[NLP 기초] 7. RNN을 사용한 문장 생성
7.1 언어 모델을 사용한 문장 생성
- 언어 모델로 문장 생성
7.1.1 RNN을 사용한 문장 생성의 순서

언어 모델에게 문장을 생성시키는 순서
ex) you say goodbye and I say hello 말뭉치로 학습
- I를 입력했을 때 다음의 확률분포 출력


다음 단어를 새로 생성하려면?
- 확률이 가장 높은 단어를 선택
= 확률이 가장 높은 단어 선택할 뿐. 결과가 일정하게 정해지는 '결정적'인 방법 - '확률적'으로 선택하는 방법
= 각 후보 단어의 확률에 맞게 선택, 확률 높은 단어일수록 선택되기 쉬움, 샘플링 단어 매번 다를 수 있음
매번 다른 문장 생성을 위해, 2번의 '확률적' 방법 사용
- say가 샘플링될 확률 가장 높음
- 필연적 x, 확률적 o
- 다른 단어들도 확률에 따라 샘플링될 가능성 있음

두번째 단어 샘플링
- 방금 생성한 단어인 'say'를 언어 모델에 입력하여 다음 단어의 확률분포 얻음
- 얻은 확률분포 기초로 다음 출현 단어 샘플링
이러한 작업을 원하는 만큼 반복
- 생성한 문장은 훈련 데이터에 존재하지 않는 생성 문장
→ 언어 모델은 훈련 데이터를 암기한 것이 아니라, 훈련 데이터에서 사용된 단어의 정렬 패턴 학습한 것
7.1.2 문장 생성 구현
문장 생성 코드 구현
- 앞 장 Rnnlm 클래스를 상속해 RnnlmGen 클래스 만들고, 생성 메서드 추가
* NOTE : 클래스 상속
- 기존 클래스를 계승하여 새로운 클래스를 만드는 매커니즘
- ex) 기반 클래스 이름 'Base'이고, 새로 정의할 클래스 이름 'New'라면 class New(Base)라고 씀
RnnlmGen 클래스 구현
# coding: utf-8
import sys
sys.path.append('..')
import numpy as np
from common.functions import softmax
from ch06.rnnlm import Rnnlm
from ch06.better_rnnlm import BetterRnnlm
class RnnlmGen(Rnnlm):
def generate(self, start_id, skip_ids=None, sample_size=100):
word_ids = [start_id]
x = start_id
while len(word_ids) < sample_size:
x = np.array(x).reshape(1, 1)
score = self.predict(x)
p = softmax(score.flatten())
sampled = np.random.choice(len(p), size=1, p=p)
if (skip_ids is None) or (sampled not in skip_ids):
x = sampled
word_ids.append(int(x))
return word_ids
def get_state(self):
return self.lstm_layer.h, self.lstm_layer.c
def set_state(self, state):
self.lstm_layer.set_state(*state)
class BetterRnnlmGen(BetterRnnlm):
def generate(self, start_id, skip_ids=None, sample_size=100):
word_ids = [start_id]
x = start_id
while len(word_ids) < sample_size:
x = np.array(x).reshape(1, 1)
score = self.predict(x).flatten()
p = softmax(score).flatten()
sampled = np.random.choice(len(p), size=1, p=p)
if (skip_ids is None) or (sampled not in skip_ids):
x = sampled
word_ids.append(int(x))
return word_ids
def get_state(self):
states = []
for layer in self.lstm_layers:
states.append((layer.h, layer.c))
return states
def set_state(self, states):
for layer, state in zip(self.lstm_layers, states):
layer.set_state(*state)generate(start_id, skip_ids, sample_size) : 문장 생성 수행 메서드
- start_id : 최초로 주는 단어의 ID
- sample_size : 샘플링하는 단어의 수
- skip_ids : 단어 ID의 리스트 (이 리스트에 속하는 단어 ID는 샘플링되지 않도록)
generate() 메서드 내부
- model.predict(x)를 호출해 각 단어의 점수 출력
- p=softmax(score) 코드에서 이 점수들 소프트맥스 함수를 이용해 정규화 → 확률분포 p 얻음
- 확률분포 p로부터 다음 단어 샘플링
RnnlmGen 클래스를 사용해 문장 생성
# coding: utf-8
import sys
sys.path.append('..')
from rnnlm_gen import RnnlmGen
from dataset import ptb
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
corpus_size = len(corpus)
model = RnnlmGen()
model.load_params('../ch06/Rnnlm.pkl')
# start 문자와 skip 문자 설정
start_word = 'you' # 첫 단어
start_id = word_to_id[start_word]
skip_words = ['N', '<unk>', '$'] # 샘플링하지 않을 단어
skip_ids = [word_to_id[w] for w in skip_words]
# 문장 생성
word_ids = model.generate(start_id, skip_ids)
txt = ' '.join([id_to_word[i] for i in word_ids])
txt = txt.replace(' <eos>', '.\n')
print(txt)- 처음에는 엉터리로 나열한 글이 출력
- 학습을 수행한 후에는 점차 그럴듯한 문장 출력
- 그러나 여전히 결과에서 개선해야 할 여지가 보임 → 더 나은 모델 사용


