지/텍스트 특징을 조정하여 작동합니다. 이 두 접근 방식은 원래 VLM을 고정한 상태에서 매우 제한된 파라미터를 도입하여 효율적인 전이를 가능하게 합니다. 또한, 대부분의 연구가 소수 샘플 지도 전이(few-shot supervised transfer) [31], [32], [132], [134]를 따르고 있지만, 최근 연구들은 비지도 VLM 전이(unsupervised VLM transfer)가 다양한 작업에서 경쟁력 있는 성능을 달성할 수 있음을 보여주고 있으며 [143], [144], [160], 이는 비지도 VLM 전이에 대한 더 많은 연구를 고무합니다.
소수 샘플 지도 전이(few-shot supervised transfer)
Few-shot Supervised Transfer
Few-shot supervised transfer는 소수의 라벨이 있는 데이터를 사용하여 사전 학습된 모델을 새로운 작업에 맞게 조정하는 방법입니다. 이 접근 방식은 특히 라벨링된 데이터가 제한적인 상황에서 유용합니다.
주요 개념
- Few-shot Learning:
- 모델이 소수의 학습 샘플만으로도 새로운 작업을 학습할 수 있도록 하는 기법입니다. 예를 들어, 1-shot 학습은 각 클래스에 대해 단 하나의 학습 샘플만 사용하고, 5-shot 학습은 다섯 개의 학습 샘플을 사용합니다.
- Supervised Learning:
- 지도 학습은 각 입력 데이터에 대응하는 라벨이 제공되는 학습 방식입니다. 모델은 입력과 라벨 쌍을 통해 학습하여 새로운 입력에 대해 올바른 예측을 할 수 있도록 훈련됩니다.
- Few-shot Supervised Transfer:
- 사전 학습된 VLM을 소수의 라벨이 있는 데이터로 세부 조정(fine-tuning)하여 새로운 작업에 적용하는 방법입니다. 모델은 기존의 일반적인 지식을 활용하면서, 소수의 라벨이 있는 데이터로 작업 특화된 지식을 학습합니다.
예시
- CoOp (Context Optimization):
- 학습 가능한 단어 벡터를 최적화하여 컨텍스트 단어를 학습합니다. 예를 들어, "[label]"을 "[V]1, [V]2, ..., [V]m [label]"로 확장하여 모델이 더 정확한 예측을 할 수 있도록 합니다.
- Tip-Adapter:
- Few-shot 라벨이 있는 이미지의 임베딩을 어댑터 가중치로 사용하여 추가 학습 없이 모델을 조정합니다.
- SoftCPT (Soft Contextual Prompt Tuning):
- 여러 few-shot 작업에서 동시에 프롬프트 튜닝을 수행하여 멀티태스크 학습의 이점을 제공합니다.
장점
- 효율성: 적은 양의 라벨이 있는 데이터로도 모델을 효과적으로 조정할 수 있어 데이터 수집 및 라벨링 비용이 절감됩니다.
- 적용성: 다양한 작업에 쉽게 적용할 수 있으며, 사전 학습된 모델의 지식을 활용하여 빠르게 학습할 수 있습니다.
한계
- 성능 제한: 소수의 라벨이 있는 데이터로 학습할 때 성능이 제한될 수 있으며, 모델이 충분히 일반화되지 않을 수 있습니다.
- 데이터 품질 의존: 라벨이 있는 데이터의 품질이 낮으면 모델의 성능에 부정적인 영향을 미칠 수 있습니다.
비지도 VLM 전이(unsupervised VLM transfer)
Unsupervised VLM Transfer
Unsupervised VLM transfer는 라벨이 없는 데이터(unlabeled data)를 사용하여 사전 학습된 VLM을 새로운 작업에 맞게 조정하는 방법입니다. 이는 라벨링된 데이터가 전혀 없거나 매우 제한적인 상황에서 유용합니다.
주요 개념
- Unsupervised Learning:
- 지도 학습과 달리, 라벨이 없는 데이터를 사용하여 모델을 학습하는 방법입니다. 모델은 데이터의 패턴을 스스로 발견하고, 이를 기반으로 학습합니다.
- Self-Training:
- 모델이 자신이 예측한 라벨(의사 라벨, pseudo-label)을 사용하여 학습하는 방법입니다. 초기 모델이 라벨을 생성하고, 이를 사용하여 다시 학습합니다.
- Unsupervised VLM Transfer:
- 라벨이 없는 데이터를 사용하여 사전 학습된 VLM을 새로운 작업에 맞게 조정합니다. 모델은 기존의 일반적인 지식을 활용하면서, 라벨이 없는 데이터를 통해 작업 특화된 지식을 학습합니다.
예시
- UPL (Unsupervised Prompt Learning):
- 선택된 의사 라벨 샘플에서 자기 학습을 통해 학습 가능한 프롬프트를 최적화합니다.
- TPT (Test-time Prompt Tuning):
- 단일 다운스트림 샘플에서 적응형 프롬프트를 학습하는 테스트 시 프롬프트 튜닝을 탐구합니다.
장점
- 주석 효율성: 라벨링된 데이터가 필요 없기 때문에, 데이터 주석 비용이 절감됩니다.
- 스케일링: 라벨이 없는 대규모 데이터셋을 사용하여 모델을 쉽게 확장할 수 있습니다.
한계
- 초기 모델 의존성: 초기 모델의 성능에 따라 의사 라벨의 품질이 결정되며, 이로 인해 학습이 영향을 받을 수 있습니다.
- 학습 불안정성: 라벨이 없는 데이터로 학습할 때, 모델이 잘못된 패턴을 학습할 가능성이 있습니다.
Few-shot supervised transfer와 unsupervised VLM transfer는 각각 라벨이 있는 데이터와 없는 데이터를 사용하여 모델을 새로운 작업에 맞게 조정하는 두 가지 주요 접근 방식입니다. 두 방법 모두 데이터가 제한된 환경에서 모델의 성능을 극대화할 수 있는 강력한 도구입니다.
7 VLM 지식 증류 (VLM Knowledge Distillation)
VLM는 광범위한 시각 및 텍스트 개념을 포괄하는 일반화 가능한 지식을 포착합니다. 여러 연구에서는 객체 탐지 및 의미론적 분할과 같은 복잡한 밀집 예측 작업을 처리하면서 일반적이고 강력한 VLM 지식을 증류하는 방법을 탐구합니다. 이 섹션에서는 VLM에서 지식을 증류하는 동기와 의미론적 분할 및 객체 탐지 작업에 대한 두 그룹의 지식 증류 연구를 소개합니다.
VLM 지식 증류
VLM 지식 증류(Knowledge Distillation from Vision-Language Models)는 사전 학습된 VLM의 지식(이미지와 텍스트 간의 상관관계 및 표현)을 더 작은 모델이나 특정 작업에 최적화된 모델에 전이시키는 과정을 의미합니다. 이 과정은 주로 복잡한 밀집 예측 작업(예: 객체 탐지, 의미론적 분할)에서 강력한 성능을 얻기 위해 사용됩니다.
주요 개념
- 지식 증류(Knowledge Distillation):
- 지식 증류는 큰 사전 학습된 모델(교사 모델)의 지식을 더 작은 모델(학생 모델)로 전이하는 방법입니다. 교사 모델의 예측을 학생 모델이 모방하도록 학습하여, 학생 모델이 교사 모델의 성능을 일부 유지하거나 향상할 수 있도록 합니다.
- Hinton et al. (2015)에 의해 처음 제안된 이 방법은 주로 모델 경량화와 성능 향상을 위해 사용됩니다.
- VLM 지식 증류의 목적:
- VLMs는 대규모 이미지-텍스트 데이터셋으로 학습되어 다양한 시각 및 언어 개념을 포괄하는 일반화된 지식을 가지고 있습니다.
- 이러한 VLM의 지식을 특정 작업(예: 객체 탐지, 의미론적 분할)에 최적화된 모델로 전이하여 성능을 향상시키는 것이 목적입니다.
VLM 지식 증류의 과정
- 교사 모델(VLM):
- CLIP과 같은 사전 학습된 VLM은 이미지와 텍스트 간의 상관관계를 학습하여 매우 광범위한 어휘를 이해할 수 있습니다.
- 이 교사 모델의 지식을 이용하여 특정 작업에 필요한 정보를 학생 모델로 증류합니다.
- 학생 모델:
- 더 작은 크기의 모델이거나 특정 작업(예: 객체 탐지, 의미론적 분할)에 최적화된 모델입니다.
- 교사 모델의 출력을 모방하여 학습합니다.
- 지식 증류 방법:
- 로지츠 증류: 교사 모델의 출력 로지츠(logits)를 학생 모델이 모방하도록 학습합니다.
