
7.3 싱글샷 탐지기
- 싱글샷 탐지기(single-shot detector, SSD)는 2016년 웨이 리우의 논문에서 처음 제안
- 당시 속도와 성능 모두 최고 기록 경신
다단계 탐지기
- R-CNN 및 변종을 다단계 탐지기라고 부름
- 다단계 탐지기는 먼저 경계 박스 내 영역의 물체 존재 확신도를 예측
- 경계 박스를 분류기로 넘겨 물체의 클래스를 예측
단일 단계 탐지기
- SSD나 YOLO 등
- 단일 단계 탐지기는 합성곱층에서 위치와 클래스를 한번에 예측
- 이름도 그에 걸맞게 싱글샷(한방)
물체 존재 확신도
- 정답과 경계 박스의 중첩률을 계산해서 예측
- 경계 박스가 정답과 완전히 일치하면 물체 존재 확신도 1
- 두 경계 박스가 전혀 겹치지 않으면 0
- 물체 존재 확신도의 임곗값은 0.5로 설정
- 물체 존재 확신도가 50% 이상이면 해당 영역에는 물체가 있는 확률 높으므로 예측 결과 채용
- 50% 이하면 예측 결과 무시
7.3.1 SSD의 추상적 구조
SSD
- 피드포워드 합성곱 신경망 구조 가짐
- 여러 개의 고정 크기 경계 박스를 생겅하고 각 박스에 클래스별 물체 존재 확신도 부여
- 이후 비최대 억제 알고리즘을 통해 최적 탐지 결과를 제와한 나머지를 배제
SSD 모델의 세 가지 요소
- 특징 맵을 추출하는 기본 신경망
- 고해상도 이미지 분류에 사용되는 사전 학습된 신경망에서 분류기 부분을 제거
- 논문에서는 VGG16을 사용 (다른 모델 사용해도 됨) - 다중 스케일 특징층
- 기본 신경망 뒤에 배치된 일련의 합성곱 필터
- 점진적으로 필터 크기가 감소하여 둘 이상의 배율로 탐지를 시도 - 비최대 억제
- NMS(비최대 억제)를 적용해서 중첩되는 경계 박스를 배제하고 물체별로 경계 박스를 하나만 남김

- Non-maximum suppression : 비최대 억제층
- SSD 모델은 기본 신경망(VGG16), 물체를 탐지하는 추가 합성곱층, 최종 탐지 결과를 선정하는 비최대 억제(NMS)층으로 구성
- 합성곱층 7, 8, 9, 10, 11의 예측 결과가 직접 NMS 층으로 전달되는 구조
- 클래스당 8,732건이 탐지, 이를 NMS 층(비최대 억제층)에 전달해서 물체 하나에 탐지 한 건만 남김
8,732건은 어떻게 나온 숫자일까?
- 탐지 정확도를 향상시키기 위해 각 층에서 출력된 특징 맵이 3x3 합성곱층을 거치며 물체 탐지
- ex) CONV4_3층은 38x38x512 크기의 특징 맵에 3x3 합성곱 연산이 적용
- 각각 클래스 수 + 4개의 출력을 갖는 4개의 경계 박스가 생김
- 물체 클래스의 가짓수가 20+1(배경 포함)이라면 출력되는 경계 박스 수는 38x38x4=5,776개
같은 방법으로 다른 층에서 출력되는 경계 박스 수
- Conv7: 19 × 19 × 6 = 2,166 boxes (6 boxes for each location)
- Conv8_2: 10 × 10 × 6 = 600 boxes (6 boxes for each location)
- Conv9_2: 5 × 5 × 6 = 150 boxes (6 boxes for each location)
- Conv10_2: 3 × 3 × 4 = 36 boxes (4 boxes for each location)
- Conv11_2: 1 × 1 × 4 = 4 boxes (4 boxes for each location)
경계 박스의 수
- 이들을 모두 합하면 5,776 + 2,166 + 600 + 36 + 4 = 8,732개
- 경계 박스를 그대로 출력하기엔 경계 박스 수가 너무 많음
- NMS를 적용해서 출력되는 경계 박스 수를 줄임
- YOLO는 7x7개 위치에서 위치당 2개의 박스를 출력하므로 7x7x2=98개의 박스 출력
* cf : 예측 결과는 어떤 모양일까?
신경망은 각 특징에 대해 다음과 같은 값을 예측
- 경계 박스를 결정하는 값(4개): (x, y, w, h)
- 물체 존재 확신도(1개)
- 각 클래스의 확률을 나타내는 값(C개)
예측 결과는 5+C개 값으로 구성
- ex) 분류 대상 클래스 수가 4개라면 예측 결과 벡터는 다음과 같은 모양
- [x, y, w, h, 물체 존재 확신도, C1, C2, C3, C4]