7.1.3 더 좋은 문장으로

- 앞 장에서 구현한 더 좋은 언어 모델 BetterRnnlm 클래스로 구현
- 이 클래스를 상속하고, 문장 생성 기능 추가
- 전보다 자연스러운 결과
7.2 seq2seq
시계열 데이터를 또 다른 시계열 데이터로 변환하는 문제 다뤄보자
- 2개의 RNN을 사용하는 seq2seq 방법
7.2.1 seq2se의 원리
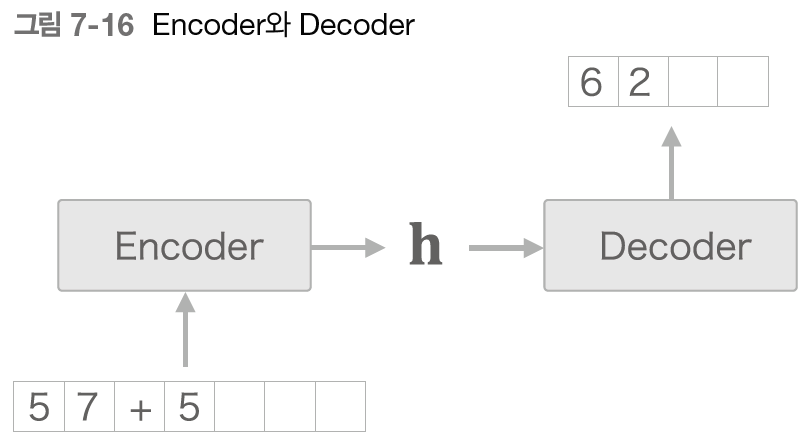
seq2seq를 Encoder-Decoder 모델이라고도 함
- Encoder : 입력 데이터를 인코딩(부호화)
- Decoder : 인코딩된 데이터를 디코딩 (복호화)
* NOTE
- 인코딩(부호화) : 정보를 어떤 규칙에 따라 변환
- 디코딩(복호화) : 인코딩된 정보를 원래의 정보로 되돌림
ex) '나는 고양이로소이다' 문장을 'I am a cat' 으로 변역

- Encoder : 인코딩한 정보에는 번역에 필요한 정보가 조밀하게 응출
- Decoder : 조밀하게 응축된 이 정보를 바탕으로 도착어 문장 생성
→ Encoder와 Decoder가 협력하여 시계열 데이터를 다른 시계열 데이터로 변환, Encoder와 Decoder로 RNN 사용
Encoder
- RNN을 이용해 시계열 데이터를 h라는 은닉 상태 벡터로 변환
(여기서는 RNN으로 LSTM 사용) - Encoder가 출력하는 벡터 h는 LSTM 계층의 마지막 은닉 상태
- 은닉 상태 h에 입력 문장(출발어)를 번역하는데 필요한 정보 인코딩
- LSTM의 은닉 상태 h는 고정 길이 벡터
→ 인코딩한다 = 임의 길이의 문장을 고정 길이 벡터로 변환


