
[전편]
53. GPU 지원
53. 모델 저장 및 읽어오기
54. 드롭아웃과 테스트 모드
55. CNN 메커니즘(1)
56. CNN 메커니즘(2)
-------------------------------------------------------
[후편]
57. conv2d 함수와 pooling 함수
58. 대표적인 CNN(VGG16)
59. RNN을 활용한 시계열 데이터 처리
60. LSTM과 데이터 로더
부록
52. GPU 지원
- 딥러닝 계산은 '행렬의 곱'이 대부분을 차지
- 행렬의 곱은 곱셈과 덧셈으로 구성 → 병렬 계산 가능 → GPU 구현
* CAUTION
GPU에서 실행하기 위해서는 엔비디아(NVIDIA)의 GPU와 쿠파이(CuPy)라는 파이썬 라이브러리가 필요
52.1 쿠파이 설피 및 사용 방법
쿠파이
- GPU를 활용하여 병렬 계산을 해주는 라이브러리
- 장점 : 넘파이와 API가 거의 같음, 넘파이와 거의 같은 코드로 원하는 계산 가능
- 코드는 비슷하지만, 뒤편에서 CPU 아닌 GPU가 계산하는 중 - 넘파이 코드를 'GPU 버전'으로 변환하기는 식은 죽 먹기
=> 넘파이 코드에서 np(넘파이)를 cp(쿠파이)로 치환하면 끝
* CAUTION
- 쿠파이의 API는 넘파이와 거의 같지만 완전히 똑같지는 않음
할 일 : 넘파이를 쿠파이로 바꾸는 것(전환하는 구조 짜는 것)
1. 넘파이와 쿠파이의 다차원 배열을 서로 변환하는 방법
import numpy as np
import cupy as cp
# 넘파이 -> 쿠파이
n = np.array([1, 2, 3])
c = cp.asarray(n) *
assert type(c) == cp.ndarray
# 쿠파이 -> 넘파이
c = cp.array([1, 2, 3])
n = cp.asnumpy(x) *
assert type(n) == np.ndarray
2. cp.get_array_module 함수 : 주어진 데이터에 적합한 모듈을 돌려줌
# x가 넘파이 배열인 ㅕ우
x = np.array([1, 2, 3])
xp = xp.get_array_module(x)
assert xp == np
# x가 쿠파이 배열인 경우
x = cp.array([1, 2, 3])
xp = cp.get_array_module(x)
assert xp == cp- x가 넘파이 또는 쿠파이의 다차원 배열이라면, 해당 배열에 적합한 모듈 돌려줌
- 데이터가 넘파이 배열인지 쿠파이 배열인지 모르더라도 올바른 모듈 가져올 수 있으므로, 둘 모두에 대응 가능
52.2 쿠다 모듈
쿠다(CUDA) : 엔비디아가 제공하는 GPU용 개발 환경
넘파이와 쿠파이 임포트
import numpy as np
gpu_enable = True
try:
import cupy as cp
cupy = cp
except ImportError:
gpu_enable = False
from dezero import Variable- 쿠파이 라이브러리는 필수는 아니므로, 설치되지 않은 경우도 고려
= ImportError가 발생하면 gpu_enable = False로 설정
세 가지 함수 추가
def get_array_module(x):
if isinstance(x, Variable):
x = x.data
if not gpu_enable:
return np
xp = cp.get_array_module(x)
return xp
def as_numpy(x):
if isinstance(x, Variable):
x = x.data
if np.isscalar(x):
return np.array(x)
elif isinstance(x, np.ndarray):
return x
return cp.asnumpy(x)
def as_cupy(x):
if isinstance(x, Variable):
x = x.data
if not gpu_enable:
raise Exception('CuPy cannot be loaded. Install CuPy!')
return cp.asarray(x)- get_array_module(x)
- 인수 x에 대응하는 모듈을 돌려줌
- x는 Variable 또는 ndarray여야 함
- 기본적으로 cp.get_array_module 함수릐 래퍼(wrapper)지만, gpu_enable이 False면 항상 np(numpy)를 돌려줌 - 나머지 두 함수
- 쿠파이/넘파이의 다차원 배열을 서로 변환
52.3 Variable/Layer/DataLoader 클래스 추가 구현
다른 클래스에 GPU 대응 기능 추가
Variable 클래스의 __init__ 메서드 & backward 메서드
...