- 분류 대상 클래스 수가 4개인 문제에 대한 예측 결과를 시각화한 그림
- 합성곱층의 예측 결과는 경계 박스를 결정하는 좌표(x, y, w, h), 물체 존재 확신도, 각 클래스의 확률(C1, C2, C3, C4) 포함
지금부터 SSD의 각 구성 요소를 자세히 살펴보자
7.3.2 기본 신경망
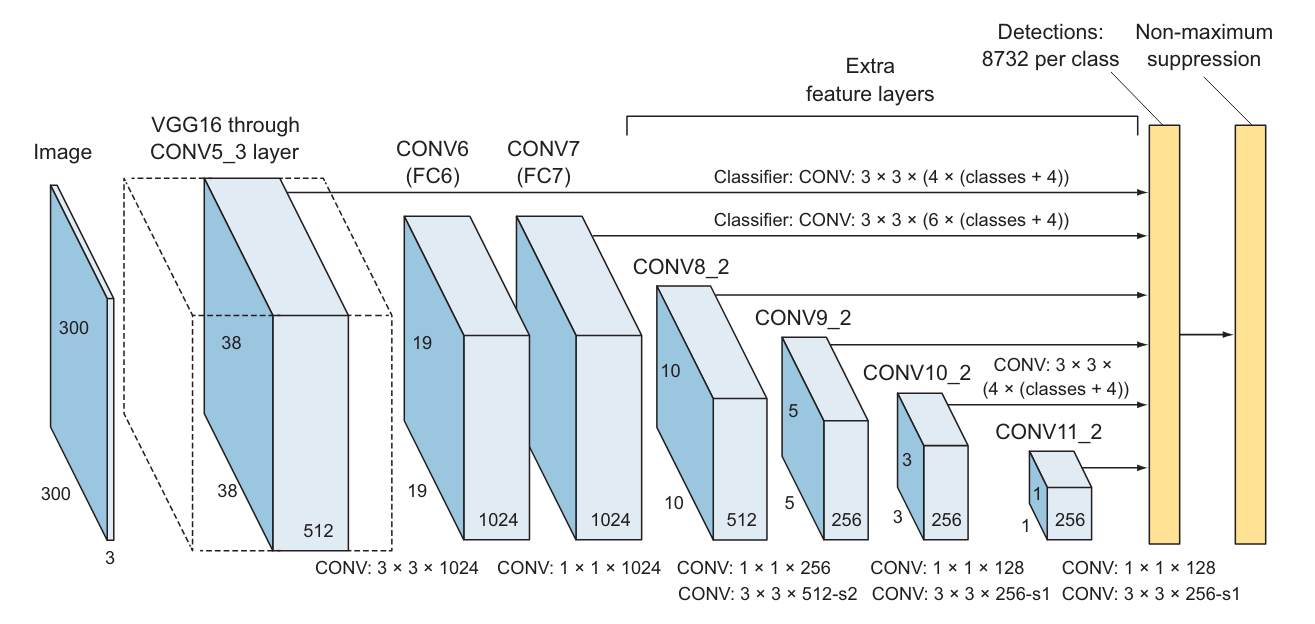
SSD 신경망 구조
- 분류기에 해당하는 전결합층을 제거한 VGG16 신경망 사용
- 채택 이유: 고해상도 이미지 분류에서 높은 성능, 다양한 문제에서 전이학습으로 좋은 성과를 낸 사레가 많음 - 분류기 역할을 하는 전결합층을 제거하고 대신 보조 합성곱층(CONV6 이후 부분)을 추가
- 다양한 배율에서 특징을 추출하고 이어지는 층에서 점진적으로 이미지 크기를 축소해 나가는 효과
SSD에서 사용되는 VGG16 신경망의 단순화된 코드
conv1_1 = Conv2D(64, (3, 3), activation='relu', padding='same')
conv1_2 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv1_1)
pool1 = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same')(conv1_2)
conv2_1 = Conv2D(128, (3, 3), activation='relu', padding='same')(pool1)
conv2_2 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv2_1)
pool2 = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same')(conv2_2)
conv3_1 = Conv2D(256, (3, 3), activation='relu', padding='same')(pool2)
conv3_2 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv3_1)
conv3_3 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv3_2)
pool3 = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same')(conv3_3)
conv4_1 = Conv2D(512, (3, 3), activation='relu', padding='same')(pool3)
conv4_2 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv4_1)
conv4_3 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv4_2)
pool4 = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same')(conv4_3)
conv5_1 = Conv2D(512, (3, 3), activation='relu', padding='same')(pool4)
conv5_2 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv5_1)
conv5_3 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv5_2)
pool5 = MaxPooling2D(pool_size=(3, 3), strides=(1, 1), padding='same')(conv5_3)- 5장 코드와 비교하여 주목해야 할 점
- CONV4_3 층이 이번에도 직접 예측 결과를 출력
- POOL5의 출력이 이어지는 CONV6 층에 입력, CONV6은 새로 추가되는 다중 배열 특징층 중 첫 번째 층
기본 신경망의 예측 과정
- 아래와 같은 이미지를 입력하고, 모든 보트를 포함하는 경계 박스를 예측

- 기본 신경망은 각각의 앵커 박스를 들여다보며 보트의 특징 찾음
- 실선 박스는 보트의 특징을 발견한 영역, 점선 박스는 보트의 특징을 발견하지 못한 영역
- SSD에는 R-CNN의 앵커 박스와 비슷한 역할을 하는 격자가 있음
각 격자점마다 해당 앵커를 중심점으로 하는 경계 박스를 생성
SSD에서는 이들 격자점을 프라이어(prior)라고 함 - SSD에서는 각 경계 박스를 별도의 이미지로 간주
경계 박스마다 '이 경계 박스 안에 보트가 있는가?' = '이 경계 박스 안에서 보트의 특징을 뽑았는가?'를 확인 - 보트의 특징을 포함하는 경계 박스를 발견했다면 해당 박스의 예측 좌표와 사물 분류 결과를 NMS 층으로 전달
- NMS 층은 정답과 중첩률이 가장 높은 경계 박스 하나만 남기고 다른 경계 박스는 배제
* NOTE: VGG16 채택 이유
- 복잡한 이미지 분류 과업에서 높은 성능을 보였기 때문
- 층수가 많은 VGG19나 ResNet으로 기본 신경망을 대체해도 동작에는 문제 없음(속도나 정확도는 하락할 수 있음)
- 모바일넷은 속도와 정확도를 모두 잡을 수 있는 선택
SSD의 두 번재 주요 구성 요소인 다중 스케일 특징층을 살펴보자
7.3.3 다중 스케일 특징층