Decoder
- Decoder는 인코딩된 벡터를 어떻게 요리하여 도착어 문장 생성?
→ 앞 절에서 다룬 문장 생성 모델 그대로 이용 - Decoder는 앞 절의 신경망과 완전히 같은 구성
!= LSTM 계층이 벡터 h를 입력받는다는 점이 다름 (앞 절 언어모델에서는 LSTM 계층 아무것도 받지 않음) - seq2seq는 LSTM 두 개로 구성(Encoder & Decoder)
- LSTM의 은닉 상태 h가 Encoder와 Decoder를 이어주는 '가교' 역할
- 순전파 : Encoder에서 인코딩된 정보가 LSTM 계층의 은닉 상태를 통해 Decoder에 전해짐
- 역전파 : 가교(h)를 통해 기울기가 Decoder로부터 Encoder로 전해짐


7.2.2 시계열 데이터 변환용 장난감 문제
장난감 문제
- 머신러닝을 평가하고자 만든 간단한 문제
시계열 변환 문제의 예로 '더하기' 다뤄보자
- '덧셈 문제'에서는 단어가 아닌 '문자' 단위로 분할

7.2.3 가변 길이 시계열 데이터
'덧셈'은 가변 길이 시계열 데이터
신경망 학습 시 '미니배치 처리'를 위해 무언가 추가 노력
* NOTE
- 미니배치로 학습할 때는 다수의 샘플 한꺼번에 처리
- 샘플의 데이터 형상 모두 같아야 함
방안
패딩
- 원래의 데이터에 의미 없는 데이터를 채워 모든 데이터의 길이를 균일하게 맞추는 기법
- 0~ 999 사이의 숫자 2개만 더함 →최대 4 문자
- 데이터에 패딩을 수행해 모든 샘플 데이터 길이 통일
- 질문과 정답을 구분하기 위해 출력 앞에 구분자로 밑줄(_) → 총 5문자로 통일, Decoder 문자열 생성 신호로 사용
패딩의 장단점
- 장점 : 패딩로 데이터 크기를 통일하면 가변 길이 시계열 데이터 처리할 수 있음
- 단점 : 존재하지 않던 패딩용 문자까지 seq2seq가 처리하게 됨

seq2seq에 패딩 전용 처리 추가
- Decoder에 입력된 데이터가 패딩이라면, 손실 결과에 반영하지 않음 (Softmax with Loss 계층에 '마스크' 기능 추가)
- Encoder에 입력된 데이터가 패딩이라면, LSTM 계층이 이전 시각의 입력을 그대로 출력
= LSTM 계층은 마치 처음부터 패딩 존재하지 않았던 것처럼 인코딩
7.2.4 덧셈 데이터셋
예제 학습 데이터(덧셈 예 총 50,000개)

# coding: utf-8
import sys
sys.path.append('..')
from dataset import sequence
(x_train, t_train), (x_test, t_test) = \
sequence.load_data('addition.txt', seed=1984)
char_to_id, id_to_char = sequence.get_vocab()
print(x_train.shape, t_train.shape)
print(x_test.shape, t_test.shape)
# (45000, 7) (45000, 5)
# (5000, 7) (5000, 5)
print(x_train[0])
print(t_train[0])
# [ 3 0 2 0 0 11 5]
# [ 6 0 11 7 5]
print(''.join([id_to_char[c] for c in x_train[0]]))
print(''.join([id_to_char[c] for c in t_train[0]]))
# 71+118
# _189- load_data(file_name, seed)는 file_name으로 지정한 텍스트 파일 읽어 문자 ID로 변환
- 훈련과 데이트 데이터로 나눠 반환
- seed : 메서드 내부 무작위수의 초깃값
- get_vocab() 메서드 : 문자와 문자 ID의 대응 관계를 담은 딕셔너리
- sequence 모듈 : seq2seq 용 데이터 간단히 읽어들임
- x_train, t_train : 문자 ID 저장
- char_to_id & id_to_char : 상호 변환용
7.3 seq2seq 구현
- seq2seq는 2개의 RNN을 연결한 신경망
- Encoder 클래스와 Decoder 클래스로 각각 구현
- 두 클래스 연결하는 Seq2seq 클래스 구현
7.3.1 Encoder 클래스
문자열을 받아 벡터 h로 변환