try:
import cupy
array_types = (np.ndarray, cupy.ndarray) # 1
except ImportError:
array_types = (np.ndarray)
class Variable:
__array_priority__ = 200
def __init__(self, data, name=None):
if data is not None:
if not isinstance(data, array_types): # 1
raise TypeError('{} is not supported'.format(type(data)))
...
def backward(self, retain_grad=False, create_graph=False):
if self.grad is None:
xp = dezero.cuda.get_array_module(self.data) # 2
self.grad = Variable(xp.ones_like(self.data))
...- __init__ 메서드
- 인수 data로 cupy.ndarray가 넘어와도 대응할 수 있도록 수정 - backward 메서드
- 기울기(self.grad)를 자동으로 보완하는 부분 수정
- 데이터(self.data)의 타입에 따라 넘파이 또는 쿠파이 중 하나의 다차원 배열을 생성
- Variable 클래스는 지금까지 인스턴스 변수 data에 넘파이 다차원 배열 보관
- 이 데이터를 GPU 혹은 CPU로 전송해주는 기능 필요
class Variable:
...
def to_cpu(self):
if self.data is not None:
self.data = dezero.cuda.as_numpy(self.data)
def to_gpu(self):
if self.data is not None:
self.data = dezero.cuda.as_cupy(self.data)
- Layer 클래스 : 매개변수 담고 있는 클래스
- 매개변수는 Variable을 상속한 Parameter 클래스로 표현
- Layer 클래스의 매개변수를 CPU 또는 GPU에 전송하는 기능 필요
class Layer:
...
def to_cpu(self):
for param in self.params():
param.to_cpu()
def to_gpu(self):
for param in self.params():
param.to_gpu()
DataLoader 클래스 : 데이터셋을 미니배치로 뽑는 역할
- __next__ 메서드에서 미니배치
- 인스턴스 변수 중 gpu 플래그를 확인하여 쿠파이와 넘파이 중 알맞은 다차원 배열 만들어줌
...
import numpy as np
from dezero import cuda
class DataLoader:
def __init__(self, dataset, batch_size, shuffle=True, gpu=False):
self.dataset = dataset
self.batch_size = batch_size
self.shuffle = shuffle
self.data_size = len(dataset)
self.max_iter = math.ceil(self.data_size / batch_size)
self.gpu = gpu
self.reset()
def __next__(self):
...
xp = cuda.cupy if self.gpu else np
x = xp.array([example[0] for example in batch])
t = xp.array([example[1] for example in batch])
self.iteration += 1
return x, t
def to_cpu(self):
self.gpu = False
def to_gpu(self):
self.gpu = True
52.4 함수 추가 구현
GPU 대응과 관련하여 DeZero 함수 수정 필요
수정 코드
class Sin(Function):
def forward(self, x):
xp = cuda.get_array_module(x) *
y = xp.sin(x) *
return y
def backward(self, gy):
x, = self.inputs
gx = gy * cos(x)
return gx- x가 넘파이면 np.sin, 쿠파이면 cp.sin을 사용하도록
- xp = cuda.get_array_module9x) 코드로 x에 적합한 모듈 꺼냄
- xp는 cp와 np 중 하나가 됨
사칙연산 코드 수정
def as_array(x, array_module=np):
if np.isscalar(x):
return array_module.array(x)
return x
def add(x0, x1):
x1 = as_array(x1, dezero.cuda.get_array_module(x0.data))
return Add()(x0, x1)
def mul(x0, x1):
x1 = as_array(x1, dezero.cuda.get_array_module(x0.data))
return Mul()(x0, x1)
# sub, rsub, div, rdiv도 똑같이 수정- as_array 함수
- 새로운 인수array_module 추가 : numpy 또는 cupy 중 하나의 값 취함, 해당 모듈의 ndarray로 변환 - add, mul ... 함수
- 새로운 as_array 함수를 사용하도록 수정
52.5 GPU로 MNIST 학습하기
DeZero를 GPU에서 실행할 수 있음
MNIST 학습 코드를 GPU에서 실행
if '__file__' in globals():
import os, sys
sys.path.append(os.path.join(os.path.dirname(__file__), '..'))
