[프레임워크 기초] 제2고지. 자연스러운 코드(전편)
11. 가변 길이 인수(순전파 편)
- 지금까지는 함수의 입출력 변수가 하나씩인 경우만 고려
- 가변 길이 입출력을 처리할 수 있도록 확장하자


11.1 Function 클래스 수정
- 가변 길이 입출력을 표현하기 위해 리스트(또는 튜플)에 넣어 처리
- Function 클래스는 지금까지처럼 '하나의 인수'를 받아 '하나의 값'만 반환
- 인수와 반환값의 타입을 리스트로 바꾸고, 필요한 변수들을 이 리스트에 넣음
* NOTE
- 리스트와 튜플 차이는 원소 변경 가능 여부
현재의 Function 클래스
class Function:
def __call__(self, input):
x = input.data # 1
y = self.forward(x) # 2
output = Variable(as_array(y)) # 3
output.set_creator(self) # 4
self.input = input
self.output = output
return output
def forward(self, x):
raise NotImplementedError()
def backward(self, gy):
raise NotImplementedError()
Function의 __call__ 메서드는
- Variable이라는 '상자'에서 실제 데이터를 꺼낸 다음
- forward 메서드에서 구체적인 계산
- 계산 결과를 Variable에 넣고
- 자신이 '창조자'라는 표시
변경된 Function 클래스
class Function:
def __call__(self, unputs):
xs = [x.data for x in inputs]
ys = self.forward(xs)
outputs = [Variable(as_array(y)) for y in ys]
for output in outputs:
output.set_creator(self)
self.inputs = inputs
self.outputs - outputs
return outputs
def forward(self, xs):
raise NotImplementedError()
def backward(self, gys):
raise NotImplementedError()- 인수와 반환값을 리스트로 변경
- 해당 코드에서 리스트 생성시 리스트 내포(list comprehension)를 사용
* NOTE : 리스트 내포
- xs = [x.data for x in inputs] 형태
- inputs 리스트의 각 원소 x에 대해 각각의 데이터(x.data)를 꺼내고, 꺼낸 원소들로 구성된 새로운 리스트 만듦
새로운 Function 클래스를 사용한 구체적인 함수 구현
11.2 Add 클래스 구현
Add 클래스의 forward 메서드 구현
* 주의 : 인수와 반환값이 리스트(또는 튜플)
구현 코드
class Add(Function):
def forward(self, xs):
x0, x1 = xs
y = x0 + x1
return (y,)- Add 클래스의 인수는 변수가 두 개 담긴 리스트
→ x0, x1 = xs 형태로 리스트 xs에서 원소 두 개 꺼냄 - 꺼낸 원소들을 사용해 계산
- return (y,) 형태로 튜플을 반환(괄호 생략해도 됨)
수정한 코드 사용
xs = [Variable(np.array(2)), Variable(np.array(3))]
f = Add()
ys = f(xs)
y = ys[0]
print(y.data)
>>> 5- 순전파에 한해 가변 길이 인수와 반환값에 대응할 수 있음
12. 가변 길이 인수(개선 편)
이전 절에서 개선이 필요
12. 1 첫 번째 개선 : 함수를 사용하기 쉽게

- 현재의 Add 클래스는 인수를 리스트에 모아서 받고 결과는 튜플로 반환
- 개선 후는 리스트나 튜플을 거치지 않고 인수와 결과를 직접 주고 받음
개선 후 코드
class Function:
def __call__(self, *inputs): # 1. 별표를 붙인다
xs = [x.data for x in inputs] # Get data from Variable
ys = self.forward(xs)
outputs = [Variable(as_array(y)) for y in ys] # Wrap data
for output in outputs:
output.set_creator(self)
self.inputs = inputs
self.outputs = outputs
# 2. 리스트의 원소가 하나라면 첫 번째 원소를 반환한다.
return outputs if len(outputs) > 1 else outputs[0]- 2 : outputs에 원소가 하나뿐이면 리스트가 아니라 그 원소만 반환
→ 함수의 반환값이 하나라면 해당 변수 직접 돌려줌 - 1 : 함수를 정의할 때 인수 앞에 별표(*)
→ 리스트를 사용하는 대신 임의 개수의 인수(가변 길이 인수)를 건네 함수를 호출할 수 있음
(*) 사용 예시
- 함수를 '정의'할 때 별표를 붙이면 호출할 때 넘긴 인수들을 별표를 붙인 인수 하나로 모아서 받을 수 있음
def f(*x):
print(x)
f(1, 2, 3)
>>> (1, 2, 3)
f(1, 2, 3, 4, 5, 6)
>>> (1, 2, 3, 4, 5, 6)
x0 = Variable(np.array(2))
x1 = Variable(np.array(3))
f = Add()
y = f(x0, x1)
print(y.data)
>>> 5
12.2 두 번째 개선: 함수를 구현하기 쉽도록
오른쪽 코드가 더 바람직
- 입력도 변수를 직접 받고 결과도 변수를 직접 돌려주는 것