RNN을 이용해 Encoder를 구성 → Embedding 계층 & LSTM 계층
- Embedding 계층
: 문자(정확히 문자 ID)를 문자 벡터로 변환 & LSTM 계층으로 입력 - LSTM 계층
: 오른쪽(시간 방향)으로 은닉 상태와 셀 출력 & 위쪽으로는 은닉 상태만 출력
(더 위에 다른 계층 없으므로 LSTM 계층의 위쪽 출력 폐기) - Encoder에서 마지막 문자를 처리한 후 LSTM 계층의 은닉 상태 h 출력, h를 Decoder로 전달

* WARNING
- Encoder에서는 LSTM의 은닉 상태만 Decoder에 전달
시간 방향을 한꺼번에 처리하는 계층 : Time LSTM, Time Embedding

Encoder 클래스 코드
# coding: utf-8
import sys
sys.path.append('..')
from common.time_layers import *
from common.base_model import BaseModel
class Encoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
# 어휘 수(문자의 종류), 문자 벡터의 차원 수, 은닉 상태 벡터의 차원 수
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
# 가중치 매개변수 초기화 & 필요한 계층 생ㅅ어
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
self.embed = TimeEmbedding(embed_W)
# Time LSTM 계층이 상태를 유지하지 않으므로 stateful=False로 설정
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=False)
self.params = self.embed.params + self.lstm.params
self.grads = self.embed.grads + self.lstm.grads
self.hs = None
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
self.hs = hs
return hs[:, -1, :]
def backward(self, dh):
dhs = np.zeros_like(self.hs)
dhs[:, -1, :] = dh
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout
초기화, 순전파, 역전파 메서드 제공
- 순전파
- Time Embeddimg 계층과 Time LSTM 계층의 forward() 메서드 호출
- 마지막 시각의 은닉 상태 추출해 출력으로 반환 - 역전파
- LSTM 계층의 마지막 은닉 상태에 대한 기울기가 dh 인수로 전해짐 (* dh 인수 : Decoder가 전해주는 기울기)
- 원소가 모두 0인 텐서 dhs를 생성, dh를 dhs의 해당 위치에 할당
- Time LSTM 계층과 Time Embedding 계층의 backward() 메서드 호출
* WARNING
- 5, 6장 모델은 '긴 시계열 데이터' 하나뿐인 문제 = stateful을 True로 설정, 은닉 상태 유지하여 긴 데이터 처리
- 이번에는 '짧은 시계열 데이터' 여러 개인 문제 = 문제마다 LSTM의 은닉 상태를 다시 초기화한 상태(영벡터)로 설정
7.3.2 Decoder 클래스
Decoder 클래스
- Encoder 클래스가 출력한 h를 받아 목적으로 하는 다른 문자열을 출력
- RNN으로 구현(여기에서는 LSTM)
Decoder의 학습 시 계층 구성

* WARNING : RNN으로 문장 생성 시, 학습과 생성의 데이터 부여 방법
- 학습 : 정답을 알고 있기 때문에 시계열 방향의 데이터 한꺼번에 줄 수 있음
- 추론 : 최초 시작을 알리는 구분 문자(EX. _) 하나만 줌
- 출력으로부터 문자를 하나를 샘플링하여, 그 샘플링한 문자를 다음 입력으로 사용하는 과정 반복
이번 문제는 '덧셈'
- '확률적'이 아닌 '결정적'으로 선택 : 점수가 가장 높은 문자 하나만
Decoder가 문자열을 생성시키는 흐름