- 다중 스케일 특징층은 기본 신경망(VGG16) 뒤로 이어지는 일련의 합성곱층
- 합성곱 필터의 크기가 점진적으로 감소하도록 배치되어 다양한 배율로 예측 및 탐지를 수행할 수 있음
다중 스케일 탐지
다중 스케일 특징층의 동작과정 & 합성곱 필터의 크기가 점점 작아지는 이유를 알아보자
- 배경에 포함된 말의 특징은 기본 신경망이 어렵지 않게 찾아냄
- 카메라와 가까이 있는 말은 탐지하지 못함


- 이미지 안에 서로 다른 크기의 말이 존재
- 카메라에서 멀리 떨어진 말은 앵커 박스 안에 포함될 가능성이 높아서 탐지하기 쉬움
- 반면 카메라와 가까운 말은 기본 신경망에서 탐지되지 않을 가능성 높음
- 이를 탐지하려면 큰 범위의 특징을 포착할 수 있도록 다른 스케일의 앵커 박스가 필요
이미지에서 서로 다른 배율로 들어 있는 물체 처리
→ 이미지를 서로 다른 크기로 전처리하고 그 결과를 합쳐서 처리할 방법 필요
- 합성곱 필터의 크기를 달리한 여러 개의 합성곱층을 사용
- 한 신경망 안에서도 이와 같은 효과 얻을 수 있음
- 여러 배율에 해당하는 파라미터를 전체 신경망에서 공유할 수 있음 - CNN은 점진적으로 이미지의 크기를 줄이므로 특징 맵의 크기도 함께 감소
- 줄어든 특징 맵을 큰 크기의 물체를 탐지하는 데 활용
- ex) 4x4 크기의 특징 맵을 커다란 물체를 탐지하는 데 사용

- 큰 물체는 저해상도 특징 맵(오른쪽), 작은 물체는 고해상도 특징 맵(왼쪽)을 이용해서 탐지

- 다중 스케일 특징층은 입력 이미지의 크기를축소해서 서로 다른 크기로 나타난 대상을 탐지
- 이 이미지에서는 프라이어가 이미지를 멀리서 보게 하는 열할을 함 → 가까이에 있는 물체의 특징 탐지 가능
과정을 시각적으로 설명
- 신경망이 말의 전체 모습이 하나의 경계 박스에 들어갈 수 있을 만큼까지 이미지 축소(7.22)
- 다중 스케일 특징층이 이미지의 크기를 적절히 조절해서 경계 박스가 크게 찍힌 말의 모습 전체가 담기도록 함
- 하지만 합성곱층이 실제로 이미지의 크기를 줄이는 것은 아니며 이해를 돕기 위한 표현일 뿐
- 실제로는 합성곱층을 거치며 원래와는 전혀 다른 무작위로 만든 듯한 이미지가 됨
- 하지만 이 이미지에 원래 이미지의 특징이 보존
다중 스케일 특징 맵의 도입 효과를 알아보기 위한 실험
- 다중 스케일 특징 맵을 통해 신경망의 정확도가 크게 개선
- 다중 스케일 특징층 수가 적을 때는 정확도가 감소하는 경우
- 층수가 늘어날수록 정확도 개선
- 출력을 직접 전달하는 다중 스케일 특징층 수가 6개인 경우와 하나인 경우
- 정확도 각각 74.3%와 62.4%로 큰 차이 - 여러 층에서 서로 다른 배율로 경계 박스를 만드는 것이 중요함을 방증