- 특징 맵 증류: 교사 모델의 중간 레이어에서 추출한 특징 맵(feature map)을 학생 모델이 모방하도록 학습합니다.
- 크로스 모달 증류: 텍스트와 이미지 간의 상관관계를 포함한 다양한 정보를 학생 모델에 전이합니다.
예시
- ViLD (Vision-Language Distillation for Detection):
- ViLD는 VLM 지식을 두 단계 탐지기로 증류하여, 임베딩 공간이 CLIP 이미지 인코더와 일치하도록 합니다.
- 이는 학생 모델이 교사 모델의 강력한 이미지-텍스트 상관관계를 학습하도록 도와줍니다.
- HierKD (Hierarchical Knowledge Distillation):
- HierKD는 계층적 글로벌-로컬 지식 증류를 통해 더 정교한 지식 전이를 수행합니다.
- 글로벌(전체 이미지 수준)과 로컬(부분 이미지 수준) 정보를 함께 사용하여 학생 모델을 학습시킵니다.
- PromptDet:
- 지역 프롬프트 학습을 통해 단어 임베딩을 지역 이미지 임베딩과 정렬하는 방법을 사용합니다.
- 프롬프트 학습을 통해 VLM의 지식을 학생 모델에 효과적으로 전이합니다.
장점
- 모델 경량화: 더 작은 모델이 강력한 성능을 유지하면서도 경량화됩니다.
- 작업 특화 성능 향상: 특정 작업에 최적화된 모델이 더욱 우수한 성능을 발휘합니다.
- 효율적 학습: 대규모 데이터셋 없이도 사전 학습된 VLM의 지식을 활용하여 효과적으로 학습할 수 있습니다.
한계
- 복잡한 설정: 지식 증류를 효과적으로 수행하기 위해서는 교사 모델과 학생 모델 간의 복잡한 설정이 필요할 수 있습니다.
- 성능 한계: 학생 모델이 교사 모델의 모든 능력을 완전히 모방하지 못할 수 있습니다.
VLM 지식 증류는 사전 학습된 대규모 모델의 지식을 활용하여 더 작은 모델이나 특정 작업에 최적화된 모델의 성능을 향상시키는 강력한 방법입니다.
7.1 VLM에서 지식을 증류하는 동기 (Motivation of Distilling Knowledge from VLMs)
일반적으로 원래의 VLM 아키텍처를 전이 과정에서 그대로 유지하는 VLM 전이와 달리 [31], [132], [136], VLM 지식 증류는 VLM 아키텍처의 제약 없이 일반적이고 강력한 VLM 지식을 작업 특화 모델로 증류합니다. 이는 다양한 밀집 예측 작업을 처리하면서 작업 특화 설계의 이점을 제공합니다 [36], [173], [174]. 예를 들어, 지식 증류를 통해 Faster R-CNN [55] 및 DETR [62]와 같은 최신 탐지 아키텍처의 이점을 활용하면서 탐지 작업을 처리하는 일반적인 VLM 지식을 전이할 수 있습니다.
7.2 일반적인 지식 증류 방법 (Common Knowledge Distillation Methods)
VLM는 일반적으로 이미지 수준의 표현을 위한 아키텍처와 목표로 사전 학습되므로, 대부분의 VLM 지식 증류 방법은 객체 탐지 및 의미론적 분할과 같은 영역 또는 픽셀 수준 작업으로 이미지 수준의 지식을 전이하는 데 중점을 둡니다. Table 5에는 VLM 지식 증류 방법 목록이 나와 있습니다.
7.2.1 객체 탐지를 위한 지식 증류 (Knowledge Distillation for Object Detection)
Open-vocabulary 객체 탐지(Open-vocabulary object detection) [193]는 기본 클래스 이외의 임의의 텍스트로 설명된 객체, 즉 모든 카테고리의 객체를 탐지하는 것을 목표로 합니다. CLIP과 같은 VLMs는 매우 광범위한 어휘를 포괄하는 수십억 개의 이미지-텍스트 쌍으로 학습되기 때문에, 많은 연구에서 탐지기의 어휘를 확장하기 위해 VLM 지식을 증류하는 방법을 탐구하고 있습니다. 예를 들어, ViLD [36]는 VLM 지식을 두 단계 탐지기로 증류하여, 그 임베딩 공간이 CLIP 이미지 인코더의 임베딩 공간과 일치하도록 합니다. ViLD를 따라, HierKD [186]는 계층적 글로벌-로컬 지식 증류를 탐구하고, RKD [187]는 영역 수준과 이미지 수준 임베딩을 더 잘 정렬하기 위해 영역 기반 지식 증류를 탐구합니다. ZSD-YOLO [198]는 CLIP을 활용하여 객체 탐지를 개선하기 위해 자기 라벨링 데이터 증강을 도입합니다. OADP [201]는 맥락적 지식을 전이하는 동안 제안 특징을 보존합니다. BARON [200]은 개별 영역 대신 영역의 집합을 증류하기 위해 이웃 샘플링을 사용합니다. RO-ViT [199]는 오픈 보캐블러리 탐지를 위해 VLMs로부터 지역 정보를 증류합니다.
다른 연구는 프롬프트 학습을 통한 VLM 증류를 탐구합니다 [165]. 예를 들어, DetPro [37]는 오픈 보캐블러리 객체 탐지를 위해 연속적인 프롬프트 표현을 학습하는 탐지 프롬프트 기술을 도입합니다. PromptDet [188]는 단어 임베딩을 지역 이미지 임베딩과 정렬하기 위해 지역 프롬프트 학습을 도입합니다. 또한, 여러 연구 [180], [181], [189], [194], [197]는 객체 탐지기를 개선하기 위해 VLM이 예측한 의사 라벨을 탐구합니다. 예를 들어, PB-OVD [189]는 VLM이 예측한 의사 경계 상자를 사용하여 객체 탐지기를 학습하고, XPM [194]은 오픈 보캐블러리 인스턴스 분할을 위해 VLM이 생성한 의사 마스크를 사용하는 강력한 크로스 모달 의사 라벨링 전략을 도입합니다. P3OVD [197]는 세밀한 프롬프트 튜닝으로 VLM이 생성한 의사 라벨을 정제하는 프롬프트 기반 자기 학습을 활용합니다.
7.2.2 Knowledge Distillation for Semantic Segmentation
지식 증류(Knowledge distillation)를 활용한 open-vocabulary 의미 분할(semantic segmentation)은 VLMs(vision-language models)를 이용해 세그먼트 모델의 어휘를 확장하여, 기본 클래스 외의 임의의 텍스트로 설명된 픽셀들을 분할하는 것을 목표로 합니다. 예를 들어, [35], [180], [181]은 먼저 클래스에 구애받지 않는(class-agnostic) 세그먼트를 통해 픽셀을 여러 세그먼트로 그룹화한 후, CLIP을 사용하여 세그먼트를 인식함으로써 open-vocabulary 의미 분할을 달성합니다. CLIPSeg [175]는 CLIP을 의미 분할에 확장하기 위해 가벼운 트랜스포머 디코더를 도입합니다. LSeg [176]는 세그먼트 모델이 인코딩한 픽셀 단위 이미지 임베딩과 CLIP 텍스트 임베딩 간의 상관관계를 극대화합니다. ZegCLIP [174]은 CLIP을 사용해 의미 마스크를 생성하고, 기본 클래스에 대한 과적합을 완화하기 위해 관계 서술자를 도입합니다. MaskCLIP+ [163]와 SSIW [177]는 VLM이 예측한 픽셀 수준의 의사 레이블을 통해 지식을 증류합니다. FreeSeg [185]는 먼저 마스크 제안을 생성한 후, zero-shot 분류를 수행합니다.
약한 지도 학습(weakly-supervised)을 활용한 의미 분할을 위한 지식 증류는 VLMs와 약한 지도(예: 이미지 수준의 레이블)를 모두 활용하여 의미 분할을 수행하는 것을 목표로 합니다. 예를 들어, CLIP-ES [184]는 소프트맥스 함수와 클래스 인식 주의 기반 애피니티 모듈(affinity module)을 설계하여 카테고리 혼동 문제를 완화함으로써 클래스 활성화 맵을 개선하기 위해 CLIP을 사용합니다. CLIMS [183]는 더 나은 약한 지도 학습 의미 분할을 위해 고품질의 클래스 활성화 맵을 생성하기 위해 CLIP 지식을 활용합니다.
애피니티 모듈
애피니티 모듈(affinity module)은 이미지나 데이터의 특정 요소들 사이의 유사도나 관련성을 측정하고 활용하는 기술입니다. 이 모듈은 주로 이미지의 각 부분(픽셀 또는 세그먼트) 간의 연관성을 평가하여 보다 정확한 분할을 가능하게 합니다.