- argmax 노드 : 최댓값을 가진 원소의 인덱스(ex. 문자 ID)를 선택하는 노드
- Softmax 계층이 아닌 Affine 계층이 출력하는 점수가 가장 큰 문자 ID 선택
* WARNING
- Softmax 계층은 입력된 벡터를 정규화 → 대소 관계는 바뀌지 않음
- 그러므로 [그림 7-18]의 경우 Softmax 계층 생략
- Softmax with Loss 계층은 이후에 구혀하는 seq2seq 클래스에서 처리
Decoder 클래스 구현

- Time Embedding, Time LSTM, Time Affine의 3가지 계층으로 구성
- 초기화, 순전파, 역전파
class Decoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, h):
self.lstm.set_state(h)
out = self.embed.forward(xs)
out = self.lstm.forward(out)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
dout = self.lstm.backward(dout)
dout = self.embed.backward(dout)
dh = self.lstm.dh
return dh
def generate(self, h, start_id, sample_size):
sampled = []
sample_id = start_id
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array(sample_id).reshape((1, 1))
out = self.embed.forward(x)
out = self.lstm.forward(out)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
sampled.append(int(sample_id))
return sampled
backward() 메서드
- 위쪽의 Softmax with Loss 계층으로부터 기울기 dscore를 받아 Time Affine 계층, Time LSTM 계층, Time Embedding 계층 순서로 전파
- Time LSTM 계층의 시간 방향으로의 기울기는 TimeLSTM 클래스의 인스턴스 변수 dh에 저장
- 시간 방향 기울기 dh를 꺼내서 Decoder 클래스의 backward()의 출력으로 반환
generate() 메서드
- Decoder 클래스에 문장 생성
- 문자를 1개씩 주고 Affine 계층이 출력하는 점수가 가장 큰 문자 ID 선택
* WARNING
- 이번 문제에서는 Encoder의 출력 h를 Decoder의 Time LSTM 계층의 상태로 설정(stateful)
- 즉, Encoder의 h를 유지하면서 순전파 이뤄짐
7.3.3 Seq2seq 클래스
- Encoder 클래스와 Decoder 클래스 연결
- Time Softmax with Loss 계층을 이용해 손실 계산
- 기능들을 제대로 연결
class Seq2seq(BaseModel):
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V, D, H)
self.decoder = Decoder(V, D, H)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
def forward(self, xs, ts):
decoder_xs, decoder_ts = ts[:, :-1], ts[:, 1:]
h = self.encoder.forward(xs)
score = self.decoder.forward(decoder_xs, h)
loss = self.softmax.forward(score, decoder_ts)
return loss
def backward(self, dout=1):
dout = self.softmax.backward(dout)
dh = self.decoder.backward(dout)
dout = self.encoder.backward(dh)
return dout
def generate(self, xs, start_id, sample_size):
h = self.encoder.forward(xs)
sampled = self.decoder.generate(h, start_id, sample_size)
return sampled
7.3.4 seq2seq 평가
seq2seq의 학습은 기본적인 신경망의 학습과 같은 흐름
- 학습 데이터에서 미니배치를 선택
- 미니배치로부터 기울기 계산
- 기울기를 사용하여 매개변수 갱신
- Trainer 클래스를 사용해 위 규칙대로 작업 수행
- 매 에폭마다 seq2seq가 테스트 데이터를 풀게 하여 학습 중간중간 정답률 측정
# coding: utf-8
import sys
sys.path.append('..')
import numpy as np
import matplotlib.pyplot as plt
from dataset import sequence
from common.optimizer import Adam
from common.trainer import Trainer
from common.util import eval_seq2seq
from seq2seq import Seq2seq
from peeky_seq2seq import PeekySeq2seq
# 데이터셋 읽기
(x_train, t_train), (x_test, t_test) = sequence.load_data('addition.txt')
char_to_id, id_to_char = sequence.get_vocab()
# 입력 반전 여부 설정 =============================================
is_reverse = False # True
if is_reverse:
x_train, x_test = x_train[:, ::-1], x_test[:, ::-1]
# ================================================================
# 하이퍼파라미터 설정
vocab_size = len(char_to_id)
wordvec_size = 16
hidden_size = 128
batch_size = 128
max_epoch = 25
max_grad = 5.0
# 일반 혹은 엿보기(Peeky) 설정 =====================================
model = Seq2seq(vocab_size, wordvec_size, hidden_size)
# model = PeekySeq2seq(vocab_size, wordvec_size, hidden_size)
# ================================================================
optimizer = Adam()
trainer = Trainer(model, optimizer)
acc_list = []
for epoch in range(max_epoch):
trainer.fit(x_train, t_train, max_epoch=1,
batch_size=batch_size, max_grad=max_grad)
correct_num = 0
for i in range(len(x_test)):
question, correct = x_test[[i]], t_test[[i]]
verbose = i < 10
correct_num += eval_seq2seq(model, question, correct,
id_to_char, verbose, is_reverse)
acc = float(correct_num) / len(x_test)
acc_list.append(acc)
print('검증 정확도 %.3f%%' % (acc * 100))
# 그래프 그리기
x = np.arange(len(acc_list))
plt.plot(x, acc_list, marker='o')
plt.xlabel('에폭')
plt.ylabel('정확도')
plt.ylim(0, 1.0)
plt.show()- 평가 척도로 정답률 사용 (* 정답률 : 에폭마다 테스트 데이터의 문제 중 몇 개를 풀게 하여 올바르게 답했는지 채점)