import time
import dezero
import dezero.functions as F
from dezero import optimizers
from dezero import DataLoader
from dezero.models import MLP
max_epoch = 5
batch_size = 100
train_set = dezero.datasets.MNIST(train=True)
train_loader = DataLoader(train_set, batch_size)
model = MLP((1000, 10))
optimizer = optimizers.SGD().setup(model)
# GPU 모드
if dezero.cuda.gpu_enable: *
train_loader.to_gpu() *
model.to_gpu() *
for epoch in range(max_epoch):
start = time.time()
sum_loss = 0
for x, t in train_loader:
y = model(x)
loss = F.softmax_cross_entropy(y, t)
model.cleargrads()
loss.backward()
optimizer.update()
sum_loss += float(loss.data) * len(t)
elapsed_time = time.time() - start
print('epoch: {}, loss: {:.4f}, time: {:.4f}[sec]'.format(
epoch + 1, sum_loss / len(train_set), elapsed_time))- GPU를 사용할 수 있는 환경에서 DataLoader가 모델 데이터를 GPU로 전송
- 이후의 계산에는 쿠파이 함수 사용
- 빠름~

- GPU : 1에포크 당 1.5초
- CPU : 1에포크 당 8초
- 5배 빠름
53. 모델 저장 및 읽어오기
모델이 가지는 매개변수를 외부 파일로 저장하고 다시 읽어오는 기능
- 학습 중인 모델의 '스냅샷'을 저장
- 이미 학습된 매개변수를 읽어와서 추론만 수행
Dezero의 매개변수는 Parameter 클래스로 구현(Variable 클래스 상속)
- Parameter 데이터는 인스턴스 변수 data에 ndarray 인스턴스로 보관
- 우리가 할 일은 ndarray 인스턴스를 외부 파일로 저장하는 것
* NOTE
- DeZero를 GPU에서 실행하는 경우에는 넘파이의 ndarray 대신 쿠파이의 ndarray 사용
- 쿠파이 텐서를 넘파이 텐서로 변환한 후 외부 파일로 저장
- 여기에서는 넘파이만 고려
53.1 넘파이의 save 함수와 load 함수
np.save 함수
import numpy as np
x = np.array([1, 2, 3])
np.save('test.npy', x)
x = np.load('test.npy')
print(x)
* CAUTION
- 확장자는 .npy로 해주는 것이 좋음
여러 개의 ndarray 인스턴스를 저장하고 읽어오는 방법
x1 = np.array([1, 2, 3])
x2 = np.array([4, 5, 6])
np.savez('test.npz', x1=x1, x2=x2)
arrays = np.load('test.npz')
x1 = arrays['x1']
x2 = arrays['x2']
print(x1)
print(x2)
# 실행 결과
[1 2 3]
[4 5 6]- np.savez('test.npz', x1=x1, x2=x2)
- 여러 개의 ndarray 인스턴스 저장할 수 있음
- x1 = x1과 x2 = x2처럼 '키워드 인수'를 지정할 수 있음
- 데이터를 읽을 때 array['x1']이나 array['x2']처럼 원하는 키워드를 명시하여 해당 데이터만 꺼내올 수 있음
- np.savez 함수로 저장하는 파일의 확장자는 .npz로
앞 코드를 파이썬 딕셔너리를 사용해 수정
x1 = np.array([1, 2, 3])
x2 = np.array([4, 5, 6])
data = {'x1':x1, 'x2':x2} # 키워드를 파이썬 딕셔너리로 묶음
np.savez('test.npz', **data)
arrays = np.load('test.npz')
x1 = arrays['x1']
x2 = arrays['x2']
print(x1)
print(x2)
# 실행 결과
[1 2 3]
[4 5 6]- 딕셔너리 타입의 인수를 전달할 때 **data와 같이 앞에 별표 두 개를 붙여주면 딕셔너리가 자동으로 전개되어 전달
* NOTE