- 다중 스케일 특징 맵을 반영하니 정확도(mAP)가 증가
다중 스케일 특징층의 구조
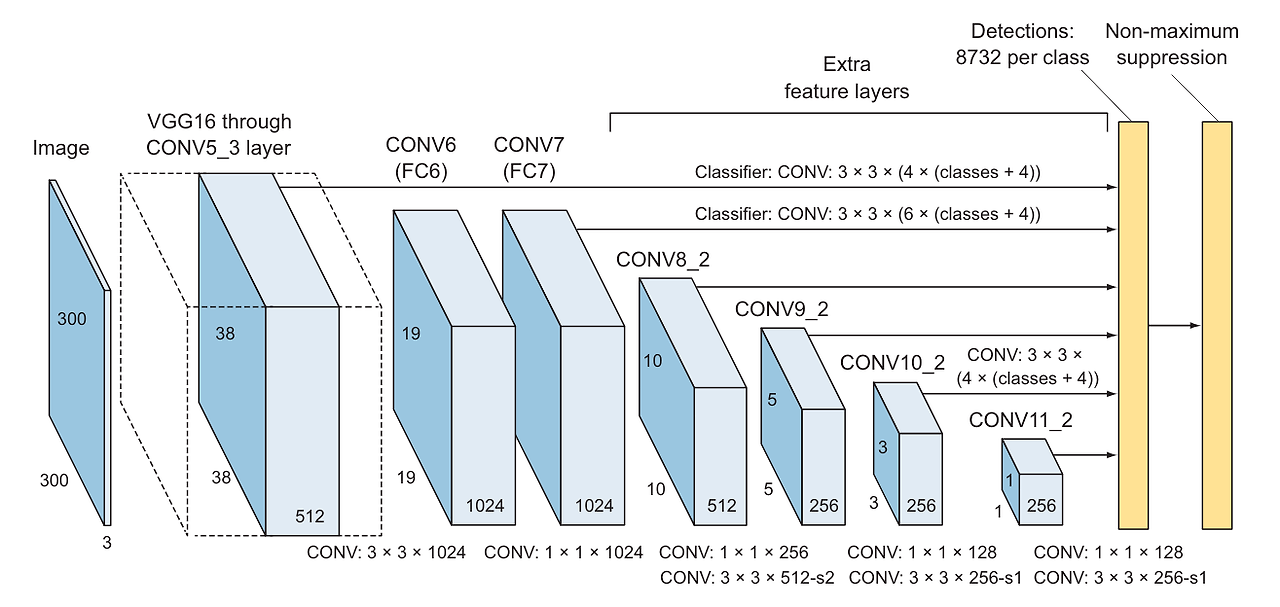
SSD의 연구진은 크기가 점차 감소하는 여섯 층의 합성곱층을 추가
- 층수를 결정하는 과정에서 많은 시행착오
- CONV6은 커널 크기가 3x3, CONV7은 1x1로 서로 독립된 층
- 이와 달리 8번째부터 11번째 층은 커널 크기가 각각 1x1, 3x3인 2개의 합성곱층이 합쳐져 구성된 블록
6번째 ~ 11번째 층을 케라스로 구현한 코드
# conv6 and conv7
conv6 = Conv2D(1024, (3, 3), dilation_rate=(6, 6), activation='relu',
padding='same')(pool5)
conv7 = Conv2D(1024, (1, 1), activation='relu', padding='same')(conv6)
# conv8 block
conv8_1 = Conv2D(256, (1, 1), activation='relu', padding='same')(conv7)
conv8_2 = Conv2D(512, (3, 3), strides=(2, 2), activation='relu',
padding='valid')(conv8_1)
# conv9 block
conv9_1 = Conv2D(128, (1, 1), activation='relu', padding='same')(conv8_2)
conv9_2 = Conv2D(256, (3, 3), strides=(2, 2), activation='relu',
padding='valid')(conv9_1)
# conv10 block
conv10_1 = Conv2D(128, (1, 1), activation='relu', padding='same')(conv9_2)
conv10_2 = Conv2D(256, (3, 3), strides=(1, 1), activation='relu',
padding='valid')(conv10_1)
# conv11 block
conv11_1 = Conv2D(128, (1, 1), activation='relu', padding='same')(conv10_2)
conv11_2 = Conv2D(256, (3, 3), strides=(1, 1), activation='relu',
padding='valid')(conv11_1)
cf) 팽창 합성곱
- 팽창 합성곱(dilated convolution)에는 새로운 파라미터인 팽창률(dilated rate) 도입
팽창률
- 커널과 대상 이미지의 거리
- 팽창률 2를 적용한 3x3 커널은 5x5 커널에서 9개 파라미터만 사용하는 것과 동등
- 행과 열을 하나씩 걸러 제거한 5x5 커널을 상상하면 이해하기 쉬움 - 같은 계산 비용으로 더 넓은 감수 영역의 효과
팽창 합성곱
- 실시간 세그먼테이션 분야에서 널리 사용
- 합성곱 연산을 여러 번 적용하거나 큰 커널을 적용할 계산 자원의 여유가 없는 상황에서 넓은 범위의 감수 영역이 필요할 때 사용하면 좋음
팽창률 2를 적용한 3x3 팽창 합성곱층을 케라스로 구현한 코드
Conv2D(1024, (3, 3), dilation_rate=(2,2), activation='relu', padding='same')
- 팽창률 2를 적용한 3x3 커널은 파라미터 9개만 사용하는 5x5 커널과 동등한 효과를 가짐
마지막으로 SSD의 세 번째 주요 구성 요소인 NMS를 살펴보자
7.3.4 비최대 억제
- 추론 시점에 SSD의 순방향 계산에서 생성되는 많은 수의 경계 박스는 대부분 NMS 알고리즘을 통해 배제
- 확신도 손실이 부여되었거나 중첩률이 임곗값보다 낮은 경계 박스는 폐기
- 상위 N개의 예측만 그대로 남음
- 가장 가능성이 높은 예측만 결과로 출력
NMS는 어떤 방식으로 경계 박스를 배제하는 걸까?
- 확신도(물체 존재 확률)를 기준으로 경계 박스 정렬
- 확신도가 가장 높은 경계 박스부터 그 이전에 본 각각의 경계 박스와 중첩률을 계산
- 그중 현재 경계 박스와 같은 클래스로 분류되었고 일정 중첩률을 초과하는 것이 있었는지 확인
(중첩률의 임곗값은 조정 가능, 논문에서 0.45 사용) - 임곗값보다 중첩률이 높은 경계 박스는 확신도가 더 높은 경계 박스와 지나치게 겹침
→ 같은 물체를 가리킨다고 판단해서 폐기 - 이미지 한 장당 최대 200개의 경계 박스 남김

- 비최대 억제 알고리즘을 이용해서 물체 하나에 경계 박스 하나만 남김
7.4 YOLO
- 2016년 조셉 레드몬이 최초로 제안한 사물 탐지 신경망
- R-CNN과 비슷하게 수년에 걸쳐 개선된 파생 버전 제안
- YOLOv1(2016)
: 일반적인 구조 제안
- 사물 탐지와 클래스 분류를 하나로 통합한 설계 적용
- '통합 실시간 사물 탐지'라고 불림 - YOLOv2(YOLO9000, 2016)
: 설계가 다듬어지고, 경계 박스 제안에 사전 정의된 앵커 박스 도입
- 물체를9,000가지 클래스로 분류
- 이미지넷과 MS COCO 데이터셋을 학습
- 정확도는 mAP 16% 정도로 좋지 않았음
- 추론시 처리 속도는 매우 빠름 - YOLOv3(2018)
: 모델 구조 및 학습 과정이 더욱 더 보완
- 모델의 규모를 크게 키워 mAP 57.9% 달성
- 현재까지 YOLO의 변종 중 가장 뛰어난 성능
YOLO
- 전체 처리 과정이 딥러닝으로 구현된 고속 사물 탐지 모델
- 고속 실시간 사물 탐지에 도전한 초기 시도 중 한 가지
- 정확도는 R-CNN에 미치지 못하지만 빠른 처리 속도
- 사물 탐지 분야에서 인지도 높으며, 실시간 영상 도는 카메라 입력 처리 데모용으로 자주 사용
YOLO 접근법
- R-CNN과 같은 영역 제안 단계 아예 없음
- 대신 입력을 비교적 소수의 격자 형태로 분할하고 분할된 영역을 대상으로 직접 경계 박스와 사물 분류 수행
- 많은 수의 경계 박스 후보가 생성되는데, 이를 다시 NMS를 사용해서 최종 예측 결과로 좁히는 방식