class Function:
def __call__(self, *inputs):
xs = [x.data for x in inputs] # Get data from Variable
ys = self.forward(*xs) # 1. 별표를 붙여 언팩
if not isinstance(ys, tuple): # 2. 튜플이 아닌 경우 추가 지원
ys = (ys,)
outputs = [Variable(as_array(y)) for y in ys] # Wrap data
for output in outputs:
output.set_creator(self)
self.inputs = inputs
self.outputs = outputs
return outputs if len(outputs) > 1 else outputs[0]- 1 : 함수를 '호출'할 때 별표를 붙임 → 리스트 언팩(list unpack)이 이루어짐
* 언팩 : 리스트의 원소를 낱개로 풀어서 전달하는 기법
ex) xs = [x0, x1]일 때, self.forward(*xs) == self.forward(x0, x1) 동일하게 동작 - 2 : ys가 튜플이 아닌 경우 튜플로 변경 → forward 메서는 반환 원소가 하나뿐이라면 해당 원소를 직접 반환
Add 클래스 구현
class Add(Function):
def forward(self, x0, x1):
y = x0 + x1
return y- 순전파 메서드를 def forward(self, x0, x1): 이라고 정의할 수 있음
- 결과는 return y처럼 원소 하나만 반환
12.3 add 함수 구현
add 클래스를 '파이썬 함수'로 사용할 수 있는 코드 추가
def add(x0, x1):
return Add()(x0, x1)
add 함수를 사용한 계산 코드
x0 = Variable(np.array(2))
x1 = Variable(np.array(3))
y = add(x0, x1)
print(y.data)
>>> 5- 해당 절에서 구현한 '덧셈' 뿐만 아니라 '곱셈'과 '나눗셈'도 같은 방식으로 구현 가능
- 여기까지는 가변 길이 인수를 다룰 수 있는 것이 아직 '순전파' 뿐
13. 가변 길이 인수(역전파 편)
13.1 가변 길이 인수에 대응한 Add 클래스의 역전파

- 덧셈의 순전파는 입력 2개, 출력 1개
- 역전파는 그 반대로 입력 1개, 출력 2개
→ 수식으로 확인 : y = x0 + x1 일 때 미분하면 ∂y / ∂x0 = 1, ∂y / ∂x1 = 1
* CAUTION : 다변수 함수
- 입력 변수가 여러 개 함수
- ex) y = x0 + x1의 입력 변수 2개
편미분
- 다변수 함수에서 하나의 입력 변수에만 주목하여(다른 변수는 상수로 취급) 미분하는 것
- 미분 기호로 ∂ 사용
- ex) ∂y / ∂x0 는 x0 이외의 변수를 상수로 생각하고 x0에만 주목하여 미분한다는 뜻
→ 책에서는 편미분 따로 구분하지 않고 '미분'으로 통일하여 호칭 & ∂ 사용
Add 클래스의 역전파 구현
class Add(Function):
def forward(self, x0, x1):
y = x0 + x1
return y
def backward(self, gy):
return gy, gy- 덧셈의 역전파는 출력 쪽에서 전해지는 미분값에 1을 곱한 값이 입력 변수(x0, x1)의 미분
- 즉, 그대로 흘려보내는 것이 덧셈의 역전파
- backward 메서드는 입력 1개, 출력 2개
- 여러 개의 값을 반환하게 하기 위해 역전파 핵심 구현 변경의 필요성
→ Variable 클래스의 backward 메서드 수정
13.2 Variable 클래스 수정
기존의 코드
class Variable:
...
def backward(self):
if self.grad is None:
self.grad = np.ones_like(self.data)
funcs = [self.creator]
while funcs:
f = funcs.pop()
x, y = f.input, f.output # 1. 함수의 입출력을 얻는다.
x.grad = f.backward(y.grad) # 2. backward 메서드를 호출한다.
if x.creator is not None:
funcs.append(x.creator)- 1 : 함수의 입출력 변수 꺼냄
- 2 : 함수의 backward 메서드 호출
- 1에서 함수의 입출력이 하나씩이라고 한정해던 것을 여러 개 변수에 대응하도록 수정