- np.savez 함수에 내용 압축 기능을 추가한 함수 np.savez_compressed
53.2 Layer 클래스의 매개변수를 평평하게
Layer 클래스
- 계층의 구조 표현
- 계층은 Layer 안에 다른 Layer가 들어가는 중첩 형태의 구조 취함
layer = Layer()
l1 = Layer()
l1.p1 = Parameter(np.array(1))
layer.l1 = l1
layer.p2 = Parameter(np.array(2))
layer.p3 = Parameter(np.array(3))
- layer에 또 다른 계층인 l1을 넣음
같은 계층 구조로부터 Parameter를 '하나의 평평한 딕셔너리'로 뽑아내기
- Layer 클래스에 _flatten_params 메서드 추가
params_dict = {}
layer._flatten_params(params_dict)
print(params_dict)
# 실행 결과
{'p2': variable(2), 'l1/p1': variable(1), 'p3': variable(3)}- params_dict = {}로 딕셔너리를 만들어 layer._flatten_params로 건네줌
→ layer에 포함된 매개변수가 '평탄화'되어 나옴 - l1 계층 안의 매개변수 p1은 l1/p1이라는 키로 저장
_flatten_params 메서드
class Layer:
...
def _flatten_params(self, params_dict, parent_key=""):
for name in self._params:
obj = self.__dict__[name]
key = parent_key + '/' + name if parent_key else name
if isinstance(obj, Layer):
obj._flatten_params(params_dict, key)
else:
params_dict[key] = obj- 인수로 딕셔너리 params_dict와 텍스트인 parent_key 받음
- _params에는 'Parameter의 인스턴스 변수 이름' 또는 'Layer의 인스턴스 변수 이름'이 담김
- 실제 객체는 obj = self.__dict__[name]으로 꺼내야 함
- 꺼낸 obj가 Layer라면 obj의 _flatten_params 메서드 호출
- 메서드가 재귀적으로 호출 → 모든 Parameter를 한 줄로 평탄화
53.3 Layer 클래스의 save 함수와 load 함수
class Layer:
...
def save_weights(self, path):
self.to_cpu()
params_dict = {}
self._flatten_params(params_dict)
array_dict = {key: param.data for key, param in params_dict.items()
if param is not None}
try:
np.savez_compressed(path, **array_dict)
except (Exception, KeyboardInterrupt) as e:
if os.path.exists(path):
os.remove(path)
raise
def load_weights(self, path):
npz = np.load(path)
params_dict = {}
self._flatten_params(params_dict)
for key, param in params_dict.items():
param.data = npz[key]- save_weight
- self.to_cpu()를 호출하여 데이터가 메인 메모리에 존재함을(데이터가 넘파이 ndarray임) 보장
- ndarray 인스턴스를 값으로 갖는 딕셔너리 array_dict를 만듦
- np.savez_compressed 함수를 호출하여 데이터를 외부 파일로 저장 - load_weight
- np.load 함수로 데이터를 읽어 들인 후 대응하는 키 데이터를 매개변수로 설정
* CAUTION
- 앞의 코드에서 파일을 저장할 때 try 구문 사용
→ Ctrl+C 등의 키보드 인터럽트에 대비한 보호 코드 - try 구문 덕분에 저장 도중 인터럽트가 발생하면 파일은 삭제
- 불완전한 상태의 파일이 만들어지는 일, 나중에 그런 파일을 읽어오는 일 사전에 방지
MNIST 학습을 예로 들어 매개변수 저장과 읽기 기능 시험
if '__file__' in globals():
import os, sys
sys.path.append(os.path.join(os.path.dirname(__file__), '..'))