- YOLO의 처리과정은 먼저 이미지를 격자 형태로 분할
- 분활된 각 조각의 물체를 예측
- 이후 NMS를 이용해서 최종 결과를 좁힘
7.4.1 YOLOv3 처리 과정
YOLO 처리 과정
- 이미지를 SxS개의 격자 모양으로 분할
- 정답 경계 박스의 중심이 이 중 어떤 조각에 포함된다면, 해당 조각에서 물체의 존재가 탐지되어야 함
- 다음과 같은 방법으로 분할된 각 조각마다 B개의 경계 박스와 물체 존재 확신도, 물체의 클래스를 예측
- B개의 경계 박스를 결정하는 좌표
- YOLO 역시 경계 박스를 4개의 값을 가진 튜플(bx, by, bw, bh)로 정의
- x와 y는 조각 위치에 대한 오프셋 - 물체 존재 확신도(p0)
- 해당 이미지 조각에 물체가 포함되어 있을 확률
- 물체 존재 확신도는 시그모이드 함수를 거쳐 0과 1 사이의 값으로 변환되어 확률로 다뤄짐
- 물체 존재 확신도 계산 방법

- 물체의 클래스 분류
- 경계 박스에 물체가 포함되었다면, K개 클래스에 대해 물체가 해당 클래스에 속할 확률을 계산
YOLOv3
- YOLOv3에서는 시그모이드 함수 사용
- 이전에는 클래스 분류 확률을 구하기 위해 소프트맥스 함수 사용 - 이유: 소프트맥스 함수를 사용하려면 경계 박스 하나가 항상 하나의 클래스에만 속한다는 가정 필요
- 하지만 그렇지 않은 경우 상당히 많음 - 어떤 문체가 한 가지 클래스에만 속하지는 않음
- 사람과 여자처럼 한 물체가 둘 이상의 클래스를 갖는 데이터셋도 있음 - 다중 레이블을 부여할 수 있는 모델은 정확도가 좀 더 높음
(7.26)각 경계 박스(B)마다 [(경계 박스 좌표), (물체 존재 확신도), (분류 클래스)] 형태의 예측 결과 부여
- 경계 박스의 좌표 4개 값에 물체 존재 확신도와 K개 클래스 각각에 대한 확률을 더한 값
- 예측된 값의 개수는 5B+K개에 이미지 조각의 수 SxS를 곱한 값이 됨
▷ 예측된 값의 개수 = S x S x (5B + K)

- B : 경계 박스의 개수
YOLOv3의 동작 과정
- 입력 이미지를 13 x 13의 격자를 따라 169개의 조각으로 나눔
- 각 조각마다 B개의 경계 박스와 물체 존재 확신도, 분류 클래스가 예측 결과로 나옴
- 이 예제에서는 정답 경계 박스의 중심에 위치한 이미지 조각에서 3개의 예측 결과(B=3)을 얻음
- 하나의 예측은 경계 박스 좌표, 물체 존재 확신도, 분류 클래스로 구성
배율을 달리하며 예측하기
(7.26) 예측 특징 맵에서 왜 경계 박스가 3개나 필요한 걸까?
- SSD의 앵커 개념과 비슷하게 YOLOv3에는 이미지 조각마다 세 가지 다른 배율로 탐지를 시도하는 9개의 앵커 있음
- 탐지층은 스트라이드가 각각 32, 16, 8인 세 가지 특징 맵을 대상으로 탐지 시도
- ex) 입력 이미지의 크기가 416 x 416
- 13 x 13, 26 x 26, 52 x 52 세 가지 격자로 분할된 이미지를 대상으로 탐지 시도
- 13 x 13 격자로 분할된 이미지를 대상으로 하는 층 : 비교적 큰 물체
- 26 x 26 격자로 분할된 이미지를 대상으로 하는 층 : 중간 크기의 물체
- 52 x 52 격자로 분할된 이미지를 대상으로 하는 층 : 작은 크기의 물체 - 서로 다른 크기의 세 가지 특징 맵에서 각각 경계 박스를 하나씩 예측
- 결과적으로 이미지 조각 하나당 3개의 경계 박스가 예측 결과로 나옴(B=3)
- 개를 탐지할 수 있는 경계 박스는 앵커가 정답 경계 박스와 함께 가장 높은 중첩률(IoU)을 가지는 박스