예를 들어, 이미지의 한 부분이 "고양이"로 분류되면, 애피니티 모듈은 그 주변의 다른 픽셀들도 "고양이"와 유사한 특성을 가지고 있는지를 평가합니다. 이를 통해 분류의 정확성을 높이고, 잘못된 분류를 줄이는 데 도움이 됩니다. 특히, 약한 지도 학습에서는 이미지 전체에 대한 정확한 레이블이 없기 때문에 이런 모듈이 더욱 중요합니다.
CLIP-ES에서 언급된 애피니티 모듈은 클래스 인식(class-aware) 기반으로, 특정 클래스에 속하는 픽셀들 간의 연관성을 더욱 정밀하게 측정하고 활용하여 카테고리 혼동 문제를 완화합니다. 예를 들어, "고양이"와 "개"가 섞여 있는 이미지에서 애피니티 모듈은 각 픽셀의 문맥을 고려해 더 정확한 클래스 활성화 맵을 생성합니다.

7.3 요약 및 토론
또한, VLM 전이(VLM transfer)와 비교할 때, VLM 지식 증류는 원래의 VLM과 상관없이 다양한 다운스트림 네트워크를 허용하는 더 나은 유연성을 명확히 가지고 있습니다.


8 성능 비교
이 섹션에서는 섹션 5-7에서 검토한 VLM(vision-language model)의 사전 학습, 전이 학습, 지식 증류 방법을 비교, 분석 및 논의합니다.
8.1 VLM 사전 학습 성능
섹션 3.4에서 논의한 바와 같이, zero-shot 예측은 특정 과제에 대한 미세 조정 없이 VLM의 일반화 성능을 평가하는 널리 채택된 평가 방식입니다. 이 하위 섹션에서는 이미지 분류, 객체 탐지 및 의미 분할을 포함한 다양한 시각 인식 과제에서 zero-shot 예측 성능을 제시합니다.
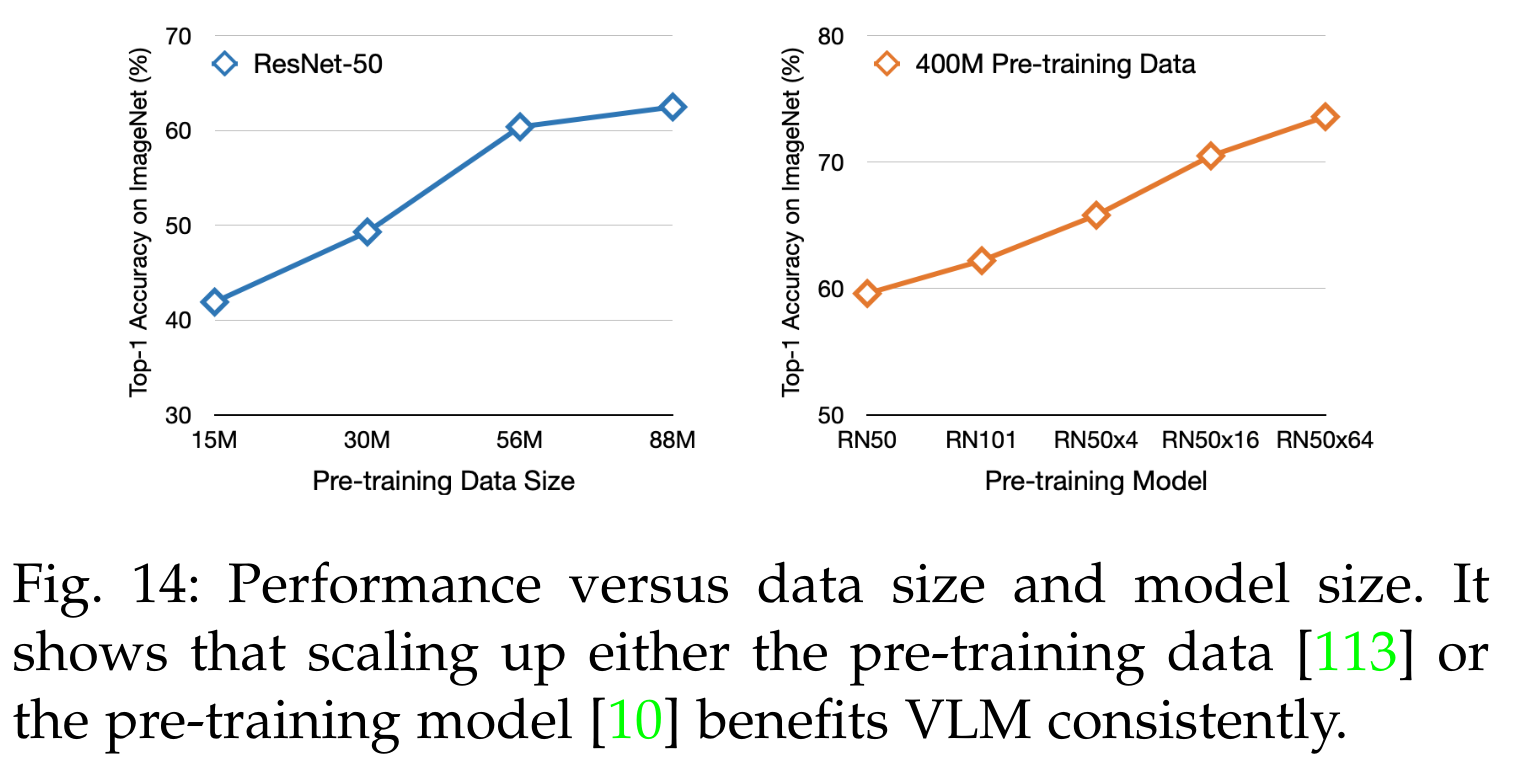
표 6은 11개의 널리 채택된 이미지 분류 과제에 대한 평가를 보여줍니다. VLM 사전 학습은 종종 다른 구현을 가지고 있기 때문에 가장 좋은 VLM 성능을 보여줍니다. 표 6과 그림 14에서 세 가지 결론을 도출할 수 있습니다:
- VLM 성능은 대체로 학습 데이터의 크기에 달려 있습니다. 그림 14의 첫 번째 그래프에서 보이는 바와 같이, 사전 학습 데이터를 확장하면 일관된 개선이 이루어집니다.
- VLM 성능은 대체로 모델 크기에 달려 있습니다. 두 번째 그래프에서 보이는 바와 같이, 동일한 사전 학습 데이터로 모델 크기를 확장하면 VLM 성능이 일관되게 향상됩니다.
- 대규모 이미지-텍스트 학습 데이터로, VLM은 다양한 다운스트림 작업에서 뛰어난 zero-shot 성능을 달성할 수 있습니다. 표 6에서 COCA [19]는 ImageNet에서 최고 성능을 달성하고, FILIP [18]는 11개의 과제에서 일관되게 좋은 성능을 보입니다.
VLM의 뛰어난 일반화 성능은 주로 세 가지 요인에 기인합니다:
- 대규모 데이터: 인터넷에는 이미지-텍스트 쌍이 거의 무한하게 존재하므로, VLM은 매우 광범위한 시각 및 언어 개념을 포괄하는 수백만 또는 수십억 개의 이미지와 텍스트 샘플로 학습됩니다.
- 대규모 모델: 전통적인 시각 인식 모델과 비교하여, VLM은 일반적으로 훨씬 큰 모델을 채택하여(예: COCA [19]의 ViT-G는 20억 매개변수를 가짐) 대규모 데이터로부터 효과적으로 학습할 수 있는 큰 용량을 제공합니다.
- 과제 비특정 학습(task-agnostic learning): VLM 사전 학습의 지도(supervision)는 일반적이고 과제 비특정적입니다. 전통적인 시각 인식에서의 과제 특정 레이블과 비교하여, 이미지-텍스트 쌍의 텍스트는 과제 비특정적이고 다양한 정보를 제공하여 다양한 다운스트림 작업에서 잘 작동하는 일반화 가능한 모델을 학습하는 데 도움이 됩니다.
몇몇 연구들 [45], [46], [67], [71], [129], [131]은 지역-단어 매칭(region-word matching)과 같은 지역 VLM 사전 학습 목표로 객체 탐지 및 의미 분할에 대한 VLM 사전 학습을 조사합니다. 표 7과 8은 객체 탐지 및 의미 분할 과제에서의 zero-shot 예측 성능을 요약합니다. VLM이 두 밀집 예측 과제에서 효과적인 zero-shot 예측을 가능하게 함을 알 수 있습니다. 표 7과 8의 결과는 이 연구 분야가 매우 제한된 VLM을 가지고 있어 많이 탐구되지 않았기 때문에 앞서 언급한 결론과 일치하지 않을 수 있습니다.