변경된 코드
class Variable:
...
def backward(self):
if self.grad is None:
self.grad = np.ones_like(self.data)
funcs = [self.creator]
while funcs:
f = funcs.pop()
gys = [output.grad for output in f.outputs] # 1
gxs = f.backward(*gys) # 2
if not isinstance(gxs, tuple): # 3
gxs = (gxs,) #
for x, gx in zip(f.inputs, gxs): # 4
x.grad = gx #
if x.creator is not None: #
funcs.append(x.creator) #- 1 : 출력 변수인 outputs에 담겨 있는 미분값들을 리스트에 담음
- 2 : 함수 f의 역전파 호출, f.backward(*gys)처럼 인수에 별표를 붙여 호출하여 리스트 풀어줌(리스트 언팩)
- 3 : gxs가 튜플이 아니라면 튜플로 변환
- 4 : 역전파로 전파되는 미분값을 Variable의 인스턴스 변수 grad에 저장
- gxs와 f.inputs의 각 원소는 서로 대응 관계
- i번째 원소에 대해 f.inputs[i]의 미분값은 gxs[i]에 대응
- zip 함수와 for문을 이용해서 모든 Variable 인스턴스 각각에 알맞은 미분값 설정
* NOTE
- 2, 3은 이전 단계에서 순전파 개선 시 활용한 관례와 동일
- 2 : Add 클래스의 backward 메서드를 호출할 때 인수를 풀어서 전달
- 3 : Add 클래스의 backward 메서드가 튜플이 아닌 해당 원소를 직접 반환할 수 있게 함
13.3 Square 클래스 구현
수정된 코드
class Square(Function):
def forward(self, x):
y = x ** 2
return y
def backward(self, gy):
x = self.inputs[0].data # 수정 전 : x = self.input.data
gx = 2 * x * gy
return gx- Function 클래스의 인스턴스 변수 이름이 단수형 input에서 복수형 inputs로 변경
- 바뀐 변수에서 입력 변수 x를 가져오도록 코드 수정
add, square 함수 테스트 코드 : z = x**2 + y**2 계산
x = Variable(np.array(2.0))
y = Variable(np.array(3.0))
z = add(square(x), square(y))
z.backward()
print(z.data)
print(x.grad)
print(y.grad)- z = add ... 부분에서 z = x**2 + y**2 계산이 이루어짐
- z.backward() 호출하면 미분 계산 자동으로 이루어짐
14. 같은 변수 반복 사용
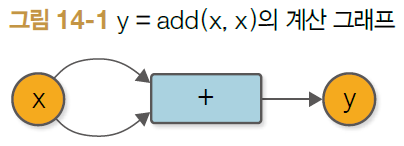
- 문제점 : [그림 14-1]처럼 동일한 변수를 사용하여 덧셈하면 제대로 미분하지 못함
ex) y = add(x, x)
x = Variable(np.array(3.0))
y = add(x, x)
print('y', y.data)
y.backward()
print('x.grad', x.grad)
>>> y 6.0
>>> x.grad 1.0 # 틀림, 제대로된 결과는 y = 2x 이므로 미분값 2여야 함
14.1 문제의 원인
원인 : Variable 클래스의 다음 위치
class Variable:
...
def backward(self):
if self.grad is None:
self.grad = np.ones_like(self.data)
funcs = [self.creator]
while funcs:
f = funcs.pop()
gys = [output.grad for output in f.outputs]
gxs = f.backward(*gys)
if not isinstance(gxs, tuple):
gxs = (gxs,)
for x, gx in zip(f.inputs, gxs):
x.grad = gx # 여기가 실수!
if x.creator is not None:
funcs.append(x.creator)- 현재 구현에서는 출력 쪽에서 전해지는 미분값을 그대로 대입
- 같은 변수를 반복해서 사용하면 전파되는 미분값이 덮어 써짐