import dezero
import dezero.functions as F
from dezero import optimizers
from dezero import DataLoader
from dezero.models import MLP
max_epoch = 3
batch_size = 100
train_set = dezero.datasets.MNIST(train=True)
train_loader = DataLoader(train_set, batch_size)
model = MLP((1000, 10))
optimizer = optimizers.SGD().setup(model)
# 매개변수 읽기
if os.path.exists('my_mlp.npz'): *
model.load_weights('my_mlp.npz') * # 2
for epoch in range(max_epoch):
sum_loss = 0
for x, t in train_loader:
y = model(x)
loss = F.softmax_cross_entropy(y, t)
model.cleargrads()
loss.backward()
optimizer.update()
sum_loss += float(loss.data) * len(t)
print('epoch: {}, loss: {:.4f}'.format(
epoch + 1, sum_loss / len(train_set)))
model.save_weights('my_mlp.npz') * # 1- 이 코드를 처음 실행하면, 모델의 매개변수를 무작위로 초기화한 상태에서 학습 시작
- 마지막 model.save_weight('my_mlp.npz') 줄에서 학습된 매개변수들 저장 (1)
- 다음번에 실행하면 my_mpl.npz 파일이 존재 → 파일로부터 매개변수들 읽어들임(2)
- 이를 통해 앞서 학습한 매개변숫값이 모델에 설정
54. 드롭아웃과 테스트 모드
신경망 학습에서 과대적합이 자주 문제
원인
- 훈련 데이터가 적음 → 데이터 수 인위적으로 늘리는 '데이터 확장'
- 모델의 표현력이 지나치게 높음 → '가중치 감소', '드롭아웃', '배치 정규화'
54.1 드롭아웃이란
- 뉴런을 임의로 삭제(비활성화)하면서 학습하는 방법
- 학습 시에는 은닉층 뉴런을 무작위로 골라 삭제
- 삭제된 뉴런은 신호를 전송하지 않음 [그림 54-1]

ex) 10개의 뉴런으로 이루어진 층이 있고, 그다음 층에서 드롭아웃 계층을 사용하여 60%의 뉴런을 무작위로 삭제
import numpy as np
dropout_ratio = 0.6
x = np.ones(10)
mask = np.random.rand(10) > dropout_ratio
y = x * mask- mask : 원소가 True or False인 배열
- np.random.rand(10) 코드로 0.0 ~ 1.0 사이의 값을 임의로 10개 생성
- 0.6과 비교하여 dropout_ratio보다 큰 원소는 True, 그렇지 않은 원소는 False로 반환
- 이 mask는 False의 비율이 평균적으로 60%rk elhf rjt - y = x * mask 실행
- mask에서 값이 False인 원소에 대응하는 x의 원소를 0으로 설정(삭제)
- 결과적으로 매회 평균 4개의 뉴런만이 출력을 다음 층으로 전달
드롭아웃 계층은 학습 시 데이터를 흘려보낼 때마다 이와 같은 선별적 비활성화 수행
* NOTE : 앙상블 학습
- 여러 모델을 개별적으로 학습시킨 후 추론 시 모든 모델의 출력을 평균 내는 방법