VLM의 한계
위에서 논의한 바와 같이, 데이터 및 모델 크기가 증가함에 따라 VLM이 명확한 이점을 가지지만, 다음과 같은 몇 가지 한계도 있습니다:
- 데이터 및 모델 크기가 계속 증가하면 성능이 포화 상태에 이르러 추가 확장이 성능을 향상시키지 않습니다 [113], [202].
- VLM 사전 학습에서 대규모 데이터를 채택하면 방대한 계산 자원이 필요합니다. 예를 들어, CLIP ViT-L [10]에서는 256개의 V100 GPU와 288시간의 학습 시간이 필요합니다.
- 대규모 모델을 채택하면 학습 및 추론에서 과도한 계산 및 메모리 오버헤드가 발생합니다.
과제 비특정 학습
과제 비특정 학습(task-agnostic learning)은 특정 과제에 맞춘 데이터나 레이블이 아니라, 다양한 과제에 적용할 수 있는 일반적인 데이터나 레이블을 사용하여 모델을 학습하는 것을 의미합니다.
VLM(vision-language model)의 경우, 과제 비특정 학습은 이미지와 텍스트 쌍을 이용하여 모델을 학습합니다. 이 텍스트는 특정 시각 인식 과제(예: 고양이와 개를 구분하는 이미지 분류 과제)에만 국한되지 않고, 다양한 시각 및 언어 개념을 포함하고 있습니다.
이 방식의 주요 장점은 다음과 같습니다:
- 다양한 과제에 적용 가능: 모델이 특정 과제에 맞춰지지 않기 때문에, 다양한 시각 인식 과제(이미지 분류, 객체 탐지, 의미 분할 등)에서 일반화된 성능을 보일 수 있습니다.
- 풍부한 정보 제공: 이미지와 텍스트 쌍은 단순한 레이블보다 더 풍부하고 다양한 정보를 제공하여, 모델이 더 넓은 범위의 시각 및 언어 개념을 학습할 수 있게 합니다.
- 강력한 일반화 능력: 특정 과제에 맞춰진 레이블보다 일반적인 텍스트 설명을 사용하여 학습하기 때문에, 모델이 새로운 과제나 보지 못한 데이터에도 잘 적응할 수 있습니다.
예를 들어, "고양이가 소파 위에 앉아 있다"는 텍스트 설명은 이미지의 내용을 풍부하게 설명하며, 이는 모델이 단순히 "고양이"라고 레이블링하는 것보다 더 많은 정보를 제공합니다. 이로 인해 모델은 다양한 문맥과 상황에서 "고양이"라는 개념을 더 잘 이해하게 됩니다. 결과적으로, VLM은 특정 과제에만 특화된 모델보다 더 다양한 과제에서 뛰어난 성능을 보일 수 있습니다.
8.2 VLM 전이 학습 성능
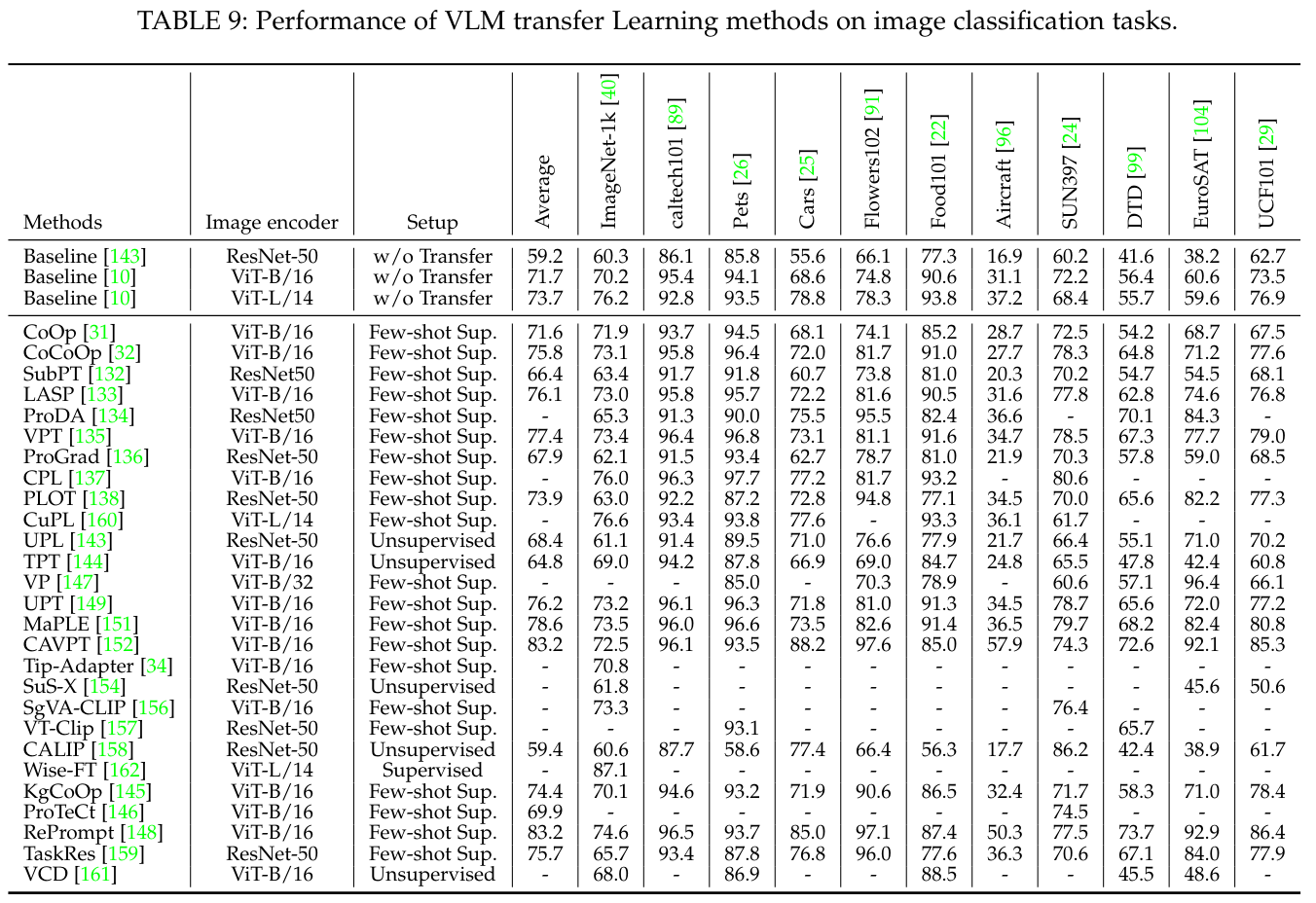
이 섹션에서는 지도 학습 전이(supervised transfer), 소수 샷 지도 학습 전이(few-shot supervised transfer), 비지도 학습 전이(unsupervised transfer) 설정에서의 VLM 전이 성능을 요약합니다. 표 9는 다양한 백본(backbone) 모델(CNN 백본의 ResNet-50, Transformer 백본의 ViT-B 및 ViT-L)을 사용하여 11개의 널리 채택된 이미지 분류 데이터셋(예: EuroSAT [104], UCF101 [29])에서의 결과를 보여줍니다. 표 9는 모든 소수 샷 지도 방법에 대해 16-shot 설정의 성능을 요약합니다.
표 9에서 세 가지 결론을 도출할 수 있습니다. 첫째, VLM 전이 설정은 다운스트림 작업에서 일관되게 성능을 향상시킵니다. 예를 들어, 지도 학습 Wise-FT, 소수 샷 지도 학습 CoOp, 비지도 학습 TPT는 각각 ImageNet에서 정확도를 10.9%, 1.7%, 0.8% 향상시킵니다. 사전 학습된 VLM은 일반적으로 과제 특화 데이터와의 도메인 갭(domain gap)으로 인해 어려움을 겪지만, VLM 전이는 라벨이 있거나 없는 과제 특화 데이터로부터 학습하여 이러한 도메인 갭을 완화할 수 있습니다.
둘째, 소수 샷 지도 학습 전이의 성능은 지도 학습 전이보다 훨씬 뒤처집니다(예: WiseFT [162]의 87.1%와 CuPL [160]의 76.6%). 이는 VLM이 소수 샷 라벨이 있는 샘플에 과적합(overfit)되어 일반화 성능이 저하되기 때문입니다.