앞의 덧셈 예시에서 미분값이 전파되는 그림 형태
14.2 해결책
class Variable:
...
def backward(self):
if self.grad is None:
self.grad = np.ones_like(self.data)
funcs = [self.creator]
while funcs:
f = funcs.pop()
gys = [output.grad for output in f.outputs]
gxs = f.backward(*gys)
if not isinstance(gxs, tuple):
gxs = (gxs,)
for x, gx in zip(f.inputs, gxs):
if x.grad is None: *
x.grad = gx *
else: *
x.grad = x.grad + gx *
if x.creator is not None:
funcs.append(x.creator)- 미분값(grad)을 처음 설정하는 경우에는 지금까지와 똑같이 출력 쪽에서 전해지는 미분값 그대로 대입
- 다음번부터는 전달된 미분값을 '더해'주도록 수정
* CAUTION : x.grad += gx를 쓸 수 없는 이유
(아래 부록 참고)
APPENDIX A. 인플레이스 연산
A.2 복사와 덮어 쓰기
import numpy as np
x = np.array(1)
id(x)
>>> 4370746224
x += x # 덮어쓰기
id(x)
>>> 4370746224
x = x + x # 복사(새로 생성)
id(x)
>>> 4377585368- id(x)의 결과를 통해, x가 메모리에서 덮어 써지는지 새로 생성되는지 알 수 있음
- 인플레이스 연산 : 복사하지 않고 메모리의 값을 직접 덮어 쓰는 연산
→ 누적 대입 연산자 +=를 사용하면 x의 객체 ID가 변하지 않음 = 메모리 위치 동일 = 값만 덮어 씀 - x = x + x를 실행하면 객체 ID 달라짐. 메모리 효율 측면에서는 인플레이스 연산이 바람직
A.3 DeZero의 역전파에서는
문제 ver.
x = Variable(np.array(3))
y = add(x, x)
y.backward()
print('y.grad: {}({})'.format(y.grad, id(y.grad)))
print('x.grad: {}({})'.format(x.grad, id(x.grad)))
>>> y.grad: 2 (4427292384)
>>> x.grad: 2 (4427292384)- x와 y의 미분 결과는 2, ID까지 동일
y는 본래 1이어야 함
같은 ndarray를 참조, y.grad에 잘못된 결과 저장
x.grad = x.grad + gx로 고쳐서 (덮어 쓰지 않고) 복사하도록 함
# 수정한 후 올바른 실행 결과
>>> y.grad: 1 (4755624944)
>>> y.grad: 2 (4755710960)
같은 변수를 반복해서 사용 테스트
# y = x + x
x = Variable(np.array(3.0))
y = add(x, x)
y.backward()
print(x.grad)
>>> 2.0
# y = x + x + x
x = Variable(np.array(3.0)) # or x.cleargrad()
y = add(add(x, x), x)
y.backward()
print(x.grad)
>>> 3.0- 문제 없이 올바른 결과 출력
14.3 미분값 재설정
- 새로운 문제 : 같은 변수를 사용하여 '다른' 계산을 할 경우 계산이 꼬임
문제의 코드
# 첫 번째 계산
x = Variable(np.array(3.0))
y = add(x, x)
y.backward()
print(x.grad)
# 두 번째 계산(같은 x를 사용하여 다른 계산을 수행)
y = add(add(x, x), x)
y.backward()
print(x.grad)
>>> 2.0
>>> 5.0- 앞의 코드는 서로 다른 두 가지 미분 계산 수행
- 메모리 절약을 위해 Variable 인스턴스인 x를 재사용
→ 두 번째 x의 미분값 정답은 3.0
→ 두 번째 x의 미분값에 첫 번째 미분값이 더해져 5.0이라는 잘못된 값 돌려줌
Variable 클래스에 미분값을 초기화하는 cleargrad 메서드 추가
class Variable:
...
def cleargrad(self):
self.grad = None- cleargrad : 미분값을 초기화하는 메서드
- 단순히 self.grad에 None 대입, 여러 가지 미분을 연달아 계산할 때 똑같은 변수 재사용할 수 있음
cleargrad 테스트 코드
# 첫 번째 계산
x = Variable(np.array(3.0))
y = add(x, x)
y.backward()
print(x.grad)
# 두 번째 계산(같은 x를 사용하여 다른 계산을 수행)
x.cleargrad() # 미분값 초기화
y = add(add(x, x), x)
y.backward()
print(x.grad)
>>> 2.0
>>> 3.0- x.cleargrad()를 호출하여 변수에 누적된 미분값 초기화
* CAUTION
- cleargrad 메서드는 최적화 문제를 풀 때 유용
- 최적화 문제 : 함수의 최솟값과 최댓값을 찾는 문제
15. 복잡한 계산 그래프(이론 편)
현재까지 가능한 형태