- 신경망을 예로, 다섯 개의 동일한(유사한) 구조의 신경망을 준비하고, 각각을 독립적으로 학습
- 다음 테스트할 때는 다섯 신경망이 출력한 값들의 평균을 '결과'로 냄 - 인식 정확도를 몇 % 정도 향상시킬 수 있음이 실험적으로 알려짐
- 앙상블 학습은 드롭아웃과 가까운 관계
- 드롭아웃은 학습 시 뉴런을 임의로 삭제하는데, 이를 매번 다른 모델을 학습하고 있다고 해석할 수 있음
- 즉, 드롭아웃은 앙상블 학습과 같은 효과를 신경망 하나에서 가상으로 시뮬레이션한다고 간주
테스트 코드
- 모든 뉴런을 사용하면서도 앙상블 학습처럼 동작하게끔 '흉내'
- 모든 뉴런을 써서 출력을 계산, 그 결과를 '약화'
- 약화하는 비율은 학습 시에 살아남은 뉴런의 비율
# 학습 시
mask = np.random.rand(*x.shape) > dropout_ratio
y = x * mask
# 테스트 시
scale = 1 - dropout_ratio # 학습 시에 살아남은 뉴런의 비율
y = x * scale- 테스트 시의 비율을 조절
- 예시에서는 학습 시에 평균 40%의 뉴런이 생존
- 테스트할 때는 모든 뉴런을 사용해 계산한 출력에 0.4 곱함
- 학습 시와 테스트 시의 비율을 일치
→ 여기까지 '일반적인 드롭아웃' = '다이렉트 드롭아웃'
54.2 역 드롭아웃
- 스케일 맞추기를 '학습할 때' 수행
- 일반적 : 테스트할 때 scale 곱함
- 역 : 학습할 때 미리 뉴런 값에 1/scale 곱, 테스트 때는 아무런 동작도 하지 않음
구현 코드
# 학습 시
scale = 1 - dropout_ratio
mask = np.random.rand(*x.shape) > drop_ratio
y = x * mask / scale
# 테스트 시
y = x원리는 같지만, 나름의 장점
- 테스트 속도가 (살짝) 향상
- dropout_ratio를 동적으로 변경할 수 있음
이런 이점으로 많은 딥러닝 프레임워크에서 역 드롭아웃 방식 채용
54.3 테스트 모드 추가
드롭아웃을 사용하려면 학습 단계인지 테스트 단계인지 구분해야 함
→ 18장 역전파 비활성 모드(with dezero.no_grad():) 방식
구현 코드
class Config:
enable_backprop = True
train = True *
@contextlib.contextmanager
def using_config(name, value):
old_value = getattr(Config, name)
setattr(Config, name, value)
try:
yield
finally:
setattr(Config, name, old_value)
def test_mode(): *
return using_config('train', False) *- Config 클래스에 train이라는 클래스 변수 추가
- train의 값 기본적으로 True
- test_mode 함수 : Config.train이 False로 전환
54.4 드롭아웃 구현
구현 코드
def dropout(x, dropout_ratio=0.5):
x = as_variable(x)
if dezero.Config.train:
xp = cuda.get_array_module(x)
mask = xp.random.rand(*x.shape) > dropout_ratio
scale = xp.array(1.0 - dropout_ratio).astype(x.dtype)
y = x * mask / scale
return y
else:
return x- x는 Variable 인스턴스 또는 ndarray 인스턴스