셋째, 비지도 학습 전이는 소수 샷 지도 학습 전이와 비슷한 성능을 보일 수 있습니다(예: 비지도 학습 UPL [143]은 2-shot 지도 학습 CoOp [31]을 0.4% 상회하며, 비지도 학습 TPT [144]는 16-shot CoOp [31]과 유사한 성능을 보임). 이는 비지도 학습 전이가 과적합 위험이 훨씬 적은 대규모의 라벨이 없는 다운스트림 데이터를 접근할 수 있기 때문입니다. 그럼에도 불구하고, 비지도 학습 전이도 노이즈가 많은 의사 레이블(pseudo labels)과 같은 여러 도전 과제에 직면해 있습니다. 우리는 이 유망하지만 도전적인 연구 방향에 대한 더 많은 연구를 기대합니다.
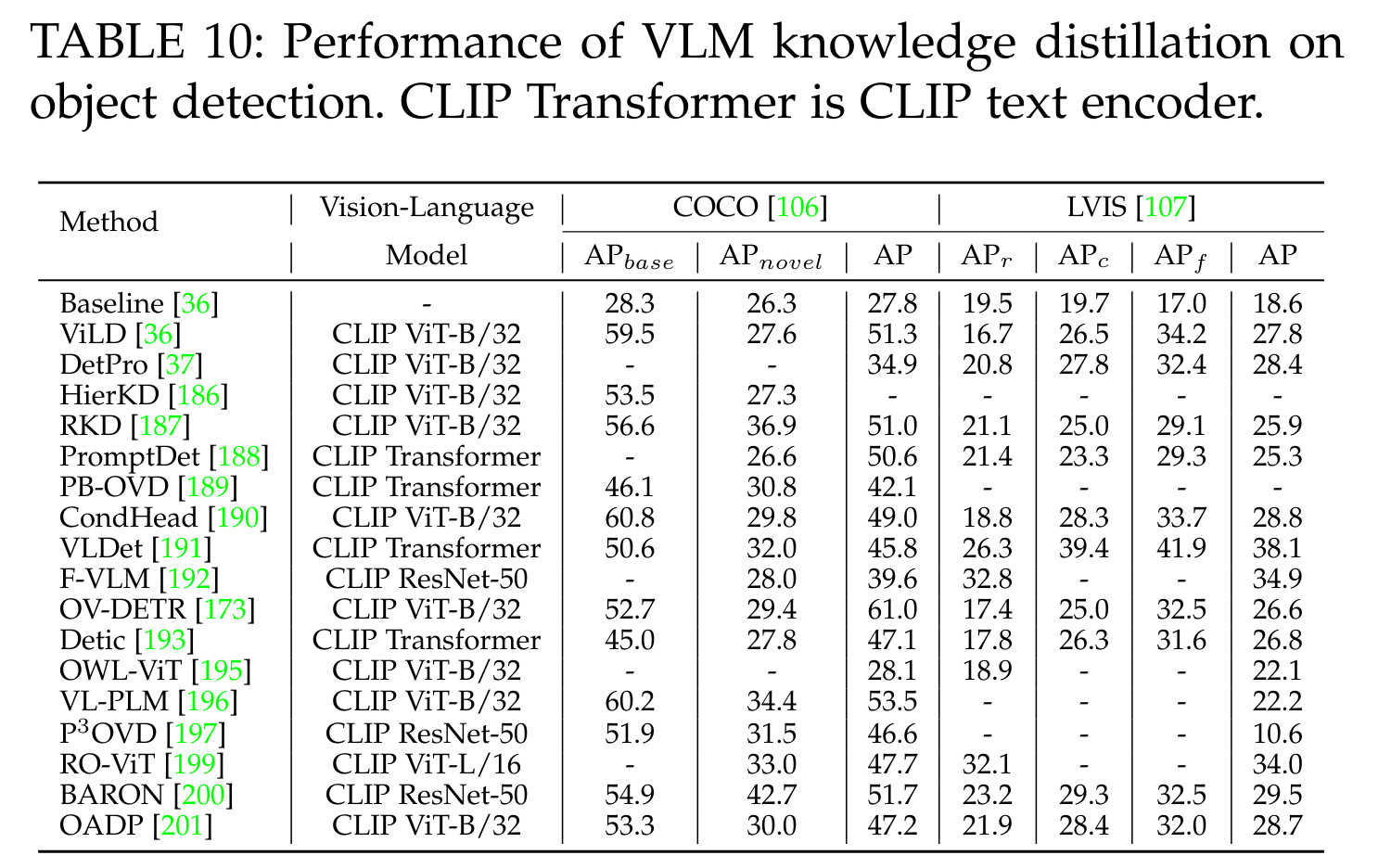
8.3 VLM 지식 증류 성능
이 섹션에서는 VLM 지식 증류(knowledge distillation)가 객체 탐지(object detection)와 의미 분할(semantic segmentation) 작업에서 어떻게 도움이 되는지 설명합니다. 표 10과 11은 널리 사용되는 탐지 데이터셋(예: COCO [106] 및 LVIS [107])과 분할 데이터셋(예: PASCAL VOC [90] 및 ADE20k [111])에서의 지식 증류 성능을 보여줍니다.
탐지 및 분할 작업에서 VLM 지식 증류가 일관되게 명확한 성능 향상을 가져오는 것을 확인할 수 있습니다. 이는 VLM 지식 증류가 일반적이고 강력한 VLM 지식을 도입하면서도, 탐지 및 분할 모델에서 과제 특화 설계의 이점을 함께 제공하기 때문입니다.
8.4 요약 (Summary)
Tables 6-11에서 몇 가지 결론을 도출할 수 있습니다. 성능 측면에서 VLM 사전 학습은 잘 설계된 사전 학습 목표 덕분에 다양한 이미지 분류 작업에서 뛰어난 zero-shot 예측 성능을 달성합니다. 그럼에도 불구하고, 영역 또는 픽셀 수준의 탐지 및 분할과 같은 밀집 시각 인식 작업을 위한 VLM 사전 학습의 개발은 훨씬 뒤처져 있습니다. 또한, VLM 전이는 여러 이미지 분류 데이터셋과 비전 백본에서 눈에 띄는 발전을 이루었습니다. 그러나 지도 학습 또는 소수 샘플 지도 전이는 여전히 라벨이 있는 이미지를 필요로 하는 반면, 더 유망하지만 도전적인 비지도 VLM 전이는 크게 간과되고 있습니다.
벤치마크와 관련하여, 대부분의 VLM 전이 연구는 동일한 사전 학습된 VLM을 기본 모델로 채택하고 동일한 다운스트림 작업에서 평가를 수행하여 벤치마킹을 크게 촉진합니다. 이들은 코드도 공개하고 집약적인 계산 자원을 요구하지 않아 재현성과 벤치마킹이 용이합니다. 반면에, VLM 사전 학습은 다양한 데이터(e.g., CLIP [10], LAION400M [21], CC12M [79])와 네트워크(e.g., ResNet [6], ViT [57], Transformer [58], BERT [14])를 사용하여 연구되므로 공정한 벤치마킹이 매우 어려운 과제입니다. 여러 VLM 사전 학습 연구는 비공개 학습 데이터를 사용하거나 [10], [18], [83] 대규모 계산 자원(예: 256 V100 GPUs)을 필요로 합니다. VLM 지식 증류의 경우, 많은 연구가 서로 다른 작업 특화 백본(e.g., ViLD는 Faster R-CNN, OV-DETR는 DETR을 사용)을 채택하여 벤치마킹을 크게 복잡하게 만듭니다. 따라서, VLM 사전 학습 및 VLM 지식 증류는 학습 데이터, 네트워크 및 다운스트림 작업 측면에서 일정한 규범이 부족합니다.
9 향후 방향 (Future Directions)
VLM은 웹 데이터를 효과적으로 활용하고, 작업 특화 세부 조정 없이 zero-shot 예측을 수행하며, 임의의 카테고리 이미지를 인식할 수 있는 open-vocabulary 시각 인식을 가능하게 합니다. VLM은 놀라운 시각 인식 성능으로 큰 성공을 거두고 있습니다. 이 섹션에서는 다양한 시각 인식 작업에서 미래 VLM 연구가 추구할 수 있는 여러 연구 과제와 잠재적인 연구 방향을 겸허히 공유합니다.
VLM 사전 학습을 위한 네 가지 과제와 잠재적인 연구 방향
- 세밀한 시각-언어 상관 관계 모델링:
- 지역 시각-언어 대응 지식을 통해 [45], [67], VLM은 이미지를 넘어 패치와 픽셀을 더 잘 인식할 수 있으며, 이는 객체 탐지 및 의미론적 분할과 같은 밀집 예측 작업에 크게 도움이 됩니다. 이러한 방향의 VLM 연구가 매우 제한적이므로 [45], [46], [67], [71], [129], [131], zero-shot 밀집 예측 작업을 위한 세밀한 VLM 사전 학습에 대한 연구가 더 필요합니다.