새로운 목표
→ 지금의 DeZero는 이런 계산의 미분을 제대로 계산 못함

* NOTE : 위상(topology)
- 그래프의 '연결된 형태'
- 목표 : 다양한 위상의 계산 그래프에 대응하자
15.1 역전파의 올바른 순서
비교적 간단하지만 [그림 15-3]도 아직 제대로 미분하지 못함

주목! 계산 중간에 등장하는 변수 a
- 같은 변수를 반복해서 사용하면 역전파 때는 출력 쪽에서 전파되는 미분값을 더해야 함
→ a의 미분(∂y/∂a)을 계산하려면 a의 출력 쪽에서 전파하는 2개의 미분값 필요 - 반드시 지킬 규칙 : 함수 B와 C의 역전파를 모두 끝내서 나서 함수 A를 역전파
→D - B - C - A 또는 D - C - B - A 의 순서로 역전파가 진행되어야 함

15.2 현재의 DeZero
class Variable:
...
def backward(self):
if self.grad is None:
self.grad = np.ones_like(self.data)
funcs = [self.creator]
while funcs:
f = funcs.pop() *
gys = [output.grad for output in f.outputs]
gxs = f.backward(*gys)
if not isinstance(gxs, tuple):
gxs = (gxs,)
for x, gx in zip(f.inputs, gxs):
if x.grad is None:
x.grad = gx
else:
x.grad = x.grad + gx
if x.creator is not None:
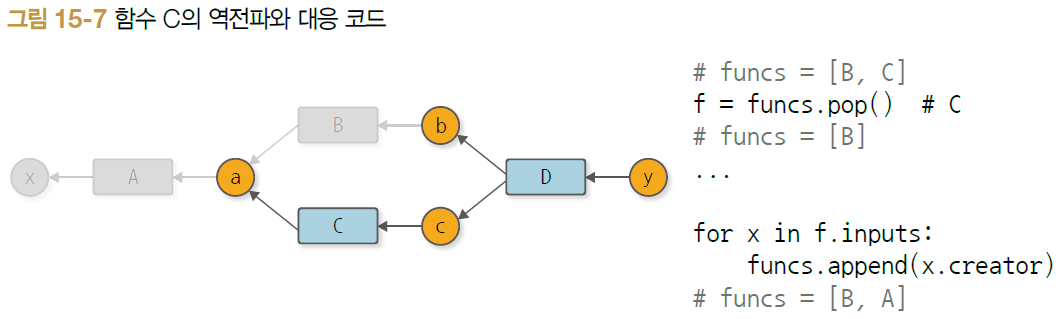
funcs.append(x.creator) *- 문제의 원인 : funcs 리스트
- 처리할 함수의 후보를 funcs 리스트의 끝에 추가(append)
- 처리할 함수를 리스트의 끝에서 꺼냄(pop)
현재 처리 흐름
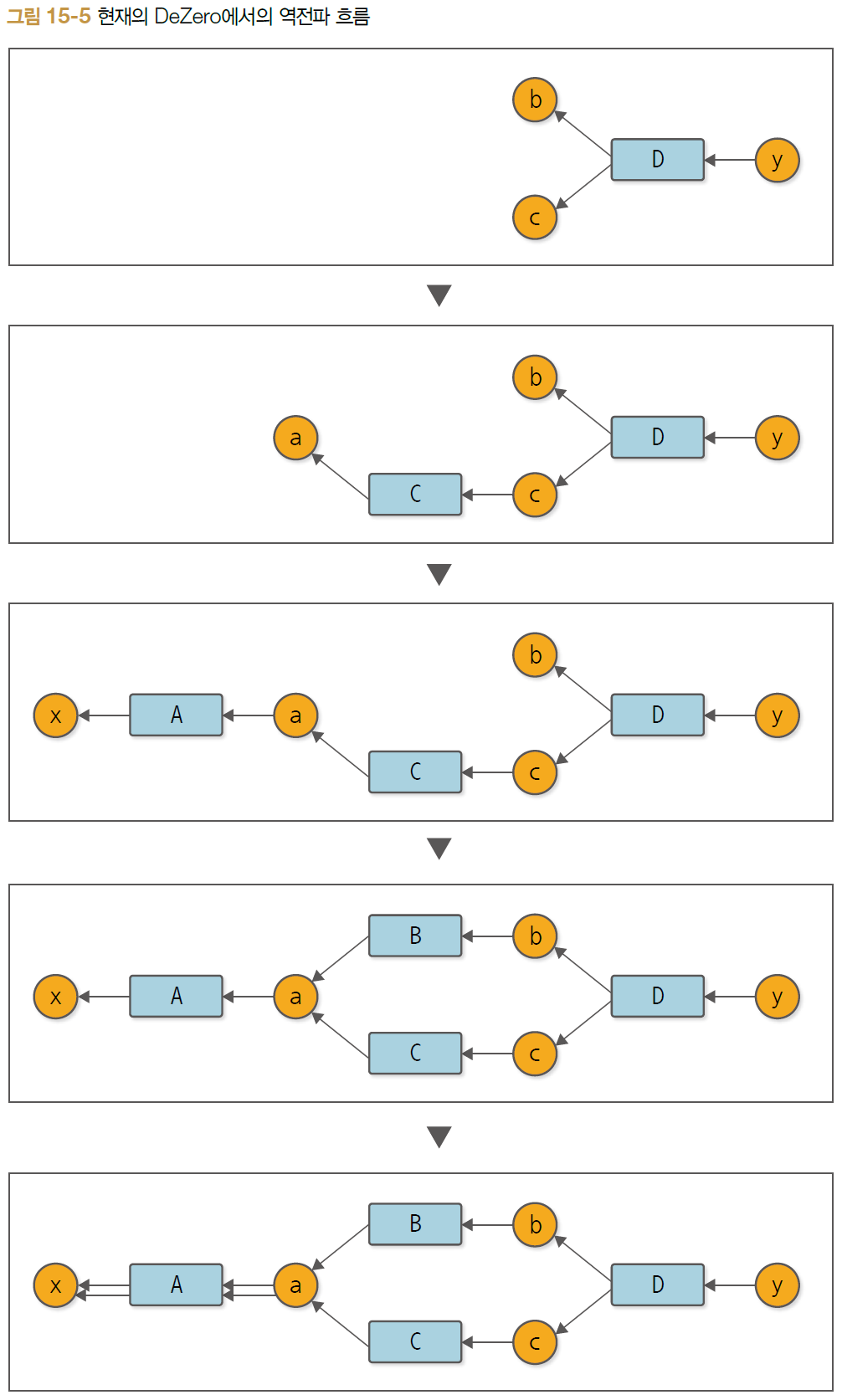
문제점 : 함수의 처리 순서 D - C - A - B - A
- C 다음에 바로 A로 이어짐
- 함수 A의 역전파가 두 번 일어남