- 쿠파이의 ndarray 인스턴스인 경우도 고려하여 xp=cuda.get_array_module(x)에서 적절한 모듈 가져옴
사용 코드
if '__file__' in globals():
import os, sys
sys.path.append(os.path.join(os.path.dirname(__file__), '..'))
import numpy as np
from dezero import test_mode
import dezero.functions as F
x = np.ones(5)
print(x)
# 학습 시
y = F.dropout(x)
print(y)
# 테스트 시
with test_mode():
y = F.dropout(x)
print(y)
과대적합이 일어난다 싶으면 적극적으로 드롭아웃 사용!
55. CNN 메커니즘(1)
55.1 CNN 신경망의 구조
합성곱층, 풀링층 등장

- 지금까지 Linear - ReLU 연경이 Conv - ReLU - (Pool) 로 대체
- 출력에 가까워지면 이전과 같은 Linear - ReLU 조합 사용됨
55.2 합성곱 연산
CNN의 합성곱층에서 수행하는 '합성곱 연산' = '필터 연산'


합성곱 연산
- 입력 데이터에 필터 적용
- 입력 데이터에 대해 필터 윈도우를 일정 간격으로 이동시키면서 적용
- 필터와 입력의 해당 원소를 곱하고 총합 구함
- 그 결과를 해당 위치에 저장
- 이 과정을 모든 장소에서 수행하면 합성곱 연산의 출력 얻을 수 있음
* 필터 = 커널
* NOTE
- [그림 55-5] 필터 움직임 가로와 세로 두 방향으로 이동 = '2차원 합성곱층'
- 이미지에서 주로 사용됨
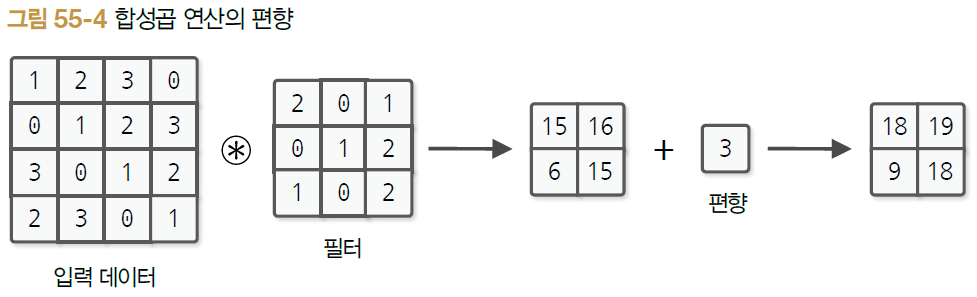
- 편향까지 포함시키면 합성곱 연산의 처리 흐름 위와 같음
- 편향은 필터링 후에 더해줌
- 편향은 하나 뿐 (브로드캐스트되어 더해짐)
55.3 패딩
합성곱층의 주요 처리 전에 입력 데이터 주위에 고정값(가령 0 등)을 채우는 처리
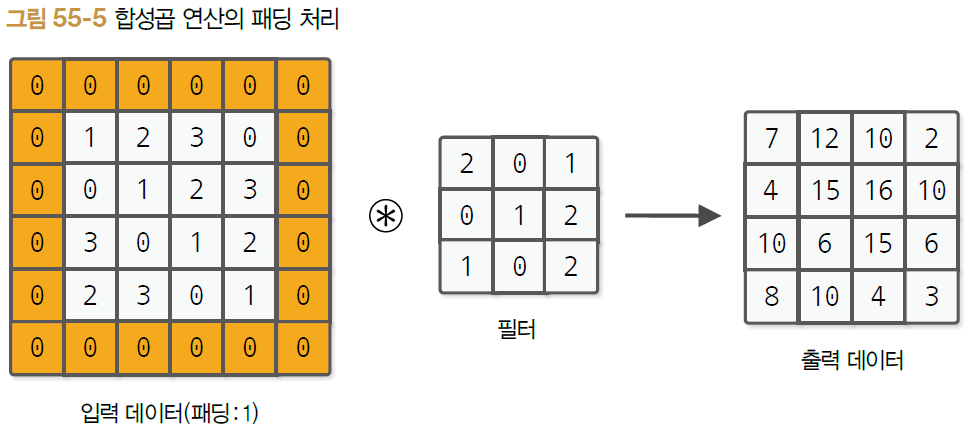
- (4, 4) 형상을 (6, 6) 형상으로 변환
- 패딩은 1, 2, 3 등 임의의 정수로 설정
- 세로 방향 패딩과 가로 방향 패딩 서로 다르게 설정할 수 있음
* NOTE : 패딩을 사용하는 주된 이유
- 출력 크기를 조정하기 위해
- 합성곱 연산을 반복 수행하는 깊은 신경망에서 공간이 축소되어 더 이상의 합성곱 연산이 불가능해질 수 있음
55.2 스트라이드
필터를 적용하는 위치의 간격

- 스트라이드는 필터를 적용하는 간격을 지정
- 세로 방향과 가로 방향 값을 다르게 설정할 수 있음
55.5 출력 크기 계산 방법
- 패딩 크기를 늘리면 출력 데이터 크기 커짐
- 스트라이드를 크게하면 데이터 크기 작아짐
def get_conv_outsize(input_size, kernel_size, stride, pad):
return (input_size + pad * 2 - kernel_size) // stride + 1
H, W = 4, 4 # Input size
KH, KW = 3, 3 # Kernel size
SH, SW = 1, 1 # Kernel stride
PH, PW = 1, 1 # Padding size
OH = get_conv_outsize(H, KH, SH, PH)
OW = get_conv_outsize(W, KW, SW, PW)
print(OH, OW)
# 실행 결과
4 4- 모든 인수 int 타입으로 가정