- 시각 및 언어 학습의 통합:
- Transformer [57], [58]의 등장으로 이미지를 토큰화하는 것과 같은 방식으로 텍스트를 단일 Transformer 내에서 통합 학습할 수 있게 되었습니다. 기존 VLMs [10], [17]처럼 두 개의 별도 네트워크를 사용하는 대신, 시각 및 언어 학습을 통합하면 데이터 모달리티 간의 효율적인 소통을 가능하게 하여 학습 효과성과 학습 효율성을 모두 향상시킬 수 있습니다. 이 문제는 일부 주목을 받았지만 [43], [44], 더 지속 가능한 VLMs를 위한 노력이 필요합니다.
- 다국어 텍스트를 사용하는 VLM 사전 학습:
- 대부분의 기존 VLMs는 단일 언어(예: 영어)로 학습되어 [10], [17], 문화와 지역 측면에서 편향을 도입할 수 있으며, 다른 언어 영역에서 VLM 응용을 저해할 수 있습니다. 다국어 텍스트를 사용하는 VLMs 사전 학습 [119], [120]은 동일한 의미의 단어에 대해 다른 언어의 다양한 문화적 시각적 특성을 학습할 수 있도록 하여 [20], VLMs가 다양한 언어 시나리오에서 효율적이고 효과적으로 작동할 수 있게 합니다. 다국어 VLMs에 대한 연구가 더 필요합니다.
- 데이터 효율적인 VLMs:
- 대부분의 기존 연구는 대규모 학습 데이터와 집약적인 계산으로 VLMs를 학습하여 지속 가능성 문제가 큰 우려가 되고 있습니다. 제한된 이미지-텍스트 데이터로 효과적인 VLMs를 학습하면 이 문제를 크게 완화할 수 있습니다. 예를 들어, 각 이미지-텍스트 쌍에서만 학습하는 대신, 이미지-텍스트 쌍 간의 감독을 통해 더 유용한 정보를 학습할 수 있습니다 [112], [113].
- LLMs를 사용하는 VLM 사전 학습:
- 최근 연구들은 LLMs에서 풍부한 언어 지식을 가져와 VLM 사전 학습을 강화합니다 [126], [127]. 구체적으로, LLMs를 사용하여 원시 이미지-텍스트 쌍의 텍스트를 증강하여 더 풍부한 언어 지식을 제공하고 시각-언어 상관 관계를 더 잘 학습할 수 있게 합니다. 미래 연구에서는 VLM 사전 학습에서 LLMs를 더 많이 탐구할 것으로 기대합니다.
VLM 전이 학습을 위한 세 가지 과제와 잠재적인 연구 방향
- 비지도 VLM 전이:
- 대부분의 기존 VLM 전이 연구는 라벨이 있는 데이터를 필요로 하는 지도 학습 또는 소수 샘플 지도 학습 설정에서 작업하며, 후자는 소수 샘플에 과적합되는 경향이 있습니다. 비지도 VLM 전이는 과적합 위험이 훨씬 적은 대규모 라벨 없는 데이터를 탐구할 수 있게 합니다. 앞으로의 VLM 연구에서는 비지도 VLM 전이에 대한 연구가 더 많이 기대됩니다.
- 시각적 프롬프트/어댑터를 사용한 VLM 전이:
- 대부분의 기존 VLM 전이 연구는 텍스트 프롬프트 학습에 중점을 둡니다 [31]. 텍스트 프롬프트를 보완하고 다양한 밀집 예측 작업에서 픽셀 수준의 적응을 가능하게 하는 시각적 프롬프트 학습 또는 시각적 어댑터는 크게 간과되고 있습니다. 시각적 도메인에서 더 많은 VLM 전이 연구가 기대됩니다.
- 테스트 시 VLM 전이:
- 대부분의 기존 연구는 각 다운스트림 작업에서 VLM을 세부 조정(fine-tuning)하여 전이를 수행합니다(즉, 프롬프트 학습). 이는 많은 다운스트림 작업에 직면했을 때 반복적인 노력을 초래합니다. 테스트 시 VLM 전이는 추론 중에 실시간으로 프롬프트를 조정하여 기존 VLM 전이에서 반복적인 학습을 피할 수 있습니다. 테스트 시 VLM 전이에 대한 더 많은 연구가 예상됩니다.
- LLMs를 사용한 VLM 전이:
- 프롬프트 엔지니어링 및 프롬프트 학습과는 달리, 몇몇 시도들은 [160], [161], LLMs [172]를 활용하여 다운스트림 작업을 더 잘 설명하는 텍스트 프롬프트를 생성합니다. 이 접근법은 자동적이며 라벨이 있는 데이터를 거의 필요로 하지 않습니다. 미래 연구에서는 VLM 전이에서 LLMs를 더 많이 탐구할 것으로 기대합니다.
VLM 지식 증류의 두 가지 추가 연구 방향
- 다수의 VLM으로부터의 지식 증류:
- 여러 VLM으로부터 지식 증류를 조정하여 그 시너지 효과를 얻을 수 있습니다.
- 다른 시각 인식 작업을 위한 지식 증류:
- 인스턴스 분할, 범용 분할, 인물 재식별 등과 같은 다른 시각 인식 작업을 위한 지식 증류를 탐구할 수 있습니다.

10 결론 (CONCLUSION)
시각 인식을 위한 비전-언어 모델은 웹 데이터를 효과적으로 활용하고 작업 특화 세부 조정 없이 zero-shot 예측을 가능하게 하여, 구현이 간단하면서도 다양한 인식 작업에서 큰 성공을 거두었습니다. 이 설문 조사는 시각 인식을 위한 비전-언어 모델을 배경, 기초, 데이터셋, 기술적 접근, 벤치마킹 및 미래 연구 방향을 포함한 여러 관점에서 광범위하게 검토합니다. VLM 데이터셋, 접근 방법 및 성능의 비교 요약을 표 형식으로 제공하여, VLM 사전 학습의 최근 발전에 대한 명확한 전체 그림을 제공하며, 이 유망한 연구 방향의 향후 연구에 크게 도움이 될 것입니다.
부록
A. 시각 인식 VLM 논문에 대한 통계
주 논문의 그림 1에서 보이듯이, 최근 2년 동안 Google Scholar에서 시각 인식 VLM 논문의 수를 집계했습니다. 구체적으로, 우리는 선구적인 VLM 연구(즉, CLIP)를 인용한 모든 논문을 잠재적인 출판물로 간주하고, 이미지 분류(image classification), 객체 탐지(object detection), 그리고 의미론적 분할(semantic segmentation) 중 하나의 키워드를 포함하는 논문을 시각 인식 VLM 연구로 식별했습니다. 2023년의 경우, 2023년 1월 1일부터 2023년 11월 30일까지의 논문 수를 기준으로 총 출판물을 추정했습니다.
B. VLM 사전 학습을 위한 데이터셋
VLM 사전 학습을 위해 여러 대규모 이미지-텍스트 데이터셋이 인터넷에서 수집되었습니다 [10], [17], [20], [21]. 전통적인 군중 레이블 데이터셋 [40], [90], [110]과 비교하여, 이미지-텍스트 데이터셋은 훨씬 크고 수집 비용이 저렴합니다 [10], [21]. 예를 들어, 최근의 이미지-텍스트 데이터셋은 일반적으로 수십억 규모입니다 [20], [21], [83]. 이미지-텍스트 데이터셋 외에도 여러 연구 [19], [43], [45], [67]에서는 보조 데이터셋을 활용하여 더 나은 비전-언어 모델링을 위한 추가 정보를 제공합니다. 예를 들어, GLIP [67]는 Object365 [85]를 활용하여 지역 수준의 특징을 추출합니다.
B.1 이미지-텍스트 데이터셋
- SBU [73]: 시각적으로 관련 있는 캡션과 함께 Flicker 웹사이트에서 수집된 100만 개의 이미지로 구성되어 있습니다.
- COCO Caption [74]: MS COCO [106]에서 가져온 33만 개 이상의 이미지를 포함합니다. COCO Caption c5는 33만 개 이미지에 대한 5개의 참조 캡션을 제공하며, COCO Caption c40은 5,000개의 무작위 샘플 이미지에 대해 40개의 참조 캡션을 제공합니다.
- YFCC100M [75]: 99.2M의 이미지와 0.8M의 비디오를 텍스트와 함께 포함하는 멀티미디어 데이터셋입니다.
- VG [76]: 객체 수준 정보, 장면 그래프 및 시각적 질문 답변 쌍 등 이미지를 다각도로 이해할 수 있도록 합니다. VG는 각 이미지에 50개의 설명이 포함된 108,000개의 이미지를 제공합니다.