- seq2seq는 초기에는 정답을 잘 맞히지 못했으나, 학습을 거듭할수록 조금씩 정답에 가까워짐

- 에폭을 거듭함에 따라 정답률이 착실하게 상승
7.4 seq2seq 개선
seq2seq를 세분화하여 학습 '속도' 개선
7.4.1 입력 데이터 반전(Reverse)
개선1

- 입력 데이터의 순서 반전
- 학습 진행이 빨라져서 결과적으로 최종 정확도가 좋아짐

- 정답률을 높여줌, 학습 진행 개선
왜 입력 데이터 반전으로 학습 진행이 빨라지고 정확도가 향상되는가?
- 기울기 전파가 원활해지기 때문
ex) 나는 고양이로소이다 - I am a cat
- 나 - I 로의 변환을 위해서는 네 단계 분량의 LSTM 계층 거쳐야 함
- 역전파 시 I로부터 전해지는 기울기가 나에 도달하기까지, 먼 거리만큼 영향을 더 받음
- 입력문을 반전하면(이다 로소 고양이 는) 나와 I는 바로 옆이 되어 기울기 직접 전해짐
- 입력 문장의 첫 부분에서는 반전 덕분에 대응하는 변환 후 단어와 가까움
- 기울기가 더 잘 전해져서 학습 효율이 좋아짐
- 다만, 입력 데이터를 반전해도 단어 사이의 '평균'적인 거리는 그대로
7.4.2 엿보기(Peeky)
개선2

인코딩된 정보를 Decoder의 다른 계층에도 전해주는 기법
- Encoder는 입력 문장(문제 문장)을 고정 길이 벡터 h로 변환
- h 안에는 Decoder에게 필요한 정보가 모두 담김
- h가 Decoder에게 유일한 정보, 그러나 최초 시각의 LSTM 게층만이 벡터 h 이용
→ 중요한 정보가 담긴 Encoder의 출력 h를 Decoder의 다른 계층에도 전해줌

- 모든 시각의 Affine 계층과 LSTM 계층에 Encoder의 출력 h를 전함
- 하나의 LSTM만이 소유하던 중요 정보 h를 여러 계층(이 예에서 총 8개 계층)이 공유
ex) 집단 지성에 비유 : 중요한 사람을 한 사람의 독점이 아닌 많은 사람과 공유 = 올바른 결정