* NOTE : 다양한 배율로 탐지를 시도하는 전략
- YOLOv2의 단점이었던 작은 물체를 탐지하지 못하는 문제 해결에 도움
- 업샘플링은 신경망이 작은 물체를 탐지하는 데 중요한 정보가 되는 세밀한 특지응ㄹ 보존할 수 있게 해줌
YOLOv3는 입력 이미지를 첫 번째 탐지층에 이를 때까지 다운샘플링
- 첫 번째 탐지층은 스트라이드가 32인 특징 맵을 이용해서 탐지를 시도하는 층
- 각 층은 두 배 크기로 업샘플링
- 특징 맵 크기가 동일한 이전 층의 특징 맵을 계속 연접해 나감
- 이 시점에서 스트라이드가 16인 특징 맵을 이용해서 탐지 이뤄짐
- 다시 업샘플링이 이어진 다음 스트라이드가 8인 특징 맵을 이용해서 세 번째 탐지 수행
YOLOv3가 출력하는 경계 박스
입력 이미지의 크기가 416 x 416 일 때
YOLO는 ((52 x 52) + (26 x 26) + (13 x 13)) x 3 = 10,647개의 경계 박스를 예측 결과로 내놓음
10,647개나 되는 경계 박스 예측을 어떻게 해야 하나로 좁힐 수 있을까?
- 물체 존재 확신도가 미리 정한 임곗값을 넘는지를 기준으로 걸러내는 방법
- NMS를 사용해서 같은 물체를 가리키는 여러 개의 경계 박스를 제거하는 방법
- 격자로 나눈 입력 이미지의 한 조각에서 예측한 3개의 경게 박스가 모두 하나의 상자를 탐지했는데,
인접한 조각에서도 같은 물체를 탐지했을 수도 있음.
7.4.2 YOLOv3 구조
YOLO
- 사물 탐지와 클래스 분류를 모두 수행하는 단일 신경망
- 신경망의 구조는 GoogLeNet(인셉션0의 특징 추출기 부분을 참고
- 인셉션 모듈 대신 1x1 축소층과 3x3 합성곱층을 조합한 구조 사용
(레드몬과 파라디는 이 구조를 다크넷_DarkNet 이라고 이름 붙임)

YOLOv2
- darknet-19라는 커스터마이징된 별도의 19층 구조 사용
- 여기에 사물 탐지를 보조하는 11개의 층을 더해 30층 구조 완성
- 30층이나 되는 층수로 인해 YOLOv2는 작은 물체 탐지에 어려움 겪음
- 입력이 층을 거치며 여러 번 다운샘플링되면서 세세한 특징 잃어버림
YOLOv3
- 다크넷 구조의 개선 버전인 darknet-53 채용
- darknet-53: 이미지넷 데이터셋을 학습한 53층 구조의 신경망 - 여기에 사물 탐지를 보조하는 53개의 층을 덧붙여 무려 106층에 달하는 전결합 합성곱 구조 만들어짐
- YOLOv3가 YOLOv2보다 처리 속도 오래 걸리는 이유 - 속도를 희생한 이상으로 정확도 대폭 상승
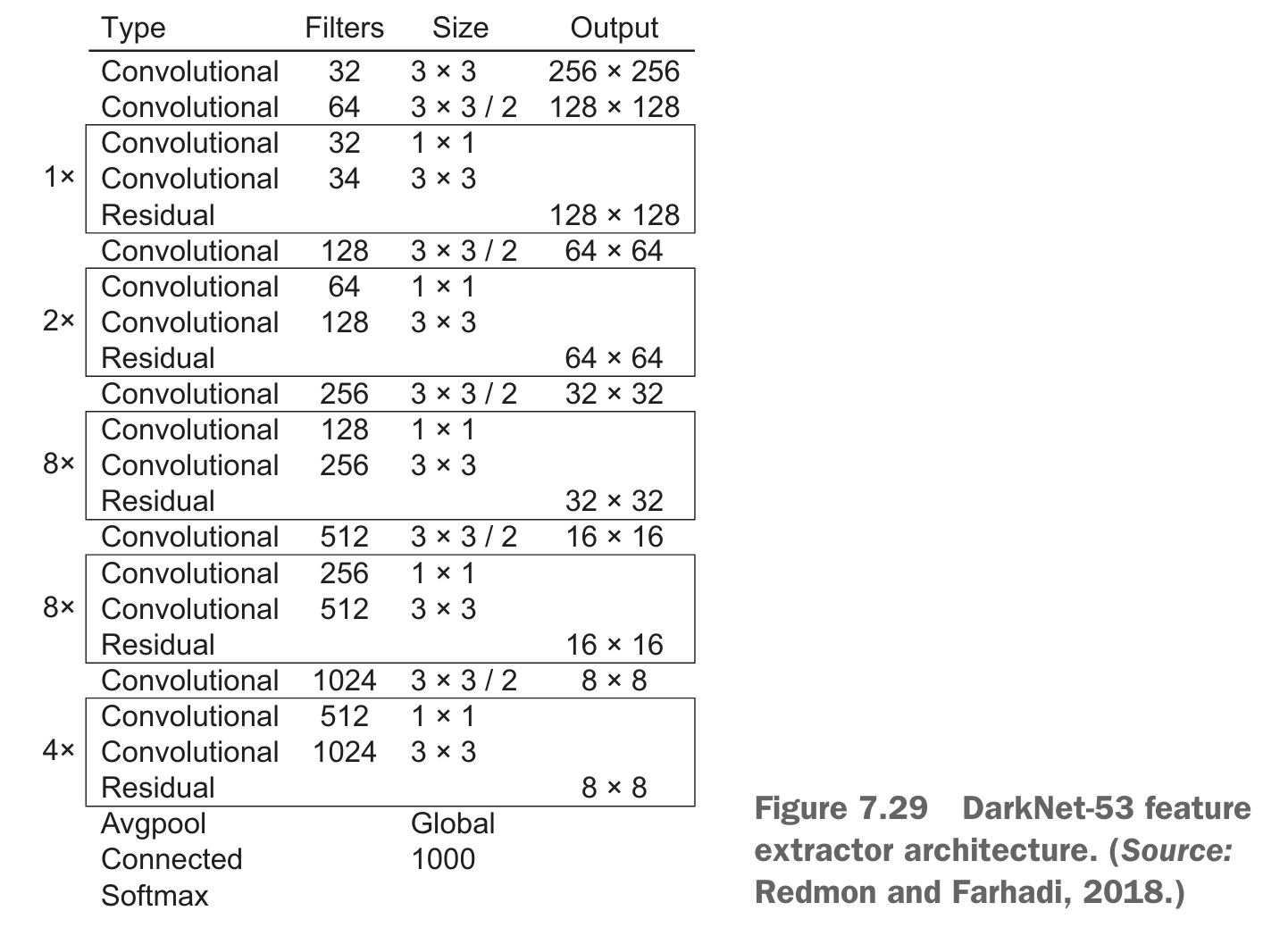
- Convolutional : 합성곱층
- Residual : 잔차 블록
- Avgpool : 평균 풀링
- Global : 전역
- Connected : 전결합층
YOLOv3 전체 구조
YOLOv3는 세 가지 다른 배율로 사물 탐지 수행 (YOLOv3의 구조 참고)
탐지1
- 입력 이미지는 darknet-53 특징 추출기를 지나며 79번 층에 이를 때까지 다운샘플링
- 이 부분에서 신경망이 분기해 첫 번째 탐지가 수행되는 82번 층까지 다시 다운샘플링
- 이 첫 번째 탐지는 13x13 격자로 이미지를 분할하여 큰 물체의 탐지 담당
탐지2
- 다른 쪽 분기는 79번 층의 특징 맵이 두 배로 업샘플링
- 26x26 격자로 분할된 이미지 조각을 형성, 61번 층의 특징 맵과 연접
- 이 시점에서 26x26 격자로 분할된 이미지에서 중간 크기 물체의 탐지를 담당하는 두 번째 탐지 수행
탐지3
- 비슷한 과정이 한 번 더 일어남
- 91번 층의 특징 맵이 몇 차례 업샘플링을 거친 후 36번 층의 특징 맵을 깊이 방향으로 연접
- 106번 층에서 52x52 격자로 분할된 이미지를 대상으로 작은 크기 물체의 탐지를 담당하는 세 번째 탐지 수행