- input_size부터 순서대로 : 입력 데이터 크기, 커널의 크기, 스트라이드의 크기, 패딩의 크기
56. CNN 메커니즘(2)
56.1 3차원 텐서

- 절차는 2차원 텐서일 때와 동일
- 깊이 방향으로 데이터가 늘어난 것을 제외하면 필터가 움직이는 방법도 계산 방법도 그대로
- 주의 : 입력 데이터와 필터의 '채널' 수를 똑같이 맞춰줘야 함 (ex. rgb)
- 필터의 가로, 세로 크기는 원하는 숫자로 설정할 수 있음
* CAUTION
이전 단계에서와 마찬가지로 가로, 세로의 2차원 위를 움직임 => 2차원 합성곱층으로 분류
56.2 블록으로 생각하기

- 3차원 텐서에 대한 합성곱 연산은 직육면체 블록으로 생각
- 데이터 (채널 C, 높이 H, 너미 W)
- 필터 (채널 C, 높이 KH, 너비 KW)
- 출력은 특징 맵(feature map)이라고 불림
- 특징 맵을 채널 방향으로 여러 장 갖고 싶으면, 다수의 필터(가중치) 사용하면 됨

- OC개의 필터를 개별적으로 적용
- 출력의 특징 맵도 OC개가 생성
- OC개의 맵을 모아 (OC, OH, OW) 형상의 블록 만듦
* NOTE
- 합성곱 연산에서는 필터 수도 고려해야 함
- 필터의 가중치 데이터는 4차원 텐서 (특징맵 채널, 입력 채널, 높이, 너비) 형상으로 관리
합성곱 연산에도 (완전연결계층과 마찬가지로) 편향이 존재

- 편향은 채널당 하나의 값만 가짐
- 편향의 형상 (OC, 1, 1)
- 필터 적용 후의 출력 (OC, OH, OW)
- 편향은 형상이 다르므로 브로드캐스트된 다음 더해짐
56.3 미니배치 처리
- 신경망 학습에서는 여러 개의 입력 데이터를 하나의 단위(미니배치)로 묶어 처리
- 각 층을 흐르는 데이터를 '4차원 텐서'로 취급

- 데이터의 맨 앞에 배치를 위한 차원 추가
- 미니배치 처리에서는 4차원 텐서의 샘플 데이터 각각에 대해 (독립적으로) 독같은 합성곱 연산 수행
56.4 풀링층
풀링은 : 가로, 세로 공간을 작게 만드는 연산
- Max 풀링(최대 풀링) : 최댓값을 취하는 연산
- ex) 2x2 Max 풀링, 스트라이드 2 : 2x2는 대상 영역의 크기 나타냄, 한번에 원소 2개씩 건너뜀
- 일반적으로 풀링 윈도 크기와 스트라이드 크기는 같은 값으로 설정

* NOTE : Average 풀링(평균 풀링)
- Max 풀링 : 대상 영역에서 최댓값
- Average 풀링 : 대상 영역의 평균을 계산
- 이미지 인식 분야에서는 주로 Max 풀링
풀링층의 주요 특징
1. 학습하는 매개변수가 없다
- 풀링은 대상 영역에서 최댓값을 취하는(혹은 평균을 구하는) 처리만 하면 끝이기 때문
2. 채널 수가 변하지 않는다
- 입력 데이터와 출력 데이터의 채널 수가 달라지지 않음
- 계산이 채널마다 독립적으로 이루어지기 때문

3. 미세한 위치 변화에 영향을 덜 받는다
- 입력 데이터의 차이가 크지 않으면 풀링 결과도 크게 달라지지 않음
= 입력 데이터의 미세한 차이에 강간하다

'AI > 딥러닝 프레임워크 기초' 카테고리의 다른 글
| [밑시딥③] 제5고지. DeZero의 도전(편) (2) | 2024.03.07 |
|---|---|
| [밑시딥③] 제4고지. 신경망 만들기(후편) (1) | 2024.03.05 |
| [밑시딥③] 제4고지. 신경망 만들기(전편) (1) | 2024.03.04 |
| [밑시딥③] 제3고지. 고차 미분 계산(후편) (1) | 2024.02.27 |
| [밑시딥③] 제3고지. 고차 미분 계산(전편) (1) | 2024.02.26 |