- CC3M [77]: 약 330만 개의 이미지-텍스트 쌍으로 구성된 이미지 캡션 데이터셋입니다.
- CC12M [79]: CC3M [77]에서 사용된 데이터 수집 파이프라인을 완화하여 보다 정확도가 낮지만 훨씬 더 큰 1200만 개의 이미지-텍스트 쌍을 수집합니다.
- LR [78]: 각 단어가 마우스 추적 세그먼트로 이미지에 위치한 로컬 멀티모달 주석이 있는 이미지 캡션 데이터셋입니다. 848,749개의 이미지와 873,107개의 캡션을 포함합니다.
- WIT [80]: 108개 언어에 걸쳐 37.6M의 이미지-텍스트 쌍으로 구성된 대규모 다중 언어 데이터셋입니다.
- Red Caps [81]: 다양한 객체와 장면을 포함하는 12M의 이미지-텍스트 쌍을 포함하는 소셜 미디어 Reddit에서 수집된 이미지-텍스트 데이터셋입니다.
- LAION400M [21]: CLIP [10]에 의해 필터링된 400M 이미지-텍스트 쌍으로 구성되어 있으며, 데이터 임베딩 및 kNN 지수를 제공합니다.
- LAION5B [20]: 5.8B 이상의 이미지-텍스트 쌍으로 구성되어 있으며, 2.32B의 영어 이미지-텍스트 쌍, 2.26B의 다국어 이미지-텍스트 쌍 및 1.27B의 특정 언어가 없는 쌍으로 구성되어 있습니다.
- WuKong [82]: 웹에서 수집된 100M의 중국어 이미지-텍스트 쌍을 포함하는 대규모 중국어 멀티모달 데이터셋입니다.
- CLIP [10]: 인터넷에서 공개적으로 이용 가능한 다양한 출처에서 수집된 400M 이미지-텍스트 쌍을 포함하는 대규모 웹 이미지-텍스트 데이터셋입니다.
- ALIGN [17]: 1.8B의 노이즈가 있는 이미지-텍스트 쌍을 포함하는 이미지-텍스트 데이터셋으로, 광범위한 개념을 다룹니다.
- FILIP [18]: 인터넷에서 수집된 300M 이미지-텍스트 쌍을 포함하는 대규모 이미지-텍스트 데이터셋입니다.
- WebLI [83]: 109개 언어에 걸쳐 10B 이미지와 12B 해당 텍스트로 구성된 다국어 이미지-텍스트 데이터셋입니다.
B.2 보조 데이터셋
- JFT3B [204]: 약 30k 레이블의 노이즈가 있는 클래스 계층 구조로 주석이 달린 거의 3B의 이미지를 포함합니다.
- C4 [205]: 공개 Common Crawl 웹 스크랩에서 가져온 약 750GB의 영어 텍스트 모음입니다.
- Object365 [85]: 365개의 카테고리, 638K의 이미지 및 ∼10M의 바운딩 박스를 포함하는 객체 탐지 데이터셋입니다.
- Gold-G [86]: [86]에 의해 큐레이션된 0.8M의 인간 주석 시각적 그라운딩 데이터를 포함하는 객체-문구 데이터셋입니다.
C. 평가를 위한 데이터셋
주 논문의 표 2에 나와 있듯이, VLM 평가에 사용된 많은 시각 인식 데이터셋이 있습니다. 여기에는 27개의 이미지 분류 데이터셋, 4개의 객체 탐지 데이터셋, 4개의 의미론적 분할 데이터셋, 2개의 이미지-텍스트 검색 데이터셋, 3개의 동작 인식 데이터셋이 포함됩니다. 각 데이터셋의 세부 정보는 다음과 같습니다.
C.1. 이미지 분류를 위한 데이터셋
- Food-101 [22]: 세밀한 인식을 위한 실제 음식 데이터셋으로, 101,000개의 이미지와 101개의 클래스로 구성되어 있습니다. 각 클래스는 250개의 정제된 테스트 샘플과 750개의 의도적으로 정제되지 않은 학습 샘플을 포함합니다.
- CIFAR-10 [23]: 이미지 분류 작업에 일반적으로 사용되는 작은 이미지 집합으로, 32x32 크기의 60000개의 이미지와 10개의 카테고리로 주석이 달려 있습니다. 이 데이터셋은 클래스당 5000개의 학습 샘플과 1000개의 테스트 샘플로 나뉩니다.
- CIFAR-100 [23]: CIFAR-10과 거의 동일하지만, CIFAR-100은 100개의 카테고리로 그룹화된 60000개의 샘플로 구성되어 있습니다.
- Birdsnap [100]: Flicker에서 수집된 세밀한 분류 데이터셋으로, 500종의 조류에 속하는 49,829개의 이미지로 구성되어 있습니다. 47,386개의 학습 이미지와 2433개의 테스트 이미지를 포함하며, 각 이미지에는 바운딩 박스, 17개 부분의 좌표 및 보조 속성 주석이 포함되어 있습니다.
- SUN397 [24]: 장면 인식을 위해 제안된 데이터셋으로, 397개의 잘 샘플된 카테고리를 포함한 39700개의 이미지로 구성되어 있습니다. 인간의 장면 분류 성능이 계산 방법과 비교하기 위한 기준으로 제공됩니다.
- Stanford Cars [25]: 세밀한 인식을 위해 설계된 데이터셋으로, 196개의 카테고리를 포함한 16185개의 이미지로 구성되어 있습니다. 이 데이터셋은 8,144개의 학습 샘플과 8,041개의 테스트 샘플로 나뉩니다.
- FGVC Aircraft [96]: 100개의 항공기 모델 변종에 걸친 10K 샘플을 포함하며, 각 샘플은 엄밀한 바운딩 박스와 계층적 카테고리 주석으로 레이블이 지정되어 있습니다. 이 데이터셋은 각 변종당 33 또는 34개의 이미지를 포함하는 학습, 검증 및 테스트 하위 집합으로 동일하게 나뉩니다.
- PASCAL VOC 2007 Classification [90]: 탐지, 분할 및 분류와 같은 다양한 시각 인식 작업에 널리 사용되는 데이터셋으로, 20개의 클래스를 포함한 9963개의 샘플로 구성되어 있습니다. 각 샘플에는 픽셀 단위의 레이블, 객체 단위의 레이블 및 카테고리 레이블이 포함되어 있습니다.
- Describable Textures [99] (DTD): 이미지 인식을 위한 텍스처 이미지 모음으로, 47개의 카테고리로 구성된 5640개의 샘플을 포함합니다. 각 하위 집합은 클래스당 40개의 이미지를 포함하는 학습, 검증 및 테스트 하위 집합으로 동일하게 나뉩니다. 각 이미지에는 주요 카테고리와 공동 속성 목록이 제공됩니다.
- Oxford-IIIT PETS [26]: 25개의 개 품종과 12개의 고양이 품종을 포함한 37개의 품종에 걸쳐 7,349개의 고양이 및 개 이미지를 포함합니다. 이 샘플들은 약 1850개의 샘플이 있는 학습 하위 집합, 약 1850개의 샘플이 있는 검증 하위 집합, 약 3700개의 샘플이 있는 테스트 하위 집합으로 나뉩니다. 각 샘플에는 품종 주석, 몸체를 표시하는 픽셀 단위의 주석 및 머리를 찾기 위한 직사각형 상자가 포함됩니다.
- Caltech-101 [89]: 101개의 클래스에 속하는 9145개의 이미지로 구성되며, 각 카테고리는 40-80개의 이미지를 포함합니다. 각 이미지에는 전경 객체를 세분화하기 위한 주석이 제공됩니다.
- Oxford 102 Flowers [91]: 세밀한 이미지 분류를 위해 제안된 데이터셋으로, 102종의 8189개의 꽃 이미지를 포함합니다. 각 카테고리는 40-200개의 샘플을 포함하며, 다양한 크기와 조명 환경에서 캡처된 꽃을 포함합니다. 또한, 이 데이터셋에는 픽셀 단위의 주석도 포함됩니다.
- Facial Emotion Recognition 2013 [97]: Google에서 184개의 주요 감정 용어와 관련된 이미지를 요청하여 수집된 데이터셋으로, 7가지 유형의 감정을 포함한 35,887개의 그레이스케일 이미지로 구성되어 있습니다.
- STL-10 [93]: 비지도 및 자가 학습 훈련에 관한 연구를 위한 분류 벤치마크로, 10개의 카테고리와 100K 샘플을 포함한 비지도 학습 하위 집합, 5K 샘플을 포함한 지도 학습 하위 집합, 8K 샘플을 포함한 테스트 하위 집합으로 구성되어 있습니다.