7.5 프로젝트: 자율주행차를 위한 싱글샷 탐지기 학습하기
소규모 SSD 신경망인 SSD7을 구현하는 프로젝트
https://github.com/pierluigiferrari/ssd_keras
데이터셋 형태

7.5.1 1단계: 모델 정의하기
- 이 모델은 합성곱 특징층과 서로 다른 특징층으로부터 특징을 입력받는 합성곱 예측층으로 구성
- build_model 메서드의 시그너처(자세한 설명은 keras_ssd7.py 내부 주석 참고)
def build_model(image_size,
mode='training',
l2_regularization=0.0,
min_scale=0.1,
max_scale=0.9,
scales=None,
aspect_ratios_global=[0.5, 1.0, 2.0],
aspect_ratios_per_layer=None,
two_boxes_for_ar1=True,
clip_boxes=False,
variances=[1.0, 1.0, 1.0, 1.0],
coords='centroids',
normalize_coords=False,
subtract_mean=None,
divide_by_stddev=None,
swap_channels=False,
confidence_thresh=0.01,
iou_threshold=0.45,
top_k=200,
nms_max_output_size=400,
return_predictor_sizes=False)
7.5.2 2단계: 모델 설정하기
모델의 설정 파라미터 지정
- 입력 이미지의 높이, 폭, 채널수 지정
- 설정한 것과 크기나 채널 수가 다른 이미지를 입력해야 하거나 이미지 크기 일정하지 않으면 이미지 변환해야 함