- LSTM 계층과 Affine 계층에 입력되는 벡터 2개씩이 됨 = 실제로는 두 벡터가 연결(concatenate)
- concat 노드 : 두 벡터를 연결
class PeekyDecoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(H + D, 4 * H) / np.sqrt(H + D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H + H, V) / np.sqrt(H + H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += layer.params
self.grads += layer.grads
self.cache = None
def forward(self, xs, h):
N, T = xs.shape
N, H = h.shape
self.lstm.set_state(h)
out = self.embed.forward(xs)
hs = np.repeat(h, T, axis=0).reshape(N, T, H)
out = np.concatenate((hs, out), axis=2)
out = self.lstm.forward(out)
out = np.concatenate((hs, out), axis=2)
score = self.affine.forward(out)
self.cache = H
return score
초기화
- LSTM 계층의 가중치와 Affine 계층의 가중치의 형상이 달라짐
순전파
- h를 np.repeat()로 시계열만큼 복제해 hs에 저장
- np.concatenate()를 이용해 hs와 Enbedding 계층의 출력을 연결
- 이를 LSTM 계층에 입력
- Affine 계층에도 hs와 LSTM 계층의 출력을 연결한 것 입력
입력 반전과 엿보기를 적용한 결과

Peeky를 추가로 적용하자 seq2seq의 결과가 월등히 좋아짐
- Reverse : 입력 문장 반전
- Peeky : Encoder의 정보를 널리 퍼지게
=> 만족할 만한 결과
7.5seq2seq를 이용하는 애플리케이션
seq2seq : 한 시계열 데이터를 다른 시계열 데이터로 변환
ex)
- 기계 번역 : 한 언어의 문장을 다른 언어의 문장으로 변환
- 자동 요약 : 긴 문장을 짧게 요약된 문장으로 변환
- 질의응답 : 질문을 응답으로 변환
- 메일 자동 응답 : 받은 메일의 문장을 답변 글로 변환
자연어 외에도 음성, 영상 등에도 이용할 수 있음
7.5.1 챗봇
= 사람과 컴퓨터가 텍스트로 대화를 나누는 프로그램
- '상대의 말'을 '자신의 말'로 변환하는 문제
- 대화의 텍스트 데이터가 준비되면 그것으로 seq2seq 학습

7.5.2 알고리즘 학습
- 고차원적인 파이썬 코리 처리를 수행할 수 있음
- 소스 코드도 문자로 쓰여진 시계열 데이터
- 소스 코드를 그대로 seq2seq에 입력, 원하는 답과 대조하여 학습

7.5.3 이미지 캡셔닝
= 이미지를 문장으로 변환
- Encoder가 LSTM에서 합성곱 신경망(CNN)으로 바뀜
- Decoder는 지금까지 똑같은 신경망을 이용

- 이미지의 인코딩을 CNN이 수행
- CNN의 최종 출력은 특징 맵 (* 특징맵 : 3차원 - 높이, 폭, 채널)
- 이를 Decoder의 LSTM이 처리할 수 있도록 손질
- 특징 맵을 1차원으로 평탄화
- 완전연결인 Affine 계층에서 변환 - 변환된 데이터를 Decoder에 전달
이미지 캡셔닝 수행 예

7.6 정리
- RNN을 이용한 언어 모델은 새로운 문장을 생성할 수 있다.
- 문장을 생성할 때는 하나의 단어(혹은 문자)를 주고 모델의 출력(확률분포)에서 샘플링하는 과정을 반복한다.
- RNN을 2개 조합함으로써 시계열 데이터를 다른 시계열 데이터로 변환할 수 있다.
- seq2seq는 Encoder가 출발어 입력문을 인코딩하고, 인코딩된 정보를 Decoder가 받아 디코딩하여 도착어 출력문을 얻는다.
- 입력문을 반전시키는 기법(Reverse), 도는 인코딩된 정보를 Decoder의 여러 계층에 전달하는 기법(Peeky)은 seq2seq의 정확도 향상에 효과적이다.
- 기계 번역, 챗봇, 이미지 캡셔닝 등 seq2seq는 다양한 애플리케이션에 이용할 수 있다.