- 가장 먼저 funcs 리스트에 D가 추가되어 [D] 상태로 시작
- D가 꺼내지고 B, C가 funcs에 추가됨
- C가 꺼내지고 C의 입력 변수의 창조자인 A가 추가됨
- A가 꺼내짐 (원래는 B 꺼내야 함) ==> 문제
15.3 함수 우선순위
현재는 '마지막' 원소만 꺼내서 사용
이 문제를 해결하기 위해 함수에 '우선순위' 줄 수 있어야 함
우선순위 설정 방법
- 주어진 계산 그래프 '분석'
ex) 위상 정렬 알고리즘 - 함수와 변수의 '세대'를 기록 ★
ex) 창조자-피조물 관계, 부모-자식 관계
세대가 우선순위에 해당
- 역전파 시 세대 수가 큰 쪽부터 처리 : '자식'이 '부모'보다 먼저 처리됨을 보장

16. 복잡한 계산 그래프(구현 편)
15단계의 이론을 코드로 구현
16.1 세대 추가
- Variable 클래스와 Function 클래스에 인스턴스 변수 generation을 추가
Variable 클래스 수정
class Variable:
def __init__(self, data):
if data is not None:
if not isinstance(data, np.ndarray):
raise TypeError('{} is not supported'.format(type(data)))
self.data = data
self.grad = None
self.creator = None
self.generation = 0 # 세대 수를 기록하는 변수
def set_creator(self, func):
self.creator = func
self.generation = func.generation + 1 # 세대를 기록한다(부모 세대 + 1)
...
Function 클래스 수정
class Function:
def __call__(self, *inputs):
xs = [x.data for x in inputs]
ys = self.forward(*xs)
if not isinstance(ys, tuple):
ys = (ys,)
outputs = [Variable(as_array(y)) for y in ys]
self.generation = max([x.generation for x in inputs]) # Function의 generation을 설정
for output in outputs:
output.set_creator(self)
self.inputs = inputs
self.outputs = outputs
return outputs if len(outputs) > 1 else outputs[0]
...

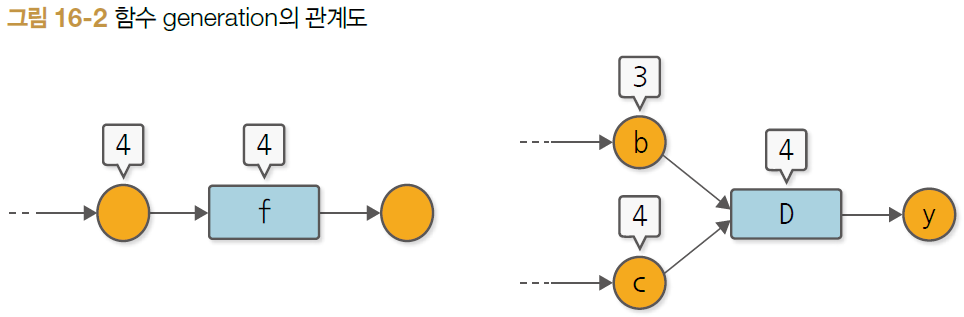
- Function 클래스의 generation은 입력 변수와 같은 값으로 설정
ex) 입력 변수 generation이 4라면 함수의 generation도 4 - 입력 변수가 둘 이상이라면 가장 큰 generation의 수 선택
ex) 입력 변수가 2개고 각각의 generation이 3, 4라면 함수 D의 generaton 4로 설정
16.2 세대 순으로 꺼내기
지금까지 수정을 반영한 일반적인 계산(순전파)
- 모든 변수와 함수에 세대가 설정됨