- 입력 이미지의 높이, 폭, 채널 수 지정
- 원하는 값 설정(설정하지 않아도 됨). 이 설정값을 적용하면 픽셀값의 구간이 [-1, 1]로 변환됨
- 클래스 수는 데이터셋에 정의된 클래스 수 입력하면됨
- ex) PASCAL VOC 데이터셋은 20, MS COCO의 클래스 수는 80, 클래스 ID 0은 배경 의미하므로 사용 X
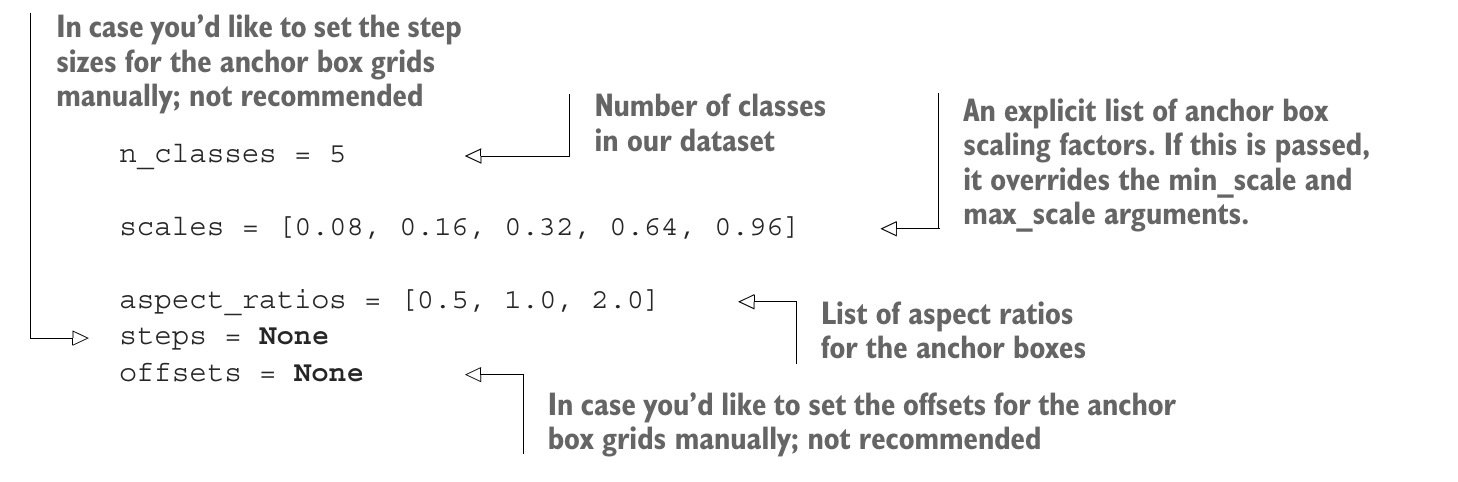
- 앵커 박스 격자의 이미지 내 시작 위치를 직접 설정할 경우는 권장하지 않음
- 데이터셋에 정의된 클래스 수
- 앵커 박스 배율을 명시적으로 기재한 리스트. 이 리스트는 min_scale과 max_scale 인숫값을 오버라이트함
- 앵커 박스의 종횡비
- 앵커 박스 격자의 간격을 직접 설정할 경우는 권장하지 않음
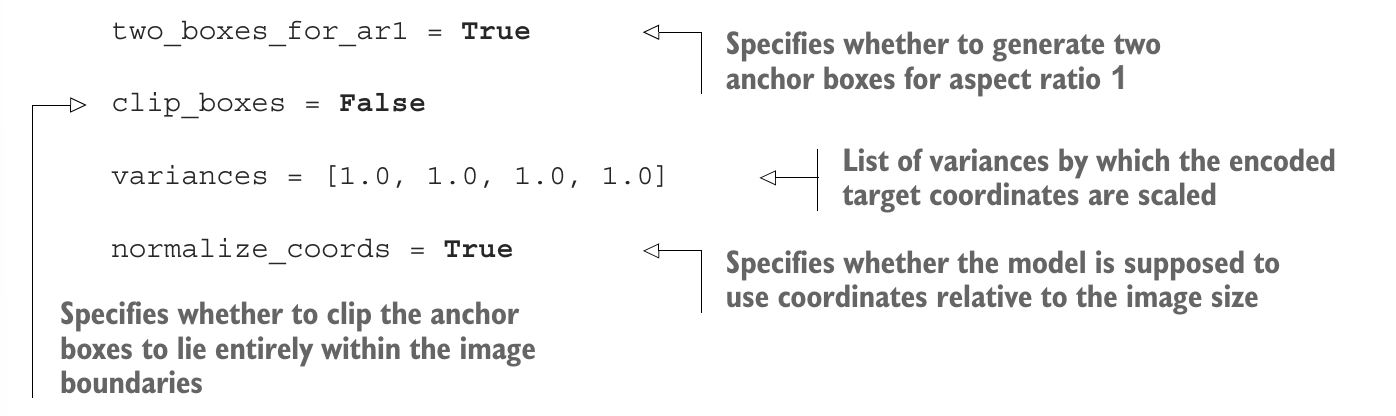
- 종횡비가 1인 앵커 박스를 2개 생성할지 여부
- 인코딩된 목표 좌표의 배율을 조정할 때 적용할 분산값이 기재된 리스트
- 이미지 크기에 대한 상대 좌표 사용 여부
- 이미지 밖으로 빠져나가는 앵커 박스를 절단할지 여부
7.5.3 3단계: 모델 생성하기
- build_model() 메서드를 호출해서 모델을 실제로 생성
model = build_model(image_size=(img_height, img_width, img_channels),
mode='training',
l2_regularization=0.0,
min_scale=0.1,
max_scale=0.9,
scales=None,
aspect_ratios_global=[0.5, 1.0, 2.0],
aspect_ratios_per_layer=None,
two_boxes_for_ar1=True,
clip_boxes=False,
variances=[1.0, 1.0, 1.0, 1.0],
coords='centroids',
normalize_coords=False,
subtract_mean=None,
divide_by_stddev=None,
swap_channels=False,
confidence_thresh=0.01,
iou_threshold=0.45,
top_k=200,
nms_max_output_size=400,
return_predictor_sizes=False)
- 저장된 가중치를 함께 불러오게 됨
model.load_weights('<path/to/model.h5>', by_name=True)
- Adam 최적화 알고리즘과 SSD 손실 함수의 객체를 생성한 다음 모델을 컴파일
adam = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)
ssd_loss = SSDLoss(neg_pos_ratio=3, alpha=1.0)
model.compile(optimizer=adam, loss=ssd_loss.compute_loss)
7.5.4 4단계: 데이터 읽어 들이기
1. DaraGenerator의 인스턴스를 2개 만듦. 이들 객체는 각각 훈련 데이터와 검증 데이터를 읽어들이는 역할.
2. 훈련 데이터 및 검증 데이터의 이미지와 레이블을 읽어 들임
3. 배치 크기 설정
4. 함께 실행할 데이터 강화를 정의
5. 정답 레이블을 SSD 손실 함수가 이해할 수 있는 포맷으로 변환하는 인코더 객체 생성. 이때 생성자 메서드에 앵커 박스를 만드는 데 필요한 입력 이미지의 크기 정보 전달해야 함.
6. 케라스의 fit_generator() 함수에 전달할 제너레이터 객체 생성








7.5.5 5단계: 모델 학습하기
- 최적화 알고리즘, 학습률, 배치 크기는 이미 설정
- 나머지 학습 관련 파라미터 설정
- 체크포인트, 조기 종료, 학습률 감쇠율을 추가로 지정


7.5.6 6단계: 학습 중 손실 함수의 변화 추이 시각화

7.5.7 7단계: 모델을 이용해서 예측하기
- 학습이 끝난 모델을 이용해서 검증 데이터를 대상으로 예측 수행
- 앞서 만든 검증 데이터의 제너레이터 그대로 활용


'AI > 컴퓨터비전 기초' 카테고리의 다른 글
| [CV 기초] 고급 합성곱 신경망 구조(LeNet, AlexNet, VGGNet, GoogLeNet, ResNet) (0) | 2024.04.19 |
|---|---|
| [CV 기초] 딥러닝 프로젝트 시동 걸기와 하이퍼파라미터 튜닝 (1) | 2024.04.17 |
| [CV 기초] R-CNN을 이용한 사물 탐지 (0) | 2024.04.09 |