- EuroSAT [104]: 토지 이용 및 토지 피복 인식 작업을 벤치마킹하기 위해 사용되는 위성 이미지 집합으로, 10개의 카테고리에 걸쳐 27K의 주석이 달린 지리적으로 참조된 샘플을 포함합니다. RGB 이미지 데이터셋과 다중 스펙트럼 이미지 데이터셋이 제공됩니다.
- RESISC45 [101]: 원격 감지 이미지 장면 분류(RESISC)를 벤치마킹하기 위해 제안된 데이터셋으로, 45개의 장면 카테고리에 걸쳐 31,500개의 샘플을 포함합니다. 각 카테고리는 700개의 샘플을 포함하며, 20cm에서 30m 이상의 픽셀당 공간 해상도를 포괄합니다.
- GTSRB [94]: 독일의 다양한 거리 장면에서 촬영된 50,000개의 이미지를 포함하는 교통 표지판 분류 데이터셋으로, 43개의 카테고리로 분류됩니다. 학습 하위 집합에는 39,209개의 샘플이 있고, 테스트 하위 집합에는 12,630개의 샘플이 있습니다.
- Country211 [10]: 지리적 위치 평가를 위한 이미지 분류 데이터셋으로, YFCC100M 데이터셋의 하위 집합입니다. 각 국가별로 150개의 학습 샘플, 50개의 검증 샘플 및 100개의 테스트 샘플이 있습니다.
- PatchCamelyon [103]: Camelyon16에서 96x96 크기의 327,680개의 RGB 이미지를 포함하며, 75%의 샘플이 있는 학습 하위 집합, 12.5%의 샘플이 있는 검증 하위 집합 및 12.5%의 샘플이 있는 테스트 하위 집합으로 구성되어 있습니다. 각 샘플에는 전이성 조직을 포함하는지 여부를 나타내는 이진 주석이 포함되어 있습니다.
- Hateful Memes [27]: Facebook AI에 의해 생성된 혐오 밈 분류(즉, 텍스트가 포함된 이미지)를 위한 데이터셋으로, 혐오 레이블 또는 비혐오 레이블로 주석이 달린 10k 이상의 밈을 포함합니다.
- Rendered SST2 [10]: 광학 문자 인식을 벤치마킹하기 위해 제안된 데이터셋으로, 긍정 및 부정의 두 카테고리를 포함합니다. 이 데이터셋은 6920개의 샘플이 있는 학습 하위 집합, 872개의 샘플이 있는 검증 하위 집합, 1821개의 샘플이 있는 테스트 하위 집합으로 나뉩니다.
- ImageNet-1k [40]: 1000개의 카테고리에 균일하게 분포된 약 1.2M 샘플을 포함합니다. ImageNet-1k의 카테고리 주석은 WordNet 계층 구조를 따르며, 각 샘플에는 하나의 카테고리 레이블이 주석으로 달려 있습니다. 또한, ImageNet-1k는 가장 인기 있는 이미지 분류 벤치마크 중 하나입니다.
- CLEVR Counts [102]: 시각적 질문 답변을 위해 설계된 CLEVR 데이터셋의 하위 집합으로, 시각적 추론을 수행하는 능력을 평가하기 위해 사용됩니다. 카운팅 작업에는 2000개의 학습 샘플과 500개의 테스트 샘플이 포함됩니다.
- SVHN [92]: Google Street View 이미지에서 수집된 실제 이미지에서 숫자와 숫자를 인식하기 위한 데이터셋으로, 약 600,000개의 이미지를 포함합니다. 모든 숫자는 이미지에서 잘라내고 32x32 픽셀의 고정 해상도로 크기를 조정합니다.
- IIIT5k [95]: 간판, 집 이름판 및 영화 포스터 등의 검색 키워드를 사용하여 Google 이미지 검색에서 수집된 5000개의 잘린 단어 이미지를 포함합니다. 데이터셋은 각각 2000개의 단어 이미지가 있는 학습 부분과 3000개의 단어 이미지가 있는 검증 부분으로 나뉩니다.
- Rendered SST2 [98]: 긍정 및 부정의 두 가지 감정 카테고리로 구성된 감정 분류 데이터셋으로, 데이터셋의 문장은 Stanford Sentiment Treebank 데이터셋에서 추출되었습니다.
C.2. 동작 인식을 위한 데이터셋
- UCF101 [29]: 비디오를 통한 인간 동작 인식을 벤치마킹하기 위해 제안된 데이터셋으로, YouTube에서 수집한 101가지 동작의 약 13,000개의 비디오 클립을 포함합니다. 데이터셋의 비디오 클립은 320x240 픽셀의 해상도와 25 FPS의 프레임 속도를 갖습니다.
- Kinetics700 [30]: 인간 동작 인식을 위한 비디오 데이터셋으로, 700가지 인간 동작을 포함한 약 65,000개의 비디오 클립으로 구성됩니다. 각 동작 카테고리는 약 10초 동안 지속되는 700개 이상의 비디오 클립을 포함합니다.
- RareAct [28]: "오븐 플러그 뽑기"와 "휴대폰 튀기기"와 같은 희귀 동작을 식별하기 위해 설계된 비디오 데이터셋입니다. 이 데이터셋은 일반적인 동작 동사와 객체 명사의 희귀한 조합에서 동작 인식 모델을 평가하는 것을 목표로 합니다. HowTo100M에서 동작의 동사와 객체 명사가 거의 함께 발생하지 않는 122개의 인간 동작을 포함합니다.
C.3. 의미론적 분할을 위한 데이터셋
- ADE20k [111]: 150개의 클래스로 구성된 의미론적 분할 데이터셋입니다. 25,574개의 샘플이 있는 학습 하위 집합과 2,000개의 샘플이 있는 검증 하위 집합으로 구성됩니다.
- PASCAL VOC 2012 Segmentation [90]: 차량, 가정용품 및 동물과 같은 20개의 카테고리를 포함합니다. 이 데이터셋에는 1,464개의 샘플이 있는 학습 하위 집합과 1,449개의 샘플이 있는 테스트 하위 집합이 포함되며, 모든 샘플에는 픽셀 단위의 주석이 달려 있습니다.
- PASCAL Content [109]: PASCAL VOC 2010 탐지 데이터셋 [90]의 확장으로, 픽셀 단위의 주석이 포함된 400개 이상의 카테고리를 포함합니다. 4,998개의 학습 이미지와 1,449개의 검증 이미지가 포함됩니다.
- Cityscapes [110]: 거리 장면의 시각적 인식을 위한 데이터셋으로, 19개의 카테고리에 대한 픽셀 단위의 주석이 포함된 2,975개의 학습 샘플과 500개의 테스트 샘플을 포함합니다.
C.4. 객체 탐지를 위한 데이터셋
- MS COCO [106]: 객체 탐지를 위한 데이터셋으로, 두 가지 버전으로 구성됩니다. MS COCO 2014는 80개의 카테고리에 대한 바운딩 박스 주석이 있는 83,000개의 학습 이미지와 41,000개의 검증 이미지를 포함하며, MS COCO 2017은 80개의 카테고리에 대한 바운딩 박스 주석이 있는 118,000개의 학습 이미지와 5,000개의 검증 이미지를 포함합니다.
- ODinW [108]: 35개의 자유로운 공공 객체 탐지 데이터셋으로 구성된 사전 학습된 비전 모델의 작업 수준 전이 능력을 평가하기 위한 벤치마크입니다. 데이터셋에는 314개의 개념에 속하는 132,000개의 학습 이미지와 20,000개의 테스트 이미지가 포함됩니다. 또한, 35개의 작업 중 많은 작업은 100개 미만의 학습 이미지를 포함하여 사전 학습 없이 표준 탐지기에는 매우 어렵습니다.
- LVIS [107]: 긴 꼬리 인스턴스 탐지/분할을 위한 대규모 어휘 데이터셋으로, 100,000개의 이미지에 대한 연합된 인간 주석이 있는 1,203개의 카테고리를 포함합니다.
C.5. 이미지와 텍스트 검색을 위한 데이터셋
- Flickr30k [105]: 자동 이미지 설명과 기반 언어 이해를 위한 데이터셋으로, Flickr에서 수집한 31,000개의 이미지를 포함합니다. 각 이미지에는 5개의 캡션이 제공됩니다.
- COCO Caption [74]: MS COCO [106]에서 가져온 33만 개 이상의 이미지를 포함합니다. COCO Caption c5는 33만 개 이미지에 대한 5개의 참조 캡션을 제공하며, COCO Caption c40은 5,000개의 무작위 샘플 이미지에 대해 40개의 참조 캡션을 제공합니다.