- A, B, C, D의 세대는 차례로 0, 1, 1, 2
- 세대가 설정되어 있으면 역전파 때 함수를 올바른 순서로 꺼낼 수 있음
→ 함수 A보다 세대가 큰 B와 C를 먼저 꺼내게 됨
* NOTE
- Variable 클래스의 backward 메서드 안에서는 처리할 함수의 후보들을 funcs 리스트에 보관
- funcs에서 세대가 큰 함수부터 꺼내게 하면 올바른 순서로 역전파할 수 있음
generations = [2, 0, 1, 4, 2]
funcs = []
for g in generations:
f = Function() # 더미 함수 클래스
f.generation = g
funcs.append(f)
[f.generation fo f in funcs]
>>> [2, 0, 1, 4, 2]
func.sort(key=lambda x: x.generation) # 리스트 정렬
[f.generationfor f in funcs]
>>> [0, 1, 2, 2, 4]
f = funcs.pop() # 가장 큰 값을 거낸다.
f.generation
>>> 4- sort 메서드를 이용하여 generation을 오름차순으로 정렬
- key=lambda x: x.generation : '리스트의 원소를 x라고 했을 때 x.generation을 키로 사용해 정렬하라'
- 정렬 후 pop 메서드를 써서 리스트의 끝 원소를 꺼내면 자연스럽게 세대가 가장 큰 함수 얻을 수 있음
* CAUTION
- 세대가 가장 큰 함수를 꺼내는 것이 목표
- '우선순위 큐' 이용하면 더 효율적이지만, 이 책에서는 정렬
16.3 Variable 클래스의 backward
Variable 클래스의 backward 메서드 구현
class Variable:
...
def backward(self):
if self.grad is None:
self.grad = np.ones_like(self.data)
funcs = [] *
seen_set = set() *
def add_func(f): *
if f not in seen_set: *
funcs.append(f) *
seen_set.add(f) *
funcs.sort(key=lambda x: x.generation) *
add_func(self.creator) *
while funcs:
f = funcs.pop()
gys = [output.grad for output in f.outputs]
gxs = f.backward(*gys)
if not isinstance(gxs, tuple):
gxs = (gxs,)
for x, gx in zip(f.inputs, gxs):
if x.grad is None:
x.grad = gx
else:
x.grad = x.grad + gx
if x.creator is not None:
add_func(x.creator) *
새로 추가된 add_func 함수
- funcs.appen(f) 대신 호출
- DeZero 함수 리스트를 세대 순으로 정렬하는 역할
- funcs.pop()은 자동으로 세대가 가장 큰 DeZero 함수 꺼냄
- backward 메서드 안의 중첩 함수로 정의
* 참고 : 중첩 함수
- 감싸는 메서드(backward 메서드) 안에서만 이용
- 감싸는 메서드(backward 메서드)에 정의된 변수(funcs과 seen_set)를 사용해야 함
* NOTE : seen_set '집합'
- funcs 리스트에 같은 함수를 중복 추가하는 일 막음
- backward 메서드가 잘못되어 여러 번 불리는 일은 발생하지 않음
16.4 동작 확인
y = (x**2)**2 + (x**2)**2 = 2x^4을 계산하기
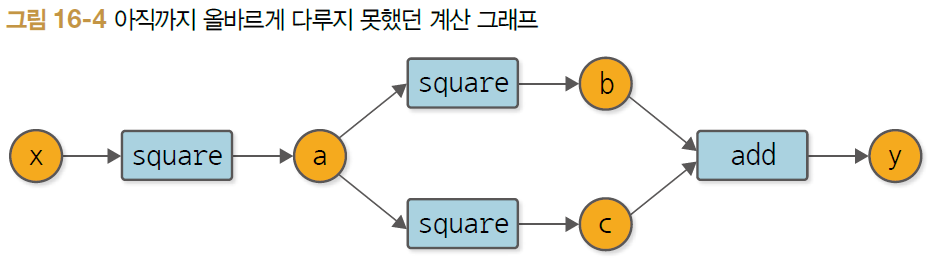
x = Variable(np.array(2.0))
a = square(x)
y = add(square(a), square(a))
y.backward()
print(y.data)
print(x.grad)
>>> 32.0
>>> 64.0- y' = 8x^3 이므로 x = 2.0 일 때 미분은 64.0 ==> 정답!
이제 복잡한 '연결'을 제대로 미분할 수 있음
17. 메모리 관리와 순환 참조
DeZero는 교육 목적이므로 성능을 다소 희생
But, 이번에는 처리 속도와 메모리 사용량에 대해서도 생각해보자
* NOTE : 파이썬 인터프리터
- '파이썬'은 보통 '프로그래밍 언어' 가리킴
- 파이썬 코드를 실행하는 '프로그램'을 지칭할 때도 사용 = ' 파이썬 인터프리터'
- 표준 파이썬 인터프리터는 C 언어로 구현된 CPython
17.1 메모리 관리
- 파이썬은 필요 없어진 객체를 메모리에서 자동으로 삭제
- 그럼에도 코드 제대로 작성하지 않으면 때때로 메모리 누수(memory leak), 메모리 부족(out of memory) 등 문제 발생
- 파이썬(Cpython)은 두 가지 방직으로 메모리 관리
1. 참조 카운트 : 참조(reference)수를 세는 방식
2. GC(Garbage Collection) : 세대(generation)를 기준으로 쓸모없어진 객체를 회수
17.2 참조 카운트 방식의 메모리 관리
참조 카운트
- 구조가 간단하고 속도 빠름
- 모든 객체는 참조 카운트 0인 상태로 생성
- 다른 객체가 참조할 때마다 1씩 증가
- 객체에 대한 참조가 끊길 때마다 1만큼감소하다가 0이 되면 파이썬 인터프리터가 회수
- 객체가 더 이상 필요 없어지면 즉시 메모리에서 삭제
참조 카운트 증가하는 경우
- 대입 연산자를 사용할 때
- 함수에 인수로 전달할 때
- 컨테이너 타입 객체(리스트, 튜플, 클래스 등)에 추가할 때
참조 카운트 구현한 의사 코드
class obj:
pass
def f(x):
print(x)
a = obj() # 변수에 대입 : 참조 카운트 1
f(a) # 함수에 전달 : 함수 안에서는 참조 카운트 2
# 함수 완료 : 빠져나오면 참조 카운트 1
a = None # 대입 해제 : 참조 카운트 0- obj()에 의해 생성된 객체를 a에 대입 → 참조 카운트 1
- f(a)를 호출 → a가 인수로 전달되므로 함수 f의 범위 안에서 참조 카운트 1 증가(총 2)
- 함수 범위 벗어남 → 참조 카운트 다시 1 감소
- a = None → 0이 됨(아무도 참조하지 않는 상태), 해당 객체 메모리에서 삭제
a = obj()
b = obj()
c = obj()
a.b = b
b.c = c
a = b = c = None

- a = b = c = None 줄을 실행하면 오른쪽처럼 변함
- a의 참조 카운트는 0이 되며, 즉시 삭제
- 그 여파로 b의 참조 카운트가 0이 되며, 즉시 삭제
- 이후 c의 참조 카운트도 0이 되며, 즉시 삭제
- ==> 도미노처럼 한꺼번에 삭제
그러나 순환 참조를 해결할 수 없음
17.3 순환 참조
a = obj()
b = obj()
c = obj()
a.b = b
b.c = c
c.a = a
a = b = c = None- c에서 a로의 참조가 추가됨
- 세 개의 객체가 원 모양을 이루며 서로가 서로를 참조 = 순환 참조

- 오른쪽에서 a, b, c의 참조 카운트는 모두 1,
하지만 사용자는 이들 세 객체 중 어느 것에도 접근할 수 없음(불필요한 객체) - 그러나 a = b = c = None을 실행하는 것으로는 순환 참조의 참조 카운트가 0이 되지 않고, 메모리에서 삭제되지 않음
GC
- (복잡하므로 구조 설명 생략)
- 메모리가 부족해지는 시점에 파이썬 인터프리터에 의해 자동으로 호출
- 순환 참조를 올바르게 처리
- 그러나 메모리 해제를 GC에 미루면, 전체 메모리 사용량이 커지는 원인
DeZero의 순환 참조
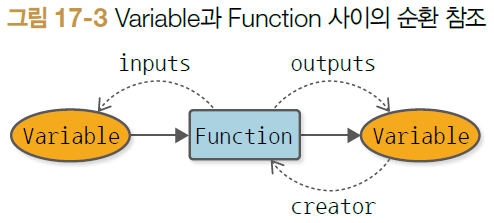
- Function 인스턴스와 Vaariable 인스턴스가 순환 참조 관계 만듦 → 표준 파이썬 모듈인 weakref로 해결
17.4 weakref 모듈
- weakref.ref 함수를 사용하여 약한 참조(weak reference)를 만들 수 있음
- 약한 참조 : 다른 객체를 참조하되, 참조 카운트는 증가시키지 않는 기능
weakref.ref 함수를 사용하는 예
import weakref
iomport numpy as np
a = np.array([1, 2, 3])
b = weakref.ref(a)
b
>>> < weakref at 0x103b7f048; to 'numpy.ndarray' at 0x103b67e90>
b()
>>> [1 2 3]
# 인스턴스 삭제
a = None
b
>>> <weakref at 0x3b7f048; dead>- a 는 일반적인 방식으로 참조, b는 약한 참조
- b를 출력하면 ndarray를 가리키는 약한 참조(weakref)
- cf) 참조된 데이터에 접근하려면 b() 사용
- a = None 실행하면, ndarray 인스턴스는 참조 카운트 방식에 따라 메모리에서 삭제
- b 출력하면 dead, 이것으로 ndarray 인스턴스가 삭제됐음을 알 수 있음
* CAUTION
- 약한 참조 실험 코드는 파이썬 인터프리터 실행을 가정
- IPython, 주피터 노트북 등의 인터프리터는 자체적으로 사용자가 모르는 참조를 추가로 유지
(dead 되지 않음)
weakref 구조를 DeZero에 도입
import weakref *
class Function:
def __call__(self, *inputs):
xs = [x.data for x in inputs]
ys = self.forward(*xs)
if not isinstance(ys, tuple):
ys = (ys,)
outputs = [Variable(as_array(y)) for y in ys]
self.generation = max([x.generation for x in inputs])
for output in outputs:
output.set_creator(self)
self.inputs = inputs
self.outputs = [weakref.ref(output) for output in outputs] *
return outputs if len(outputs) > 1 else outputs[0]
...class Variable:
...
def backward(self):
...
while funcs:
f = funcs.pop()
# 수정 전: gys = [output.grad for output in f.outputs]
gys = [output().grad for output in f.outputs] # output is weakref
...- 인스턴스 변수 self.outputs가 대상을 약한 참조로 가리키도록 변경
- 이로써 DeZero의 순환 참조 문제 해결
17.5 동작 확인
for i in range(10):
x = Variable(np.random.randn(10000)) # 거대한 데이터
y = square(square(square(x))) # 복잡한 계산을 수행한다.

- for문이 두번째 반복될 때 x와 y가 덮어 써짐
- 사용자는 이전의 계산 그래프를 더 이상 참조하지 않게 됨
- 참조 카운트가 0이 되므로 계산 그래프에 사용된 메모리가 바로 삭제
DeZero 순환 참조 문제 해소!
* NOTE
- 파이썬으로 메모리 사용량을 측정하려면 외부 라이브러리인 memory profiler 등을 사용하면 편리
- 메모리 사용량이 전혀 증가하지 않음을 확인할 수 있음